Python数据科学手册-Pandas数据处理之简介

Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构
本质是带行标签 和 列标签、支持相同类型数据和缺失值的 多维数组
增强版的Numpy结构化数组
行和列不在只是简单的整数索引,还可以带上标签,
- 三个基本数据结构
Series DataFrame Index
Series
Series将一组数据和一组索引绑定在一起
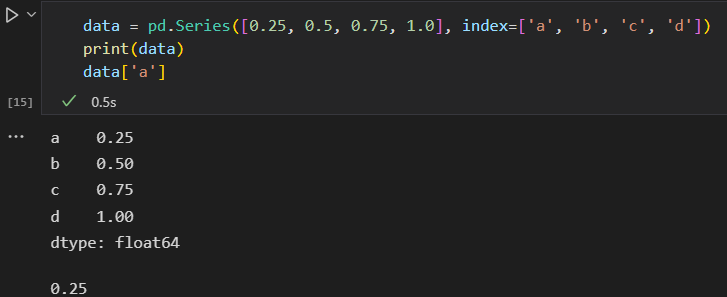
可以通过values 和 index属性获取数据,
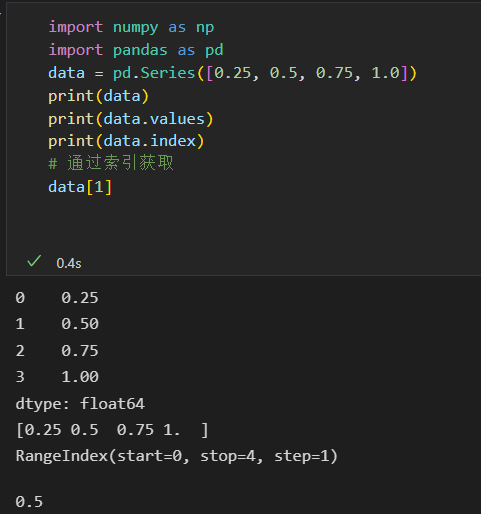
与Numpy数据的区别:Numpy数组通过隐式定义的整数索引获取数值,Pandas 的Series用显示定义的索引与数值关联
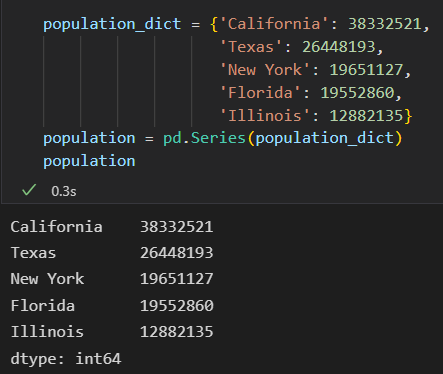
Series是特殊的字典
字典是一种将任意键映射到一组任意值的数据结构
Series对象是一种将类型键映射到一组类型值 的数据结构, 类型至关重要。
因为有类型信息,所以比Python字典更高效
可以直接使用Python字典创建一个Series对象
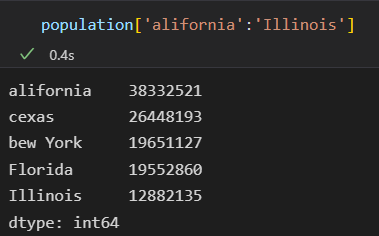
- 和字典不同,Series对象还支持数组形式的操作
创建Series对象
pd.Series(data, index=index)
index是一个可选参数,data参数支持多种数据类型, 可以是列表 或 Numpy数组, index默认值为整数序列
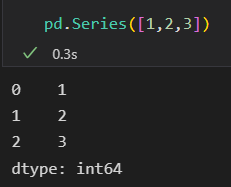
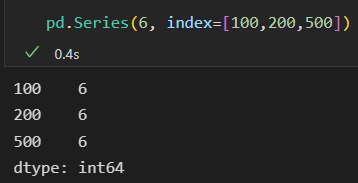
data可以是个标量,创建对象是会重复填充到每个索引上。
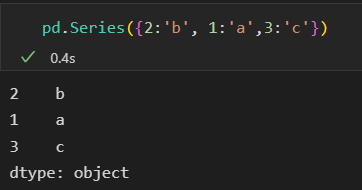
data可以是字典,索引是默认的,不排序,老版本的好像对index进行排序了。
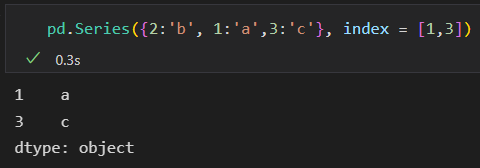
每一种形式都可以通过显示指定索引 筛选需要的结果
Pandas的DataFrame对象
也可以作为一个通用型的Numpy数组,也可以看做特殊的Python字典
DataFrame :通用的Numpy数组
Series是 有 灵活索引的一维 数组 , DataFrame是 一种 既有 灵活的行索引,又有灵活列名 的二维数组 。
DataFrame也可以看成 是若干个Series对象。。索引相同。

index属性获取索引标签

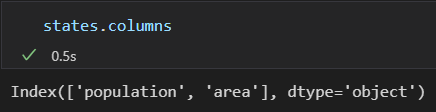
DataFrame还有一个columns属性, 是存放列标签的Index对象:
DataFrame :特殊的字典
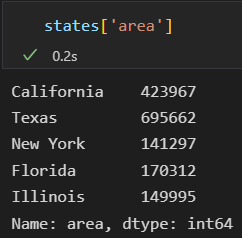
字典是一个键映射一个值,而DataFrame是 一个列名映射一个Series的数据。
创建DataFrame对象
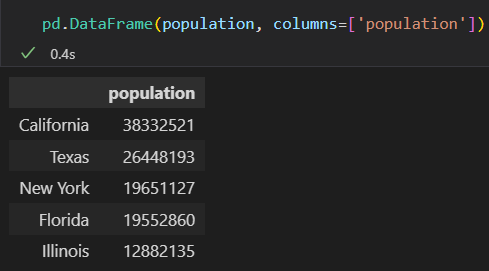
1)通过单个Series对象创建。DataFrame是一组Series对象的集合
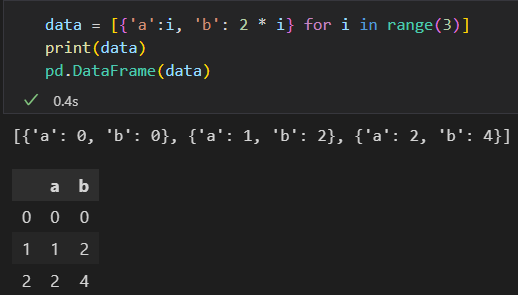
2)通过字典列表创建。 任何元素是字典的列表都可以变成DataFrame
3)通过Series对象常见,开始介绍那样子。
4)通过Numpy二维数组创建
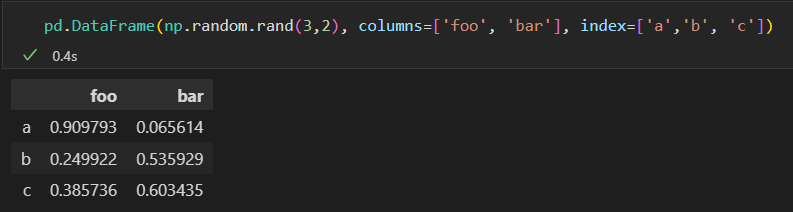
5)通过Numpy结构化数组创建
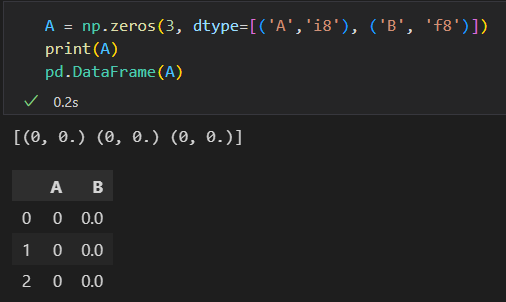
Pandas的Index对象
Series 和 DataFrame 对象都使用便于引用和调整的 显示索引。
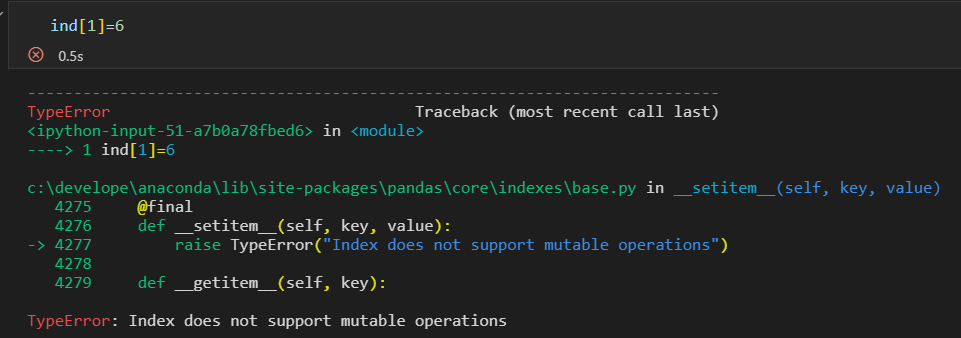
Pandas的Index对象是一个很有趣的数据结构。 可以将它看作是一个 不可变数组 或 有序集合,
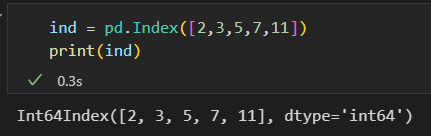
1)将Index看作不可变数组
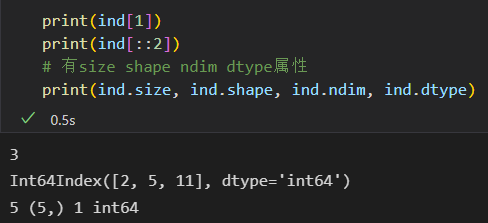
如果修改索引值会报错。对象的不可变性,使得多个DataFrame和数组之间进行索引共享是更加安全
2)将Index看作有序集合
Pandas对象被设计用于实现多操作。 如连接数据集。并集 交集 差集
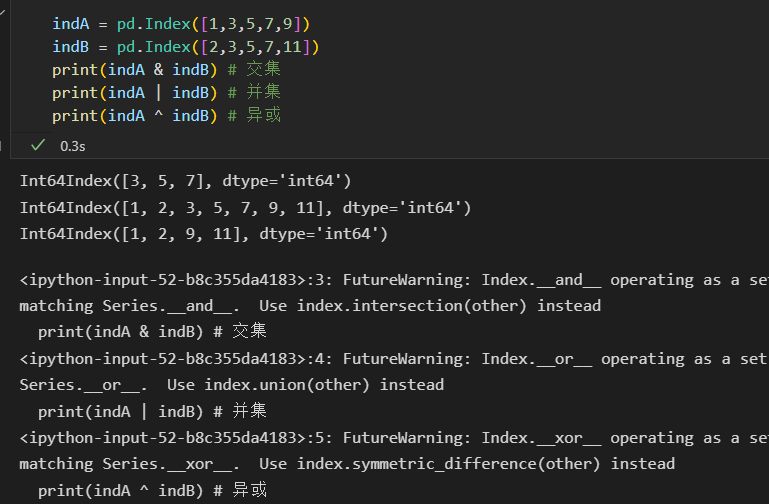
不过好像不推荐用这种方式了。哈哈
使用对象方法

Python数据科学手册-Pandas数据处理之简介的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- 更好的Android多线程下载框架
/** * 作者:Pich * 原文链接:http://me.woblog.cn/ * QQ群:129961195 * Github:https://github.com/lifengsofts */ ...
- adb工具
ADB:全称为Android Debug Bridge,它是 Android 开发/测试人员不可替代的强大工具. 首先,下载ADB工具并安装: 下载:百度就有.下载后是个压缩包,将其拷贝到cm ...
- JAVA学习的第一周
这是发表的第一篇博客,关于Java编程的学习体会如下 1.了解Java的产生与发展时机:1995左右出现Java语言,然后Java的最主要的特点是"跨平台".对于跨平台我不太理解, ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- centos 7系统安装
1.打开VMware软件,点击创建虚拟机,默认选择,点击下一步 2.选择稍后安装,点击下一步 3.在Linux系统中选择CentOS 7 64位,点击下一步 4.选择好安装位置后,点击下一步 5.选择 ...
- docker仓库之harbor的基本使用(二)
1 1.配置docker使用harbor仓库上传下载镜像 2 #注意:如果我们配置的是https的话,本地docker就不需要任何操作就可以访问harbor 3 测试机器 4 root@ubuntu1 ...
- BootStrapBlazor 安装教程--Server模式
使用模板 使用模板是最简单的办法.因为项目模板里已经包含了BootStrapBlazor的所有需要配置的内容. 首先我们安装项目模板: dotnet new -i Bootstrap.Blazor.T ...
- MPI学习笔记(二):矩阵相乘的两种实现方法
mpi矩阵乘法(C=αAB+βC) 最近领导让把之前安装的软件lapack.blas里的dgemm运算提取出来独立作为一套程序,然后把这段程序改为并行的,并测试一下进程规模扩展到128时的并行效率. ...
- .net core3.1 abp学习开始(一)
vs版本 2019,链接数据库使用Navicat,数据库MySql abp的官网:https://aspnetboilerplate.com/,我们去Download这里下载一个模板,需要选好Targ ...
- How to code like a pro in 2022 and avoid If-Else
在浏览文章的时候发现了一篇叙述有关if-else语句的文章,这篇文章作者是Thai Tran,他原文是用英语写的,然后看着文章浅显易懂,便尝试翻译成汉语.如有不妥还望指出. 原文链接:https:// ...