视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(2)
聚类概念:
聚类:简单地说就是把相似的东西分到一组。同 Classification (分类)不同,分类应属于监督学习。而在聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,因此,一个聚类算法通常只需要知道如何计算相似 度就可以开始工作了。聚类不需要使用训练数据进行学习,应属于无监督学习。
我们经常接触到的聚类分析,一般都是数值聚类,一种常见的做法是同时提取 N 种特征,将它们放在一起组成一个 N 维向量,从而得到一个从原始数据集合到 N 维向量空间的映射,然后基于某种规则进行分类,在该规则下,同组分类具有最大的相似性。
需要解决的问题:
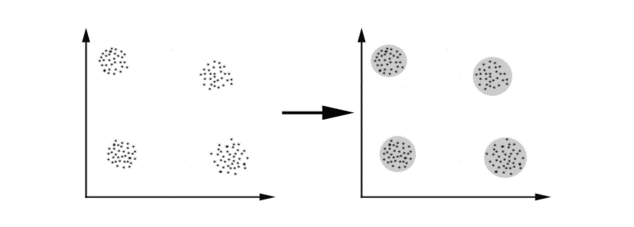
K-Means算法主要解决的问题如下图所示。我们可以看到,在图的左边有一些点,我们用肉眼可以看出来有四个点群,但是我们怎么通过计算机程序找出这几个点群来呢?
算法概要:
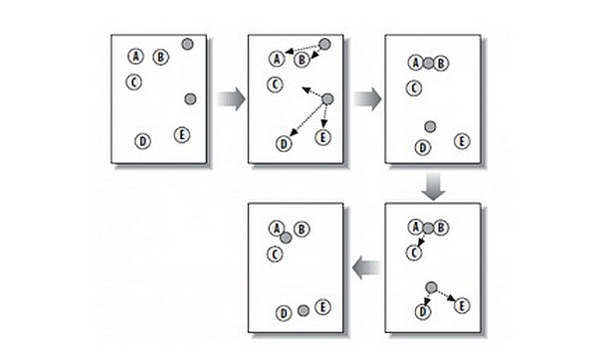
A,B,C,D,E是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2
上图K-Means的算法描述:
1.随机在图中取K(这里K=2)个种子点。
2.然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
3.接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
4.然后重复第2)和第3)步,直到种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心,反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止。
求点群中心的公式:

假设我们提取到原始数据的集合为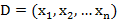 ,并且每个xi为d维的向量,K-means聚类的目的就是,在给定分类组数k(k ≤ n)值的条件下,将原始数据分成k类 S =
,并且每个xi为d维的向量,K-means聚类的目的就是,在给定分类组数k(k ≤ n)值的条件下,将原始数据分成k类 S = 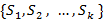 ,在数值模型上,即对以下表达式求最小值:
,在数值模型上,即对以下表达式求最小值:
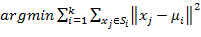
这里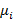 表示分类
表示分类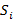 的平均值。
的平均值。
注:arg表示使目标函数取最小值时的变量值
设我们一共有 N 个数据点需要分为 K 个 cluster ,k-means 要做的就是最小化
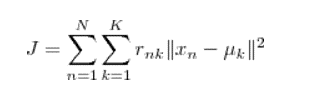
其中 rnk在 在数据点 n 被归类到 cluster k 的时候为 1 ,否则为 0 。直接寻找 rnk 和 uk 最小化 j 并不容易,不过我们可以采取迭代的办法:先固定 uk,选择最优的 rnk,很容易看出,只要将数据点归类到离他最近的那个中心就能保证 j 最小。下一步则固定 rnk ,再求最优的 uk 。将j 对 uk 求导并令导数等于零,很容易得到 j 最小的时候uk 应该满足:
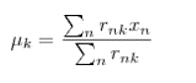
亦即 uk的值应当是所有 cluster k 中的数据点的平均值。
首先 3 个中心点被随机初始化,所有的数据点都还没有进行聚类,默认全部都标记为红色,如下图所示:
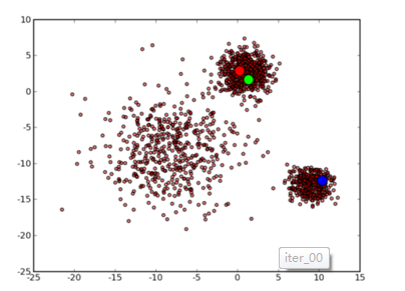
然后进入第一次迭代:按照初始的中心点位置为每个数据点着上颜色,重新计算 3 个中心点,结果如下图所示:
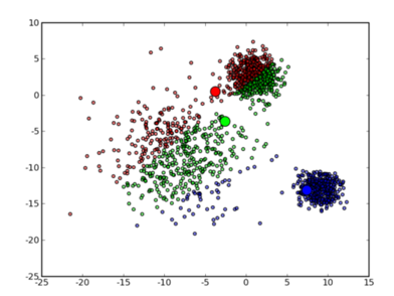
可以看到,由于初始的中心点是随机选的,这样得出来的结果并不是很好,接下来是下一次迭代的结果:
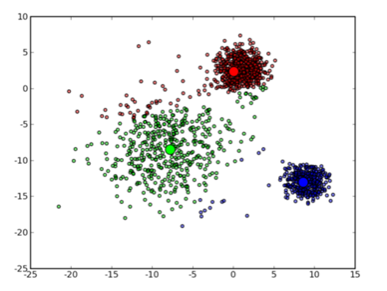
可以看到大致形状已经出来了。再经过两次迭代之后,基本上就收敛了,最终结果如下:
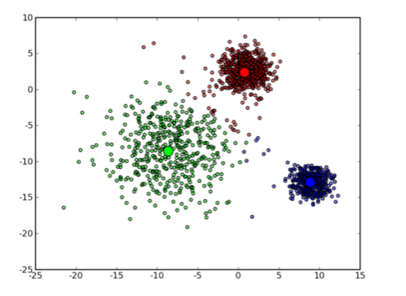
不过正如前面所说的那样 k-means 也并不是万能的,虽然许多时候都能收敛到一个比较好的结果,但是也有运气不好的时候会收敛到一个让人不满意的局部最优解,例如选用下面这几个初始中心点:
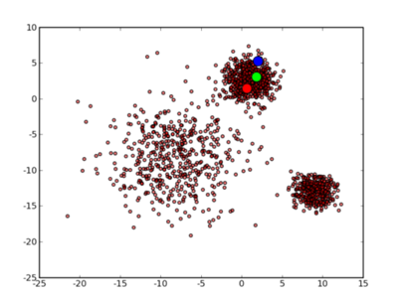
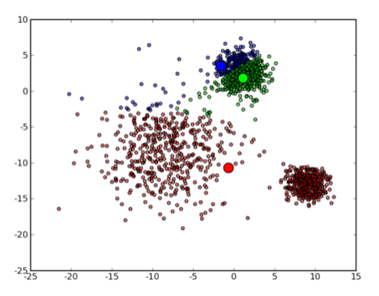
最终会收敛到这样的结果:
视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(2)的更多相关文章
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析
原文地址:http://www.cnblogs.com/zjiaxing/p/5548265.html 在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/d ...
- 视觉SLAM之词袋(bag of words) 模型与K-means聚类算法浅析(1)
在目前实际的视觉SLAM中,闭环检测多采用DBOW2模型https://github.com/dorian3d/DBoW2,而bag of words 又运用了数据挖掘的K-means聚类算法,笔者只 ...
- 第六篇 视觉slam中的优化问题梳理及雅克比推导
优化问题定义以及求解 通用定义 解决问题的开始一定是定义清楚问题.这里引用g2o的定义. \[ \begin{aligned} \mathbf{F}(\mathbf{x})&=\sum_{k\ ...
- 词袋和 TF-IDF 模型
做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征.常用的有词袋模型和TF-IDF 模型 1.词袋模型 词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的 ...
- 视觉slam十四讲开源库安装教程
目录 前言 1.Eigen线性代数库的安装 2.Sophus李代数库的安装 3.OpenCV计算机视觉库的安装 4.PCL点云库的安装 5.Ceres非线性优化库的安装 6.G2O图优化库的安装 7. ...
- 高翔《视觉SLAM十四讲》从理论到实践
目录 第1讲 前言:本书讲什么:如何使用本书: 第2讲 初始SLAM:引子-小萝卜的例子:经典视觉SLAM框架:SLAM问题的数学表述:实践-编程基础: 第3讲 三维空间刚体运动 旋转矩阵:实践-Ei ...
- 视觉SLAM关键方法总结
点"计算机视觉life"关注,置顶更快接收消息! 最近在做基于激光信息的机器人行人跟踪发现如果单独利用激光信息很难完成机器人对行人的识别.跟踪等功能,因此考虑与视觉融合的方法,这样 ...
- (转) SLAM系统的研究点介绍 与 Kinect视觉SLAM技术介绍
首页 视界智尚 算法技术 每日技术 来打我呀 注册 SLAM系统的研究点介绍 本文主要谈谈SLAM中的各个研究点,为研究生们(应该是博客的多数读者吧)作一个提纲挈领的摘要.然后,我 ...
- NLP从词袋到Word2Vec的文本表示
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本.早期是基于规则 ...
随机推荐
- Kafka 集群搭建 (自用)
Zookeeper集群搭建 1.软件环境 (3台服务器-测试环境) 192.168.56.9 192.168.56.6 192.168.56.7 1.Linux服务器一台.三台.五台.(2*n+1), ...
- Spring Ajax一个简单样例
配置不说了.要在前面helloworld的样例基础上弄. 相同在hello下新建ajax.jsp <%@ page language="java" contentType=& ...
- Bat 获取本地代码的Svn Revision并保存到变量
echo off & color 0A for /f "usebackq delims=" %%i in (`"svn info Server | findstr ...
- html的小例子
常用的前端实例: 1略 2.在网页商城中的图片当我们把鼠标放上去之后,图片会显示一个有颜色的外边框,图片某一部分的字体的颜色并发生改变 鼠标放上去之前 鼠标放上去之后: 实现的代码: <!DOC ...
- 实用且免费API接口2
之前已经整理过一些免费API,现在在知乎专栏上看到别人整理的一些实用免费API,有一些是没有重复的,因此也搬过来. 今天的内容,很适合你去做一些好玩.实用的东西出来. 先来科普个概念,开放应用程序的A ...
- UE4 场景展示Demo
使用到的level blueprint如下:
- linux 安装安装rz/sz 和 ssh
安装rz,sz yum install lrzsz; 安装ssh yum install openssh-server 查看已安装包 rpm -qa | grep ssh 更新yum源 1.备份 mv ...
- 一站式学习Wireshark(转载)
一站式学习Wireshark(一):Wireshark基本用法 2014/06/10 · IT技术 · 4 评论 · WireShark 分享到: 115 与<YII框架>不得不说的故事— ...
- SVN学习(一)——SVN 检出文件步骤、图标显示及含义
May, I come... 1. 创建一个目录用来存放检出得到的文件,例如MyCRM 2. 直接进入目录MyCRM,点右键 3. 可以看到检出得到的文件 此时文件图标上没有任何标识.可能你会想到通过 ...
- WP8滑动条(Slider)控件的使用
1. <Grid x:Name="LayoutRoot" Background="Transparent"> <Grid.RowDefinit ...