Spark --【宽依赖和窄依赖】
前言
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,暴力的理解就是stage的划分是按照有没有涉及到shuffle来划分的,没涉及的shuffle的都划分在一个stage里面,这种划分依据就是RDD之间的依赖关系。针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
定义
- 窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
- 相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
宽依赖和窄依赖关系图:

为什么要有宽窄依赖?
1.前面已经说过了stage划分的一个很重要的原因就是有没有涉及到shuffle,如果没涉及到的被划分到一个stage里面。
2.没有涉及shuffle的任务直接运行就可以,这个也就是长提到的pipeline。这种面向的就是窄依赖。
√ 每个分区里的数据都被加载到机器的内存里,我们逐一的调用 map, filter, map 函数到这些分区里,Job 就很好的完成。
√ 更重要的是,由于数据没有转移到别的机器,我们避免了 Network IO 或者 Disk IO. 唯一的任务就是把 map / filter 的运行环境搬到这些机器上运行,这对现代计算机来说,overhead 几乎可以忽略不计。
√ 这种把多个操作合并到一起,在数据上一口气运行的方法在 Spark 里叫 pipeline (其实 pipeline 被广泛应用的很多领域,比如 CPU)。这时候不同就出现了:只有 narrow transformation 才可以进行 pipleline 操作。对于 wide transformation, RDD 转换需要很多分区运算,包括数据在机器间搬动,所以失去了 pipeline 的前提。
√ 总结起来一句话:数据和算是否在一起,计算的性能是不一样的,为了区分,就有了宽依赖和窄依赖。
3.一提到shuffle如果之前对mapreduce有过了解的人都知道,这个对分布式影响巨大,spark也是一步步演变过来的,现在可以说spark2.x以上的shuffle可以认为和经典的mapreduce的shuffle一样了,到现在可以说spark完全比mp有优势了。这之前,在一些场景下spark还是比不过mp的。(这个地方会写一个专门的文章来阐述变化过程)。
4.宽窄依赖如何优化?----得想想
窄依赖对优化的帮助
1.宽依赖往往对应着shuffle操作,需要在运行过程中将同一个父RDD的分区传入到不同的子RDD分区中,中间可能涉及到多个节点之间的数据传输;而窄依赖的每个父RDD的分区只会传入到一个子RDD分区中,通常可以在一个节点内就可以完成了。
2.当RDD分区丢失时(某个节点故障),spark会对数据进行重算。
- 对于窄依赖,由于父RDD的一个分区只对应一个子RDD分区,这样只需要重算和子RDD分区对应的父RDD分区即可,所以这个重算对数据的利用率是100%的;
- 对于宽依赖,重算的父RDD分区对应多个子RDD分区,这样实际上父RDD 中只有一部分的数据是被用于恢复这个丢失的子RDD分区的,另一部分对应子RDD的其它未丢失分区,这就造成了多余的计算;更一般的,宽依赖中子RDD分区通常来自多个父RDD分区,极端情况下,所有的父RDD分区都要进行重新计算。
3.如下图所示,b1分区丢失,则需要重新计算a1,a2和a3,这就产生了冗余计算(a1,a2,a3中对应b2的数据)。
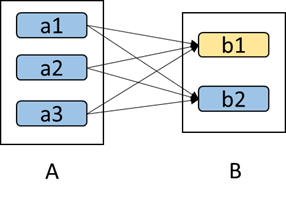
区分这两种依赖很有用。首先,窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;而宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。第二,窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
窄依赖中每个子RDD可能对应多个父RDD,当子RDD丢失时会导致多个父RDD进行重新计算,所以窄依赖不如宽依赖有优势。
而实际上应该深入到分区级别去看待这个问题,而且重算的效用也不在于算的多少,而在于有多少是冗余的计算。窄依赖中需要重算的都是必须的,所以重算不冗余
窄依赖的函数有:map, filter, union, join(父RDD是hash-partitioned ), mapPartitions, mapValues
宽依赖的函数有:groupByKey, join(父RDD不是hash-partitioned ), partitionBy
Spark --【宽依赖和窄依赖】的更多相关文章
- Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系.针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow de ...
- Spark宽依赖、窄依赖
在Spark中,RDD(弹性分布式数据集)存在依赖关系,宽依赖和窄依赖. 宽依赖和窄依赖的区别是RDD之间是否存在shuffle操作. 窄依赖 窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用 ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 大数据开发-从cogroup的实现来看join是宽依赖还是窄依赖
前面一篇文章提到大数据开发-Spark Join原理详解,本文从源码角度来看cogroup 的join实现 1.分析下面的代码 import org.apache.spark.rdd.RDD impo ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- 小记--------spark的宽依赖与窄依赖分析
窄依赖: Narrow Dependency : 一个RDD对它的父RDD,只有简单的一对一的依赖关系.RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的 ...
- 030 RDD Join中宽依赖与窄依赖的判断
1.规律 如果JoinAPI之前被调用的RDD API是宽依赖(存在shuffle), 而且两个join的RDD的分区数量一致,join结果的rdd分区数量也一样,这个时候join api是窄依赖 除 ...
- spark-宽依赖和窄依赖
一.窄依赖(Narrow Dependency,) 即一个RDD,对它的父RDD,只有简单的一对一的依赖关系.也就是说, RDD的每个partition ,仅仅依赖于父RDD中的一个partition ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
随机推荐
- 通过代码注册COM、DLL组件
注册代码如下: C++ Code 1234567891011121314151617181920212223242526272829303132333435363738 // //====== ...
- C++引用具体解释
引用是C++中新出现的.有别于C语言的语法元素之中的一个. 关于引用的说明,网络上也有不少.可是总感觉云遮雾绕,让人印象不深刻. 今天我就来深入解释一下引用.并就一些常见的观点进行说明,最后附带代码演 ...
- 编程之美 set 7 求数组中的最长递增子序列
解法 1. 假设在目标数组 array[] 的前 i 个元素中, 最长递增子序列的长度为 LIS[i] 那么状态转移方程为 LIS[i] = max(1, LIS[k]+1) array[i+1] & ...
- Group By和Order By的总结
1.Group By 语句中:select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中. 例如: select [col1], avg([col2]) ...
- Python 正则表达式分组
被括号括起来的表达式将作为一个整体,也就是一个分组: In [43]: str = "Jan 26 16:41:27 localhost dhclient[1480]: bound to 1 ...
- C语言逻辑运算符
现在假设有这样一种情况,我们的软件比较特殊,要求使用者必须成年,并且成绩大于等于60,该怎么办呢? 或许你会想到使用嵌套的 if 语句,类似下面这样的代码: #include <stdio.h& ...
- jquery如何获取type=hidden的input元素的值?
function setHiddenFields() { var hiddens = $("input:hidden"); $.each(hiddens, function (in ...
- LeetCode 笔记系列16.3 Minimum Window Substring [从O(N*M), O(NlogM)到O(N),人生就是一场不停的战斗]
题目:Given a string S and a string T, find the minimum window in S which will contain all the characte ...
- Struts2数据验证与使用Java代码进行数据验证
Struts2数据验证 使用Java代码进行数据验证 重写ActionSupport的validate()方法 对Action类的中所有请求处理方法都会进行验证! 对Action类的数据属性进行检查, ...
- img元素的alt和title的区别?
alt是图片加载失败时显示在网页上的提示信息: title是鼠标放上面时显示的文字(图片加载失败鼠标放显示的代替文字上时仍然会显示提示信息): 除此之外,alt是img的必要属性,只能用在img.ar ...