Python中的Unicode编码和UTF-8编码
下午看廖雪峰的Python2.7教程,看到 字符串和编码 一节,有一点感受,结合崔庆才的Python博客 ,把这种感受记录下来:
ASCII码:是用一个字节(8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号.主要用来表示现代英语和西欧语言。
所以处理中文就出现问题了,因为中文处理至少需要两个字节,所以中国制定了GB2312。
所以,各国制定了各国的标准。日本制定了Shift_JIS,韩国制定了Euc-kr。。。那么,乱码就来了。
为了统一,Unicode诞生了。统一码把所有语言都统一到一套编码里。解决了乱码问题,但是存储和传输效率低下的问题又来了。
因为ASCII编码是1个字节,而Unicode编码通常是2个字节。你表示一个英文字母一个字节就够了,但是Unicode却不得不用两个字节来表示(另一个字节补0)。
为了节约,出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间(ASCII码可以看成是UTF-8的一部分,所以大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作)。
现在如果我要用Notepad编辑一个python的脚本,我打开文件的过程中,内存中就开辟了一段空间,来临时存储我保存的代码,在计算机内存中,统一使用Unicode编码。
所以我写的中文字符串,要在前面加u表示是Unicode编码的字符串。
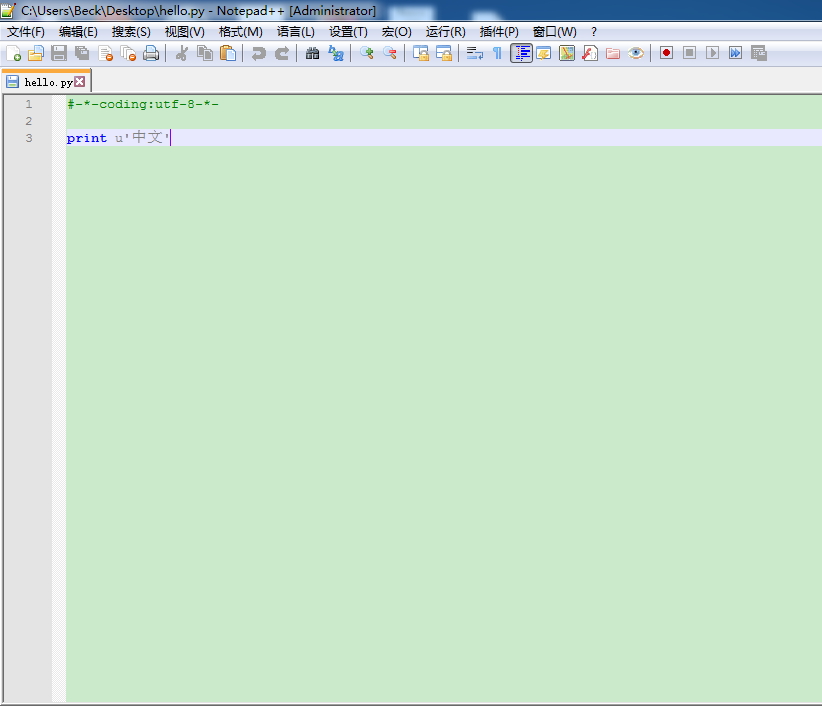
静觅博客中也是:

但是为什么有时候,我们要用到decode('utf-8'),再结合静觅博客来看:
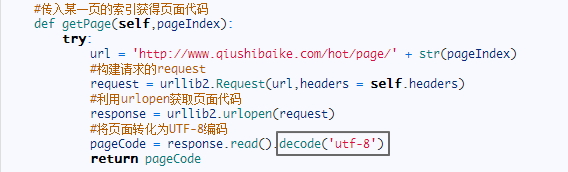
因为糗事百科的服务器发送给客户端(也就是浏览器)的响应的编码就是‘UTF-8':
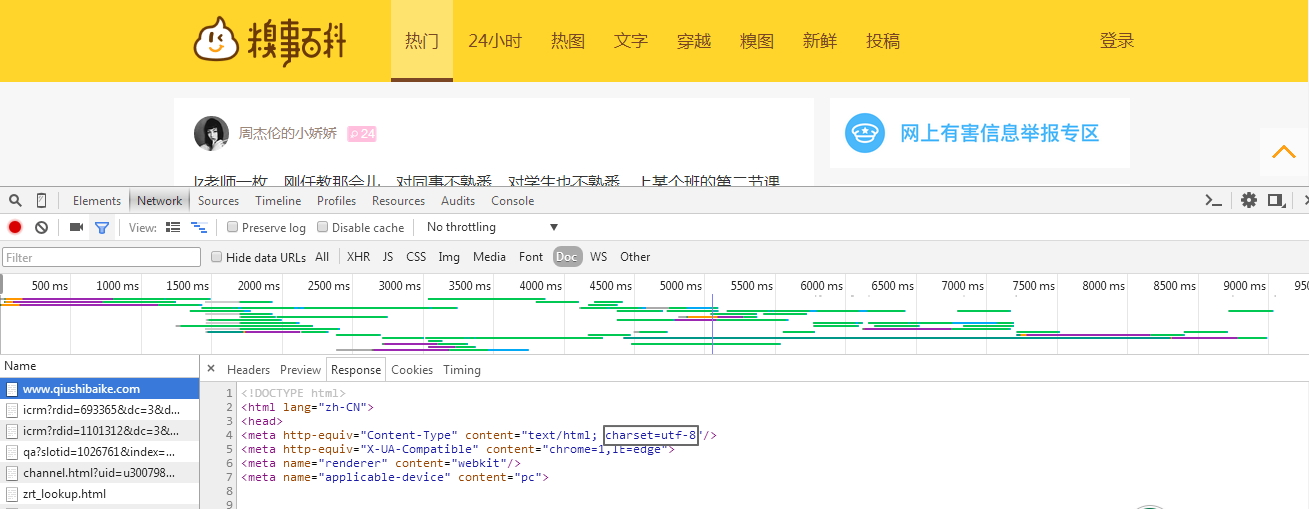

为了在文本编辑(读取文本)时,内存中需要Unicode编码,所以用decode('utf-8')解码,把UTF-8转化为Unicode编码(同理,encode('utf-8')是把Unicode转化为UTF-8编码)。
当保存文本到保存到硬盘或者需要传输的时候,就转换为UTF-8编码,所以我们需要在python脚本开头定义#-*-coding:utf-8-*-

图片来源
廖雪峰的官方网站:https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/001386819196283586a37629844456ca7e5a7faa9b94ee8000
静觅 崔庆才的个人博客:http://cuiqingcai.com/990.html
Python中的Unicode编码和UTF-8编码的更多相关文章
- python 中的unicode详解
通过例子来看问题是比较容易懂的. 首先来看,下面这个是我新建的一个txt文件,名字叫做ivan_utf8.txt,然后里面随便编辑了一些东西. 然后来用控制台打开这个文件,同样也是截图: 这里就是简单 ...
- 关于python中的unicode字符串的使用
基于python2.7中的字符串: unicode-->编码encode('utf-8')-->写入文件 读出文件-->解码decode('utf-8')-->unicode ...
- Python中的数据类型、变量、字符编码、输入输出、注释
数据类型 number(数字) 用于存储类型,通常分为int.long.float.complex: int:32位机器上占32位,取值范围为-231 ~ 231 - 1:64位机器上占64位,取值范 ...
- python中的while循环,格式化输出,运算符,编码
一.while循环 1.1语法 while 条件: 代码块(循环体) else: 当上面的条件为假的的时候,才会执行. 执行顺序:先判断条件是否为真,如果是真的,执行循环体,再次判断条件,直到条件不成 ...
- python 中的while循环、格式化、编码初始
while循环 循环:不断重复着某件事就是循环 while 关键字 死循环:while True: 循环体 while True: # 死循环# print("坚强")# pr ...
- python中url解析 or url的base64编码
目录 from urllib.parse import urlparse, quote, unquote, urlencode1.解析url的组成成分:urlparse(url)2.url的base6 ...
- python的str,unicode对象的encode和decode方法, Python中字符编码的总结和对比bytes和str
python_2.x_unicode_to_str.py a = u"中文字符"; a.encode("GBK"); #打印: '\xd6\xd0\xce\xc ...
- python中unicode 和 str相互转化
python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byte[]. 而python中的unicode对象应该才是等同于java中的S ...
- python中unicode和unicodeescape
在python中,unicode是内存编码集,一般我们将数据存储到文件时,需要将数据先编码为其他编码集,比如utf-8.gbk等. 读取数据的时候再通过同样的编码集进行解码即可. #python3 & ...
随机推荐
- 三、Nuxt项目目录结构
使用IDE打开我们初始化完的新项目,然后发现目录如下图所示 现在来介绍一下每个目录和文件 .idea 是我使用的IDE是IDEA自动生成的,跟项目无关 .nuxt ...
- Android系统移植与调试之------->Amlogic方案编译步骤
1. 拷贝Amlogic的SourceCode 切换目录到 /home/roco/work/amlogic/SourceCode/mx0831-0525下将mx0831-0525.tgz拷贝到 / ...
- php 数组 高效随机抽取指定条记录的算法
php使用数组array_rand()函数进行高效随机抽取指定条数的记录,可以随机抽取数据库中的记录,适合进行随机展示和抽奖程序. 该算法主要是利用php的array_rand()函数,下面看一下ar ...
- highcharts基本介绍
转自:http://www.cnblogs.com/jyh317/p/4189773.html 一.highcharts简介 Highcharts是一款纯javascript编写的图表库,能够很简单便 ...
- UI控件之UITableView的基本属性
UITableView:特殊的滚动视图,横向固定,可以在纵向上滚动,自动计算contentSize 创建tableView,初始化时指定样式,默认是plain UITableView *_tableV ...
- sublime text C++
几乎每一门编程语言都是从"Hello, world!"学起的, 刚学编程的时候感觉有点枯燥, 对它不够重视. 可是到后来慢慢发现, 几乎我学到的每一个知识点, 在最开始都是经过 h ...
- Springboot文件下载
https://blog.csdn.net/stubbornness1219/article/details/72356632 Springboot对资源的描述提供了相应的接口,其主要实现类有Clas ...
- p2p网络中的NAT穿透技术----常见NAT穿越解决方案
转:http://blog.csdn.net/cllzw/article/details/46438257 常见NA丁穿越解决方案 NAT技术在缓解IPv4地址紧缺问题.构建防火墙.保证网络安全等方面 ...
- 【Head First Servlets and JSP】笔记19:JavaBeans与JSP动作元素(<jsp:setProperty.....>、<jsp:getProperty.....>)
内容来自imooc. 1.什么是JSP动作元素 2.在JSP页面中如何使用Javabeans <jsp:......>表示这是一个JSP动作元素 3.使用JSP动作元素创建JavaBean ...
- Shell编程之变量进阶
一.变量知识进阶 1.特殊的位置参数变量 实例1:测试$n(n为1...15) [root@codis-178 ~]# cat p.sh echo $1 [root@codis-178 ~]# sh ...