萌新也能看懂的KMP算法
前言
算法是什么?算法就是数学规律.怎么去总结和发现这个规律,就是理解算法的过程.
KMP算法的本质是穷举法,而并不是去创造新的匹配逻辑.
以下将搜寻的字符串称为子串(part),以P表示.被搜寻的字符串称为总串(total),以T表示.
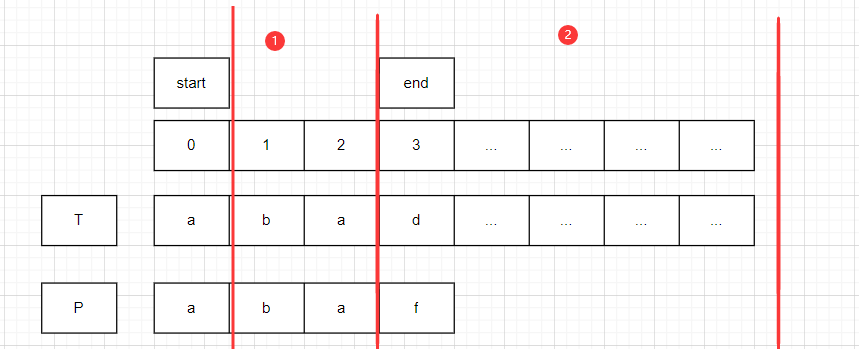
start代表P串在T串中开始匹配的位置,end代表P串与T串对比字符时的位置
String total = "ababcd";
String part = "abc";
total.contains(part);
部分匹配表
部分匹配表是KMP算法的核心。只要理解了部分匹配表,就基本理解了KMP算法。
普通匹配模式
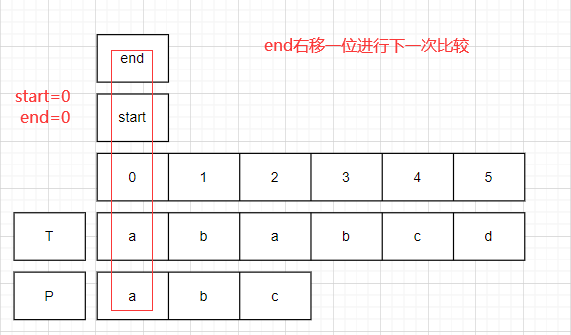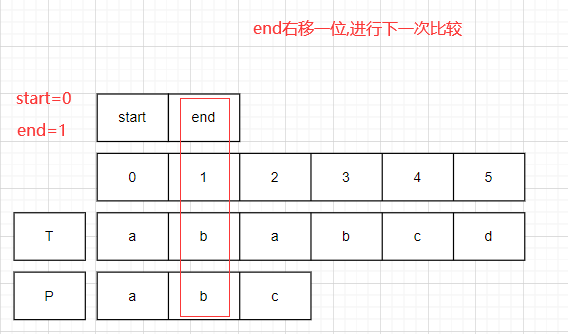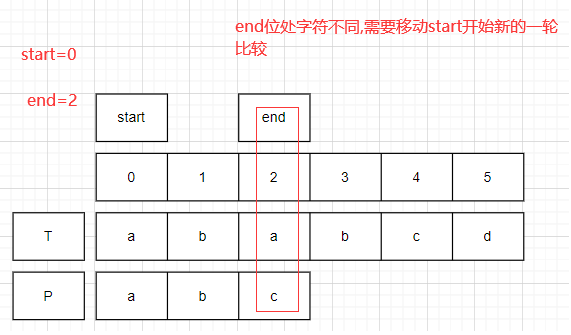
对比开始.
start=0,end=0;比较T.charAt(0)==P.charAt(0).均为a,此时end右移一位.
start=0,end=1;比较T.charAt(1)==P.charAt(1).均为b,此时end右移一位.
start=0,end=2;比较T.charAt(2)!=P.charAt(2).此时,start右移一位.
start=1,end=0;比较T.charAt(start+end)!=P.charAt(end).此时,start右移一位.
start=2,end=0;比较T.charAt(start+end)==P.charAt(end).此时,此时end右移一位.以此类推.
最终发现T.contains(P)为true,T.indexOf(P)为start,即为2.
public static int getIndex(String total, String part) {
char[] totalChars = total.toCharArray();
char[] partChars = part.toCharArray();
int start = 0;
int end = 0;
while (start < total.length()) {
if (totalChars[start + end] == partChars[end]) {
end++;
} else {
start = start + 1;
end = 0;
}
if (end == part.length()) {
return start;
}
}
return -1;
}
寻找规律
规律是什么?就是在匹配过程中,遇到某一位不匹配时.start与end下一次的起点位置选择.
对于普通匹配而言,start的变化永远是右移一位,end永远是从0开始,并且每次右移一位.
这里先介绍两个规律,当发现end位不匹配时
第一条规律,,新起点位置只与重合部分有关
T.charAt(start+end)!=P.charAt(end)
T.substring(start,start+end)==P.substring(0,end)
因为它不相等,所以它相等,这句话前后顺序不能颠倒.这虽然很像废话,但是确实KMP算法的核心.

第二条规律,未知无法跳过
这次的end位一定是下次比较的起点
这里有个特殊的地方,就是首位不同时的逻辑,代码中也是一样,先按下不表.
部分匹配表
有个比较关键的地方,确定start与end新起点的规则是什么?
新的起点是什么,是可能性,是T串的某一段与P串完全相同的可能性.
只有end=0时相同,才会有end=1时的比较
只有end=1时相同,才会有end=2时的比较
...
那么至少,T.charAt(start)==P.charAt(0),才可以进行后面的比较
当遇到end位不匹配时,我们将start可能移动的轨迹分为两部分
① (start,start+end)
② [start+end,...]
T.indexOf(P)的位置只可能出现在这两个区域(因为之前的位置都被排除了).这两个区域的差别是什么呢?
结合上面两条规律,途经区域①的比较的字符对象是完全已知的,而区域②则不是.
即下一次start的起点在 (start,start+end] 中
因为即要么在(start,start+end)中,要么就是end,因为end是未知的,必须要用首位去对比,所以start最远会位移到end位
由于第一条规律,T.substring(start,start+end)==P.substring(0,end)
那么start在T.substring(start,start+end)中位移的过程就是start在P.substring(0,end)中位移的过程
去寻找start在(start,start+end)中作为新起点的可能性,就是寻P.substring(0,end)这个字符串本身与其子串的重合度,什么是重合度?
两个相同的字符串,一个不动,一个整体向右移动一格,查看两者相交部分,如果相交部分完全相等,那么相交字符串的首位,就是新的起点,这个相交部分的长度就是重合度.
假设 P = abcde
| 不匹配时end位置 | P.substring(0,end) | 重合度 |
|---|---|---|
| 0 | "" | 0 |
| 1 | a | 0 |
| 2 | ab | 0 |
| 3 | abc | 0 |
| 4 | abcd | 0 |
获取重合度
public static int getPublicPart(String part) {
int start = 1;
int end = 0;
char[] chars = part.toCharArray();
while (start < part.length()) {
if (chars[start + end] == chars[end]) {
if (end + start == part.length() - 1) {
return part.substring(start).length();
}
end++;
} else {
start++;
end = 0;
}
}
return 0;
}
我们将start移动轨迹的研究,变成了P.substring(0,end)的研究,那么假设T串很长,那么end值可能会出现在任意一个地方,并且相同情况会有多次,所以我们只要事先将所有可能的情况列出,以后遇到相同情况就可以直接套用结果.
为什么可以复用呢?因为P.charAt(end)我们一定知道什么,但是T.charAt(start+end)却有很多种可能,因为它只需要与P.charAt(end)不相等
假设 P = aaaab
| 不匹配时end位置 | P.substring(0,end) | 重合度 | 下一次start位置 | 下一次end位置 |
|---|---|---|---|---|
| 4 | aaaa | 3 | start+4-3 | 3 |
| 3 | aaa | 2 | start+3-2 | 2 |
| 2 | aa | 1 | start+2-1 | 1 |
| 1 | a | 0 | start+1-0 | 0 |
| 0 | "" | 0 | start+0-(-1) | 0 |
我们可以发现,start下一次的位置为 start +( end - P.substring(0,end)的重合度). (end - 重合度) 其实就是start需要位移的距离
end下一次的位置为 P.substring(0,end)的重合度
但是由于P.substring(0,0)为空字符串,比较特殊,首位不同时,start是直接右移一位
故令next[0] = -1 , 当 next[end] < 0时,下一次的end位置指向 0
获取next数组
public static int[] getNext(String part) {
int[] next = new int[part.length()];
int start = 1;
while (start < part.length()) {
next[start] = getPublicPart(part.substring(0, start));
start++;
}
next[0] = -1;
return next;
}
我们将end位不同时,P.substring(0,end)它的子串与自身的重合度,称之为部分匹配表
Tips:
这里有一个很关键的地方,start可以直接从0移动到2吗?不可以,因为KMP无法违背普通匹配,或者说违背匹配的规律,只有start每次右移一位,即P.charAt(0)与T串的每一位开始比较,才能确认这个位置含不含有可能性,而我们next数组的获取就是通过每次右移一位获取到的.
完整代码
KMP算法的本质就是通过穷举end位不匹配时start与end的移动轨迹,来达到复用的效果.
public static int indexOf(String total, String part) {
char[] totalChars = total.toCharArray();
char[] partChars = part.toCharArray();
int[] next = getNext(part);
int start = 0;
int end = 0;
while (start < total.length()) {
if (totalChars[start + end] == partChars[end]) {
end++;
} else {
// 与普通匹配不同的其实就是end位不同时,下一次start与end的位置选择
start = start + end - next[end];
end = Math.max(0, next[end]);
}
if (end == part.length()) {
return start;
}
}
return -1;
}
小小的一篇文章,写了快一个月,每天晚上将思想转化为文字时,总会有新的理解,修修改改了这么长时间,总觉得文字不够干练.人生亦是如此.
萌新也能看懂的KMP算法的更多相关文章
- 从Webpack源码探究打包流程,萌新也能看懂~
简介 上一篇讲述了如何理解tapable这个钩子机制,因为这个是webpack程序的灵魂.虽然钩子机制很灵活,而然却变成了我们读懂webpack道路上的阻碍.每当webpack运行起来的时候,我的心态 ...
- 保证你能看懂的KMP字符串匹配算法
文章转载自一位大牛: 阮一峰原网址http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm ...
- hdu1711(终于搞懂了KMP算法了。。)
题意:给你两个长度分别为n(1 <= N <= 1000000)和m(1 <= M <= 10000)的序列a[]和b[],求b[]序列在a[]序列中出现的首位置.如果没有请输 ...
- Floyd-蒟蒻也能看懂的弗洛伊德算法(当然我是蒟蒻)
今天来讲点图论的知识,来看看最短路径的一个求法(所有的求法我以后会写,也有可能咕咕咕) 你们都说图看着没意思不好看,那今天就来点情景 暑假,_GC准备去一些城市旅游.有些城市之 ...
- Floyd算法-傻子也能看懂的弗洛伊德算法(转)
暑假,小哼准备去一些城市旅游.有些城市之间有公路,有些城市之间则没有,如下图.为了节省经费以及方便计划旅程,小哼希望在出发之前知道任意两个城市之前的最短路程. ...
- Floyd-傻子也能看懂的弗洛伊德算法(转)
暑假,小哼准备去一些城市旅游.有些城市之间有公路,有些城市之间则没有,如下图.为了节省经费以及方便计划旅程,小哼希望在出发之前知道任意两个城市之前的最短路程. ...
- 萌新学习图的强连通(Tarjan算法)笔记
--主要摘自北京大学暑期课<ACM/ICPC竞赛训练> 在有向图G中,如果任意两个不同顶点相互可达,则称该有向图是强连通的: 有向图G的极大强连通子图称为G的强连通分支: Tarjan算法 ...
- Vue初识:一个前端萌新的总结
一.前言 时隔三年,记得第一次写博客还是2015年了,经过这几年的洗礼,我也从一个后端的小萌新变成现在略懂一点点知识的文青.如今对于前端的东东也算有一知半解,个人能力总的来说,也能够独立开发产品级项目 ...
- KMP算法的工作流程介绍
最近又想起了KMP算法,原来一直没搞明白工作原理,现在总算是开点窍了,推荐大家看这篇文章,写的很简单易懂 推荐理由:简单明了,是我看过介绍KMP算法流程的所有文章中,最易懂的一篇(这篇文章仅仅是介绍了 ...
随机推荐
- mac下安装YII
新换了台电脑,一个mac,特蛋疼的各种环境安装.两个多小时,总算把开发环境配好了. XAMPP就不用说了,phpstorm(javaEE 6.0),navicat for mysql ,一堆的注册码, ...
- React Native环境配置、初始化项目、打包安装到手机,以及开发小知识
1.前言 环境:Win10 + Android 已经在Windows电脑上安装好 Node(v14+).Git.Yarn. JDK(v11) javac -version javac 11.0.15. ...
- v-model原理问题
v-model的原理 很多同学在理解Vue的时候都把Vue的数据响应原理理解为双向绑定,但实际上这是不准确的,我们之前提到的数据响应,都是通过数据的改变去驱动DOM重新的变化,而双向绑定已有数据驱动D ...
- 日志(logging模块)
1. 为什么要使用日志(作用) 在学习过程中,写一个小程序或小demo时,遇到程序出错时,我们一般会将一些信息打印到控制台进行查看,方便排查错误.这种方法在较小的程序中很实用,但是当你的程序变大,或是 ...
- Eplan创建符号
1.打开Eplan P8 ,新建一个名为"新项目"的项目,然后选择菜单"工具"----"主数据"-----"符号库"-- ...
- MySQL金融应用场景下跨数据中心的MGR架构方案(2)
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 如何在多个数据中心部署多套MGR集群,并实现故障快速切换. 上篇文章介绍了如何在多数据中心部署多套MGR集群,并构建集群间 ...
- Windows 电脑杀毒简单有效的方式
Windows 电脑杀毒通常会选择杀毒软件,这样太笨重,且容易占内存和存在流氓软件侵入. 推荐使用 Windows 自带的恶意软件删除工具 按住 Win + R 键,弹出运行窗口,输入 mrt. 系统 ...
- ASP.NET Core依赖注入系统学习教程:容器对构造函数选择的策略
.NET Core的依赖注入容器之所以能够为应用程序提供服务实例,这都归功于ServiceDescriptor对象提供的服务注册信息.另外,在ServiceDescriptor对象中,还为容器准备了3 ...
- ArkUI 自定义组件
基础入门 组件可以把一段代码封装起来,目的是提高这一段代码的复用率,并且也可以减少开发人员多次编写相同的代码.一旦组件定义好了之后,在页面中只需要通过<element /> 标签引入进来就 ...
- C++ 一键关闭屏幕
Demo下载地址:http://pan.baidu.com/s/1vN4wF #include <windows.h> #include "resource.h" LR ...