爬取实时变化的 WebSocket 数据(转载)
本文转自:https://mp.weixin.qq.com/s/fuS3uDvAWOQBQNetLqzO-g
一、前言
作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据、股市实时数据或币圈实时变化的数据。如下图:
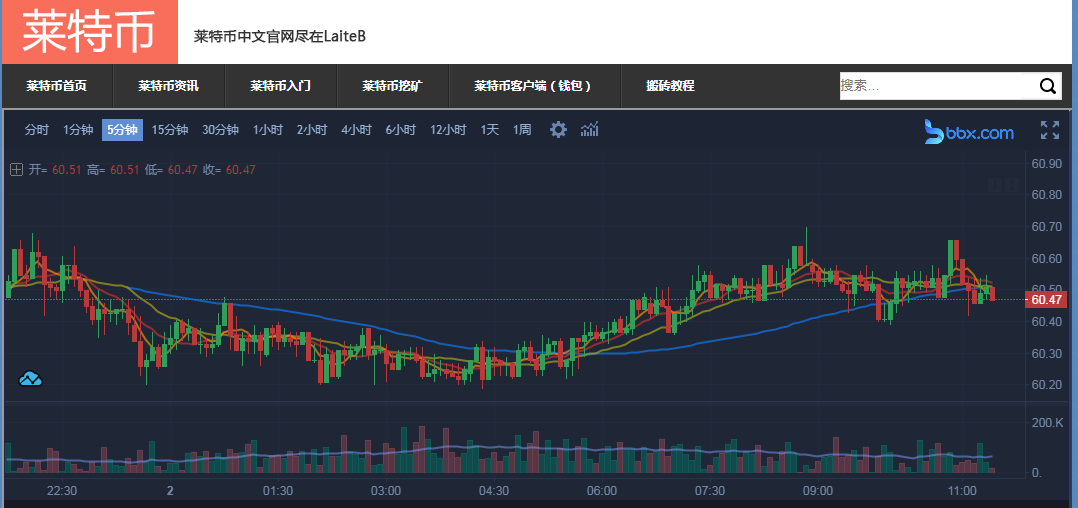
Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSocket 这两种。轮询指的是客户端按照一定时间间隔(如 1 秒)访问服务端接口,从而达到 '实时' 的效果,虽然看起来数据像是实时更新的,但实际上它有一定的时间间隔,并不是真正的实时更新。轮询通常采用 拉 模式,由客户端主动从服务端拉取数据。
WebSocket 采用的是 推 模式,由服务端主动将数据推送给客户端,这种方式是真正的实时更新。
二、什么是 WebSocket
WebSocket是一种在单个TCP连接上进行全双工通信的协议。它使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
WebSocket 优点
较少的控制开销:只需要进行一次握手,携带一次请求头信息即可,后续只传输数据即可,相比 HTTP 每次请求都携带请求头,WebSocket 非常省资源。
更强的实时性:由于服务器可以主动推送消息,这使得延迟变得可以忽略不计,相比 HTTP 轮询的时间间隔,WebSocket 可以在相同的时间内进行多次传输。
二进制支持:WebSocket 支持二进制帧,这意味着传输更节省。
……
爬虫面对 HTTP 和 WebSocket
Python 中的网络请求库非常多,Requests 是最常用的请求库之一,它可以模拟发送网络请求。但是这些请求都是基于 HTTP 协议的。在面对 WebSocket 的时候 Requests 就发挥不料作用了,必须使用能够连接 WebSocket 的库。
三、爬取思路
这里以莱特币官网 http://www.laiteb.com/ 实时数据为例。WebSocket 的握手只发生一次,所以如果需要通过浏览器开发者工具观察网络请求,则需要在打开页面的情况下,打开浏览器开发者工具,定位到 NewWork 选项卡,并输入或刷新当前页面,才能观察到 WebSocket 的握手请求和数据传输情况。这里以 Chrome 浏览器为例:
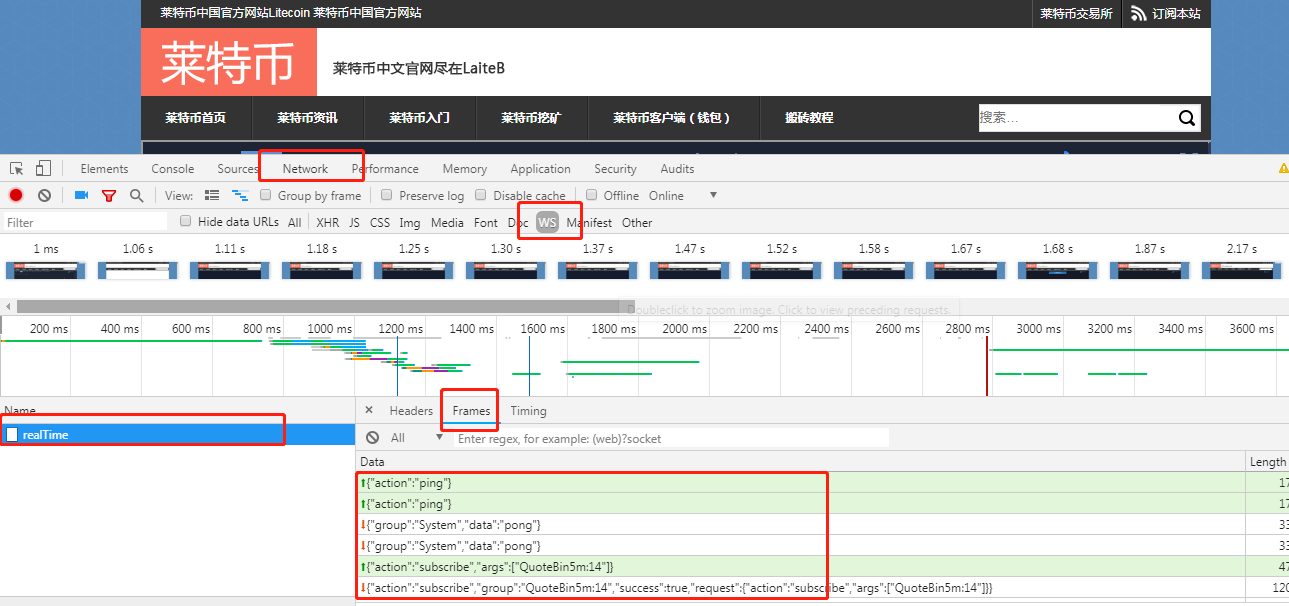
在开发者工具中提供了筛选功能,其中 WS 选项代表只显示 WebSocket 连接的网络请求。
这时候可以看到请求记录列表中有一条名为 realTime 的记录,鼠标左键点击它后,开发者工具会分为左右两栏,右侧列出本条请求记录的详细信息:
与 HTTP 请求不同的是,WebSocket 连接地址以 ws 或 wss 开头。连接成功的状态码不是 200,而是 101。

Headers 标签页记录的是 Request 和 Response 信息,而 Frames 标签页中记录的则是双方互传的数据,也是我们需要爬取的数据内容:

Frames 图中绿色箭头向上的数据是客户端发送给服务端的数据,橙色箭头向下的数据是服务端推送给客户端的数据。
从数据顺序中可以看到,客户端先发送:
{"action":"subscribe","args":["QuoteBin5m:14"]}
然后服务端才会推送信息(一直推送):
{"group":"QuoteBin5m:14","data":[{"low":"55.42","high":"55.63","open":"55.42","close":"55.59","last_price":"55.59",
"avg_price":"55.5111587372932781077","volume":"40078","timestamp":1551941701,"rise_fall_rate":"0.0030674846625766871",
"rise_fall_value":"0.17","base_coin_volume":"400.78","quote_coin_volume":"22247.7621987324"}]}
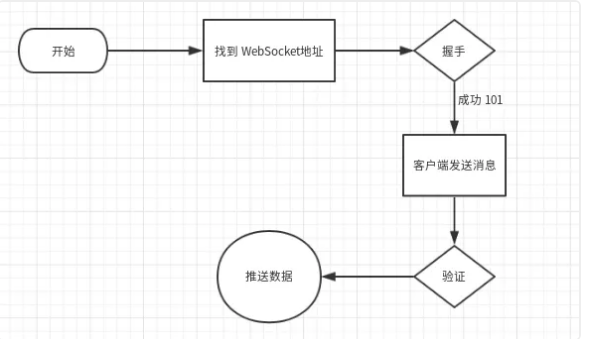
所以,从发起握手到获得数据的整个流程为:
那么,现在问题来了:
握手怎么弄?
连接保持怎么弄?
消息发送和接收怎么弄?
有什么库可以轻松实现吗?
四、aiowebsocket
Python 库中用于连接 WebSocket 的有很多,但是易用、稳定的有 websocket-client(非异步)、websockets(异步)、aiowebsocket(异步)。
可以根据项目需求选择三者之一,今天介绍的是异步 WebSocket 连接客户端 aiowebsocket。其 Github 地址为:https://github.com/asyncins/aiowebsocket。
ReadMe中介绍到:
AioWebSocket是一个遵循 WebSocket 规范的 异步 WebSocket 客户端,相对于其他库它更轻、更快。
它的安装和其他库一样简单,使用 pip install aiowebsocket 即可。安装好后,我们可以根据 ReadMe 中提供的示例代码来测试:
import asyncio
import logging
from datetime import datetime
from aiowebsocket.converses import AioWebSocket async def startup(uri):
async with AioWebSocket(uri) as aws:
converse = aws.manipulator
message = b'AioWebSocket - Async WebSocket Client'
while True:
await converse.send(message)
print('{time}-Client send: {message}'
.format(time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'), message=message))
mes = await converse.receive()
print('{time}-Client receive: {rec}'
.format(time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'), rec=mes)) if __name__ == '__main__':
remote = 'ws://echo.websocket.org'
try:
asyncio.get_event_loop().run_until_complete(startup(remote))
except KeyboardInterrupt as exc:
logging.info('Quit.')
运行后的结果输出为:
2019-03-07 15:43:55-Client send: b'AioWebSocket - Async WebSocket Client'
2019-03-07 15:43:55-Client receive: b'AioWebSocket - Async WebSocket Client'
2019-03-07 15:43:55-Client send: b'AioWebSocket - Async WebSocket Client'
2019-03-07 15:43:56-Client receive: b'AioWebSocket - Async WebSocket Client'
2019-03-07 15:43:56-Client send: b'AioWebSocket - Async WebSocket Client'
……
send 表示客户端向服务端发送的消息
recive 表示服务端向客户端推送的消息
五、编码获取数据
回到这一次的爬取需求,目标网站是莱特币官网:
从刚才的网络请求记录中,我们得知目标网站的 WebSocket 地址为:wss://api.bbxapp.vip/v1/ifcontract/realTime,从地址中可以看出目标网站使用的是 wss,也就是 ws 的安全版,它们的关系跟 HTTP/HTTPS 一样。aiowebsocket 会自动处理并识别 ssl,所以我们并不需要作额外的操作,只需要将目标地址赋值给连接 uri 即可:
import asyncio
import logging
from datetime import datetime
from aiowebsocket.converses import AioWebSocket async def startup(uri):
async with AioWebSocket(uri) as aws:
converse = aws.manipulator
while True:
mes = await converse.receive()
print('{time}-Client receive: {rec}'
.format(time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'), rec=mes)) if __name__ == '__main__':
remote = 'wss://api.bbxapp.vip/v1/ifcontract/realTime'
try:
asyncio.get_event_loop().run_until_complete(startup(remote))
except KeyboardInterrupt as exc:
logging.info('Quit.')
运行代码后观察输出,你会发现什么都没有发生。既没有内容输出,也没有断开连接,程序一直在运行,但是什么都没有:
这是为什么呢?
是对方不接受我方的请求吗?
还是有什么反爬虫限制呢?
实际上,刚才的流程图可以解释这个问题:
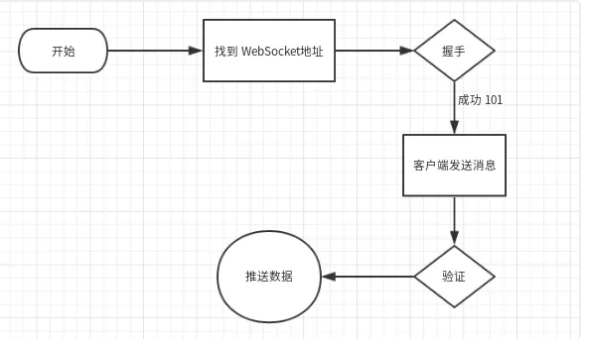
整个流程中有一步是需要客户端给服务端发送指定的消息,服务端验证后才会不停推送数据。所以,应该在消息读取前、握手连接后加上消息发送的代码:
import asyncio
import logging
from datetime import datetime
from aiowebsocket.converses import AioWebSocket async def startup(uri):
async with AioWebSocket(uri) as aws:
converse = aws.manipulator
# 客户端给服务端发送消息
await converse.send('{"action":"subscribe","args":["QuoteBin5m:14"]}')
while True:
mes = await converse.receive()
print('{time}-Client receive: {rec}'
.format(time=datetime.now().strftime('%Y-%m-%d %H:%M:%S'), rec=mes)) if __name__ == '__main__':
remote = 'wss://api.bbxapp.vip/v1/ifcontract/realTime'
try:
asyncio.get_event_loop().run_until_complete(startup(remote))
except KeyboardInterrupt as exc:
logging.info('Quit.')
保存后运行,就会看到数据源源不断的推送过来:

到这里,爬虫就能够获取到想要的数据了。
aiowebsocket 做了什么
代码不长,使用的时候只需要将目标网站 WebSocket 地址填入,然后按照流程发送数据即可,那么 aiowebsocket 在这个过程中做了什么呢?
首先,aiowebsocket 根据 WebSocket 地址,向指定的服务端发送握手请求,并校验握手结果。
然后,在确认握手成功后,将数据发送给服务端。
整个过程中为了保持连接不断开,aiowebsocket 会自动与服务端响应 ping pong。
最后,aiowebsocket 读取服务端推送的消息
爬取实时变化的 WebSocket 数据(转载)的更多相关文章
- Python如何爬取实时变化的WebSocket数据【华为云技术分享】
一.前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据.股市实时数据或币圈实时变化的数据.如下图: Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSo ...
- Python如何爬取实时变化的WebSocket数据
一.前言 作为一名爬虫工程师,在工作中常常会遇到爬取实时数据的需求,比如体育赛事实时数据.股市实时数据或币圈实时变化的数据.如下图: Web 领域中,用于实现数据'实时'更新的手段有轮询和 WebSo ...
- python 爬取天猫美的评论数据
笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行.对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了.本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似 ...
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python爬虫《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 02. 爬取get请求的页面数据
目录 02. 爬取get请求的页面数据 一.urllib库 二.由易到难的爬虫程序: 02. 爬取get请求的页面数据 一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用 ...
- Python3爬取王者官方网站英雄数据
爬取王者官方网站英雄数据 众所周知,王者荣耀已经成为众多人们喜爱的一款休闲娱乐手游,今天就利用python3 爬虫技术爬取官方网站上的几十个英雄的资料,包括官方给出的人物定位,英雄名称,技能名称,CD ...
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
随机推荐
- html5之音频、视频(video&audio)
音频&视频 本篇为本人的学习笔记. 在Html5之前,浏览器对于视频和音频的处理并没有一个标准.因此在网页中看到的视频,都是通过第三插件的方式嵌入的,如:QuickTime.RealPlaye ...
- git之创建版本库
好吧,你知道了git既然有这么多好处,那么我们接下来就可以使用git命令来创建我们的仓库.这一节我们来学习一下如何在windows下面建立自己的仓库.首先我们先在本地创建一个主目录,比如文件名字叫le ...
- Java SimpleDateFormat工具类
package AnimalDemo; import java.text.ParseException; import java.text.SimpleDateFormat; import java. ...
- Sharepoint 文档知识管理系统--Word在试图打开文件时遇到错误
在系统开发中,遇到问题:SharePoint 2010与Office 2010安装在一台服务器上,当用Office打开SharePoint文档库中的文档时,遇到“Word在试图打开文件时遇到错误,请尝 ...
- 小学四则运算生成器(Java) 刘少允,梁新男
github传送门 项目相关要求 使用 -n 参数控制生成题目的个数.(实现) 使用 -r 参数控制题目中数值(自然数.真分数和真分数分母)的范围.(实现) 生成的题目中计算过程不能产生负数.(实现) ...
- C# socket请求的名称有效 但是找不到请求的类型的数据
程序以前在xp下运行一直良好,但将安装在win7下面却出现"请求的名称有效 但是找不到请求的类型的数据"错误,程序底层通信是基于socket,时间久了就会出现系统黑屏死机,但并不知 ...
- Mybatis-generator逆向工程
$.Mybatis-generator介绍 MyBatis Generator(MBG)是MyBatis MyBatis 和iBATIS的代码生成器.它将为所有版本的MyBatis以及版本2.2.0之 ...
- sysbase 笔记
Alter 在已有数据的表中新增一个字段: ALTER table ciecdb.ciec.eci_mansmfile ADD num int default 0;
- Permission denied: .gvfs
$ sudo umount /home/william/.gvfs $ rm -rf ~/.gvfs/ Reference: (Permission denied: .gvfs)[https://an ...
- 从程序员的角度深入理解MySQL
前言 今天我将站在程序员的角度以MySQL为例探索数据库的奥秘! 数据库基本原理 我对DB的理解 1.数据库的组成:存储 + 实例 不必多说,数据当然需要存储:存储了还不够,显然需要提供程序对存储 ...