mybatis的执行流程 #{}和${} Mysql自增主键返回 resultMap 一对多 多对一配置
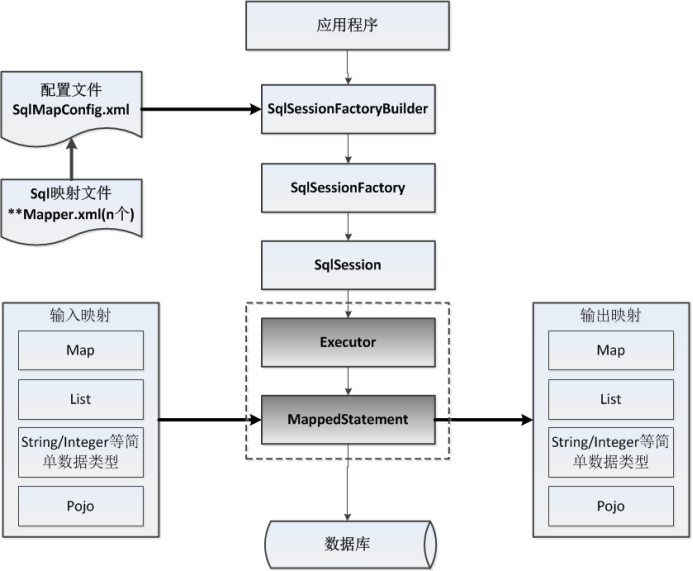
n Mybatis配置
全局配置文件SqlMapConfig.xml,配置了Mybatis的运行环境等信息。
Mapper.xml文件即Sql映射文件,文件中配置了操作数据库的Sql语句。此文件需要在SqlMapConfig.xml中加载。
n 通过Mybatis环境等配置信息构造SqlSessionFactory,即会话工厂。
n 由会话工厂创建SqlSession即会话,操作数据库需要通过SqlSession进行。
n Mybatis底层自定义了Executor执行器接口操作数据库,Executor执行器调用具体的MappedStatement对象执行数据库操作动作。
n MappedStatement也是Mybatis一个底层封装对象,它包装了Mybatis配置信息及Sql映射信息等。Mapper.xml文件中一个Sql对应一个Mapped Statement对象,Sql的id即是Mapped statement的id。
n Executor通过MappedStatement在执Sql前将输入的java对象映射至Sql中,输入参数映射的意思就是Jdbc编程中对PreparedStatement设置参数。Executor通过MappedStatement在执行Sql后将输
出结果映射至Java对象中,输出结果映射过程相当于Jdbc编程中对结果的解析处理过程。
1.1.1.1. #{}和${}
n 关于#{}:
1、#{}等同于PreparedStatement中的占位符?,会自动对传入的字符串数据加一对单引号,可以避免Sql注入。
比如 select * from user where username = #{username} ,传入的username为小张,那么最后打印出来的就是
select * from user where username = ‘小张’
2、#{}可以接收简单类型值或Pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是任意名称。
n 关于${}:
1、${}将传入的数据直接显示生成在Sql中,只是简单的拼接。如:order by ${id},如果传入的值是id,则解析成的Sql为order by id。
如果上面的例子使用${},则成了select * from user where username = 小张
2、${}可以接收简单类型值或Pojo属性值,如果parameterType传输单个简单类型值,${}括号中只能是“value”这个字符串
n 总结:
1、$方式一般用于传入数据库对象,例如传入表名、order by 的字段
2、一般能用#的就别用$.
1.1.1.1. Mysql自增主键返回
查询Mysql自增id的Sql:
SELECT LAST_INSERT_ID()
通过修改UserMapper.xml映射文件,可以将Mysql自增主键返回:
如下添加selectKey 标签
<!-- 保存用户 -->
<insert id="saveUser" parameterType="com.itheima.mybatis.pojo.User">
<!-- selectKey 标签实现主键返回 -->
<!-- keyProperty:主键对应的pojo中的哪一个属性 -->
<!-- order:设置在执行insert语句前执行查询id的sql,孩纸在执行insert语句之后执行查询id的sql -->
<!-- resultType:设置返回的id的类型 -->
<selectKey keyProperty="id" order="AFTER"
resultType="Integer">
SELECT LAST_INSERT_ID()
</selectKey>
INSERT INTO USER
(username,birthday,sex,address) VALUES
(#{username},#{birthday},#{sex},#{address})
</insert>
LAST_INSERT_ID():是Mysql的函数,返回auto_increment自增列新记录id值。
效果如下图所示:

返回的id为22,能够正确的返回id了
1.1.1. 修改用户
根据用户id修改用户名
使用的Sql:
UPDATE USER SET USERNAME = '赵云' WHERE ID= 1
1.1.1.1. 映射文件
在UserMapper.xml配置文件中添加如下内容:
<!-- 更新用户 -->
<update id="updateUserById" parameterType="com.itheima.mybatis.pojo.User">
UPDATE USER SET
USERNAME = #{username} WHERE ID = #{id}
</update>
1.1. Mybatis解决原生jdbc编程的问题
1、 频繁创建、释放数据库连接造成系统资源浪费,影响系统性能。使用数据库连接池技术可以解决此问题。
解决:在SqlMapConfig.xml中配置数据连接池,使用连接池管理数据库连接。
2、 Sql语句写在代码中造成代码不易维护,实际应用中Sql变化的可能较大,Sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与Java代码分离。
3、 向Sql语句传参数麻烦,因为Sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应(硬编码)。
解决:Mybatis自动将Java对象映射至Sql语句,通过statement中的parameterType定义输入参数的类型。
4、 对结果集解析麻烦(查询列硬编码),Sql变化会导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成Pojo对象解析比较方便。
解决:Mybatis自动将Sql执行结果映射至Java对象,通过statement中的resultType定义输出结果的类型。
1.1. Mapper动态代理方式
1.1.1. 开发规范
Mapper动态代理开发方式只需要程序员开发Mapper接口(相当于Dao接口),Mybatis框架会根据接口定义创建接口的动态代理对象,代理对象的方法同Dao接口实现类中的方法。
Mapper接口开发需要遵循以下4个规范:
n Mapper映射文件中的namespace与mapper接口的类路径相同。
n Mapper接口方法名和Mapper映射文件中定义的每个Sql的id相同
n Mapper接口方法的输入参数类型和Mapper映射文件中定义的每个Sql的ParameterType的类型相同
n Mapper接口方法的输出参数类型和Mapper映射文件中定义的每个Sql的resultType的类型相同
1. Mybatis与Hibernate区别
1)Hibernate是一个完全的ORM框架,Mybatis是一个不完全的ORM框架
Hibernate自动化程度高,只需配置OR映射关系,不需要写Sql语句,怎么执行由框架底层控制。
Mybatis虽然将Sql与Java对象做了关系映射,但需要程序员自己写Sql。
2)Hibernate学习门槛高,Mybatis学习门槛较低
Hibernate学习门槛高,精通门槛更高,设计O/R映射和Hibernate调优都需要很强的经验和能力。 一对多 多对多配置麻烦
Mybatis比较容易上手和掌握,重点关注Sql语句即可;
3)Hibernate灵活度差但数据库无关性好,Mybatis灵活度高,但牺牲了数据库无关性
Hibernate不能干预具体Sql的执行,但数据库无关性好,切换不同数据库时只需要切换数据库类型即可。
Mybatis可严格控制Sql的执行性能,灵活度高,适合于软件的需求变化快而且多的软件,但灵活的前提是牺牲了数据库的无关性,如果要实现支持多种数据库的软件则需要自定义多套Sql映射文件,工作量大。
选型原则
总之,满足需求的前提下,只要做出维护性、扩展性好的软件架构都是好架构,框架只有合适的才是最好的。
选型建议
访问量小性能要求不高的内网项目,推荐使用全自动的Hibernate框架,可以提高开发效率。
访问量大性能要求高的内网项目或者互联网项目,推荐使用Mybatis框架
1.1.1. 使用resultMap
由于上边的mapper.xml中sql查询列(user_id)和Order类属性(userId)不一致,所以查询结果不能映射到pojo中。
需要定义resultMap,把orderResultMap将sql查询列(user_id)和Order类属性(userId)对应起来
改造OrderMapper.xml,如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace:命名空间,用于隔离sql,还有一个很重要的作用,Mapper动态代理开发的时候使用,需要指定Mapper的类路径 -->
<mapper namespace="cn.itcast.mybatis.mapper.OrderMapper">
<!-- resultMap最终还是要将结果映射到pojo上,type就是指定映射到哪一个pojo -->
<!-- id:设置ResultMap的id -->
<resultMap type="order" id="orderResultMap">
<!-- 定义主键 ,非常重要。如果是多个字段,则定义多个id -->
<!-- property:主键在pojo中的属性名 -->
<!-- column:主键在数据库中的列名 -->
<id property="id" column="id" />
<!-- 定义普通属性 -->
<result property="userId" column="user_id" />
<result property="number" column="number" />
<result property="createtime" column="createtime" />
<result property="note" column="note" />
</resultMap>
<!-- 查询所有的订单数据 -->
<select id="queryOrderAll" resultMap="orderResultMap">
SELECT id, user_id,
number,
createtime, note FROM `order`
</select>
</mapper>
mybatis中的一对多 多对一关联
1.1.1. 方法二:使用resultMap
使用resultMap,定义专门的resultMap用于映射一对一查询结果。
1.1.1.1. 改造pojo类
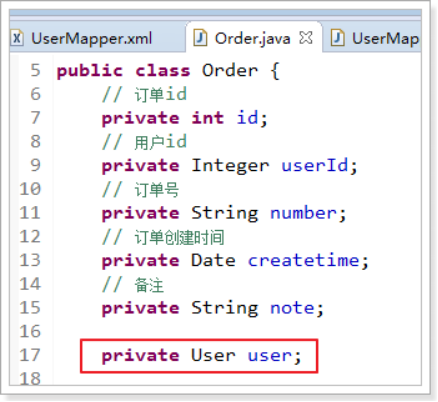
在Order类中加入User属性,user属性中用于存储关联查询的用户信息,因为订单关联查询用户是一对一关系,所以这里使用单个User对象存储关联查询的用户信息。
改造Order如下图:
1.1.1.2. Mapper.xml
这里resultMap指定orderUserResultMap,如下:
<resultMap type="order" id="orderUserResultMap">
<id property="id" column="id" />
<result property="userId" column="user_id" />
<result property="number" column="number" />
<result property="createtime" column="createtime" />
<result property="note" column="note" />
<!-- association :配置一对一属性 -->
<!-- property:order里面的User属性名 --> user
<!-- javaType:属性类型 --> User类的全路径
<association property="user" javaType="user">
<!-- id:声明主键,表示user_id是关联查询对象的唯一标识-->
<id property="id" column="user_id" />
<result property="username" column="username" />
<result property="address" column="address" />
</association>
</resultMap>
<!-- 一对一关联,查询订单,订单内部包含用户属性 -->
<select id="queryOrderUserResultMap" resultMap="orderUserResultMap">
SELECT
o.id,
o.user_id,
o.number,
o.createtime,
o.note,
u.username,
u.address
FROM
`order` o
LEFT JOIN `user` u ON o.user_id = u.id
</select>
1.1.1.3. Mapper接口
编写UserMapper如下图:
1.1. 一对多查询
案例:查询所有用户信息及用户关联的订单信息。
用户信息和订单信息为一对多关系。
sql语句:
SELECT
u.id,
u.username,
u.birthday,
u.sex,
u.address,
o.id oid,
o.number,
o.createtime
FROM
`user` u
LEFT JOIN `order` o ON u.id = o.user_id
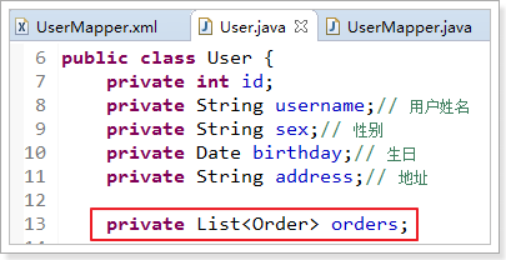
1.1.1. 修改pojo类
在User类中加入List<Order> orders属性,如下图:
1.1.2. Mapper.xml
在UserMapper.xml添加sql,如下:
<resultMap type="user" id="userOrderResultMap">
<id property="id" column="id" />
<result property="username" column="username" />
<result property="birthday" column="birthday" />
<result property="sex" column="sex" />
<result property="address" column="address" />
javaType属性类型
ofType里面的泛型
<!-- 配置一对多的关系 -->
<collection property="orders" javaType="list" ofType="order">
<!-- 配置主键,是关联Order的唯一标识 -->
<id property="id" column="oid" />
<result property="number" column="number" />
<result property="createtime" column="createtime" />
<result property="note" column="note" />
</collection>
</resultMap>
<!-- 一对多关联,查询订单同时查询该用户下的订单 -->
<select id="queryUserOrder" resultMap="userOrderResultMap">
SELECT
u.id,
u.username,
u.birthday,
u.sex,
u.address,
o.id oid,
o.number,
o.createtime,
o.note
FROM
`user` u
LEFT JOIN `order` o ON u.id = o.user_id
</select>
1.1.3. Mapper接口
编写UserMapper接口,如下图:

mybatis的执行流程 #{}和${} Mysql自增主键返回 resultMap 一对多 多对一配置的更多相关文章
- mybatis 添加事物后 无法获取自增主键的问题
检查代码后没发现mapper文件设置自增主键返回的问题,后来检查到,关闭事务后,执行完是可以获取返回的主键的, 我在mysql的客户端里关闭自动提交,发现使用select last_insert_id ...
- mybatis由浅入深day01_4.7根据用户名称模糊查询用户信息_4.8添加用户((非)自增主键返回)
4.7 根据用户名称模糊查询用户信息 4.7.1 映射文件 使用User.xml,添加根据用户名称模糊查询用户信息的sql语句. 4.7.2 程序代码 控制台: 4.8 添加用户 4.8.1 映射文件 ...
- 关于MySQL自增主键的几点问题(上)
前段时间遇到一个InnoDB表自增锁导致的问题,最近刚好有一个同行网友也问到自增锁的疑问,所以抽空系统的总结一下,这两个问题下篇会有阐述. 1. 划分三种插入类型 这里区分一下几种插入数据行的类型,便 ...
- mysql自增主键字段重排
不带外键模式的 mysql 自增主键字段重排 1.备份表结构 create table table_bak like table_name; 2.备份表数据 insert into table_bak ...
- mybatis+oracle 完成插入数据库,并将主键返回的注意事项
mybatis+oracle 完成插入数据库,并将主键返回的注意事项一条插入语句就踩了不少的坑,首先我的建表语句是: create table t_openapi_batch_info( BATCH_ ...
- mysql 自增主键为什么不是连续的?
由于自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,因此索引更紧凑 MyISAM 引擎的自增值保存在数据文件中 nnoDB 引擎的自增值,其实是保存在了内存里,并且到了 MySQL 8.0 ...
- Mysql自增主键ID重新排序方法详解
Mysql数据库表的自增主键ID号乱了,需要重新排列. 原理:删除原有的自增ID,重新建立新的自增ID. 1,删除原有主键: ALTER TABLE `table_name` DROP `id`; 2 ...
- 关于mysql自增主键
对于mysql表(其他数据库没测试过) 如果定义了自增主键,并且手动设置了主键的值,那么当再次自增创建数据的时候,回在设置的主键值的基础上进行自增. 如(id是主键): 起始插入(3,1),而后手动插 ...
- mysql自增主键
MariaDB [test]> create table test1(id int primary key auto_increment,name varchar(20))auto_increm ...
随机推荐
- NOIP模拟题 序列
题目大意 给定长为$n$的序列$A$,定义长为$k$的区间中位数为从小到大排完序后第$\lfloor\frac{k}{2}\rfloor$个数的大小. 每次询问给定$l_1,r_1,l_2,r_2$有 ...
- 51nod 1298 圆与三角形
给出圆的圆心和半径,以及三角形的三个顶点,问圆同三角形是否相交.相交输出"Yes",否则输出"No".(三角形的面积大于0). 输入 第1行:一个数 ...
- 【转】IUSR和IIS_IUSRS
转自:http://blog.chinaunix.net/uid-20344928-id-3306130.html 概述 在早期的IIS版本中,随着IIS的安装,系统会创建一个IUSR_Mac ...
- 【2】基于zookeeper,quartz,rocketMQ实现集群化定时系统
<一>项目结构图 (1)ZK协调分配 ===>集群中的每一个定时服务器与zookeeper交互,由集群中的master节点进行任务划分,并将划分结果分配给集群中的各个服务器节点. = ...
- VUE API 重点
VUE API 重点 生命周期方法 每个组件都有生命周期,是向 ReactJs 学习的. computed 在一个组件声明一个人,人有名,人有姓,输入姓和名.((&--&%--& ...
- 让你的 Nginx 的 RTMP 直播具有统计某频道在线观看用户数量的功能
你的 Nginx 已经有了 RTMP 直播功能的话,如果你还想统计某直播频道当前观看用户量的话,可以加入 with-http_xslt_module 模块.具体步骤如下: 1.查看原来的 ...
- 阿里云ubuntu 创建svn服务器
1.SubVersion服务安装 sudo apt-get install subversion sudo apt-get install libapache2-svn 2.服务器配置 2.1相关用户 ...
- MySQL存储过程中的3种循环,存储过程的基本语法,ORACLE与MYSQL的存储过程/函数的使用区别,退出存储过程方法
在MySQL存储过程的语句中有三个标准的循环方式:WHILE循环,LOOP循环以及REPEAT循环.还有一种非标准的循环方式:GOTO,不过这种循环方式最好别用,很容易引起程序的混乱,在这里就不错具体 ...
- Vue.js:表单
ylbtech-Vue.js:表单 1.返回顶部 1. Vue.js 表单 这节我们为大家介绍 Vue.js 表单上的应用. 你可以用 v-model 指令在表单控件元素上创建双向数据绑定. v-mo ...
- python开发面向对象基础:组合&继承
一,组合 组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合 人类装备了武器类就是组合 1.圆环,将圆类实例后传给圆环类 #!/usr/bin/env python #_*_ ...