Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似
Series数据选择方法
Series对象与一维Numpy数组 和标准的Python字典 在许多方面 都一样。
1)将Series看作字典
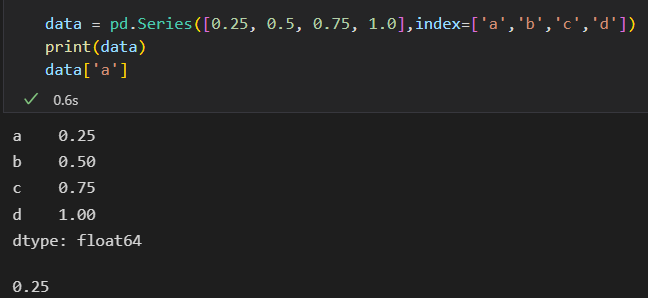
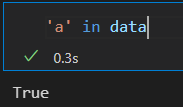
可以使用Python字典的表达式和方法来检查 键 和索引 值
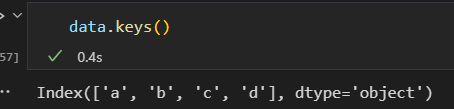
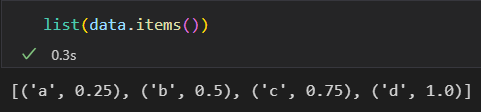
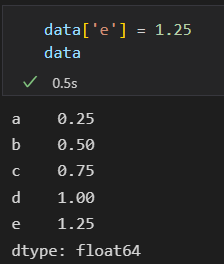
Series 可以新增,可以扩展。
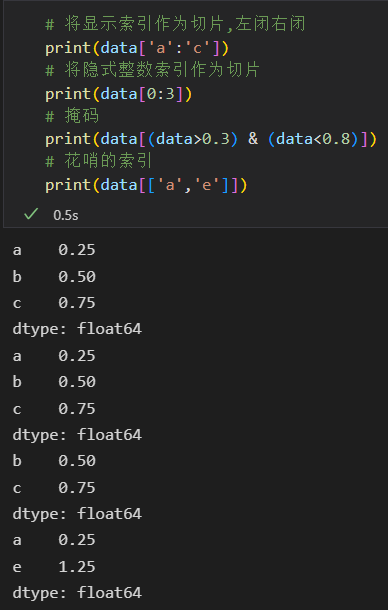
2)将Series看作一维数组
Series不仅有着和字典一样的接口,而且还具备和Numpy数组一样的数组 数据选择 包括 索引、掩码、花哨的索引等操作。
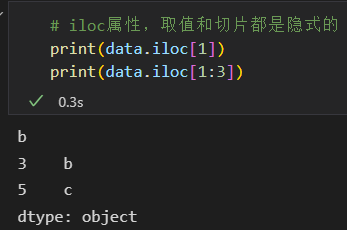
3)索引器:loc、iloc、ix
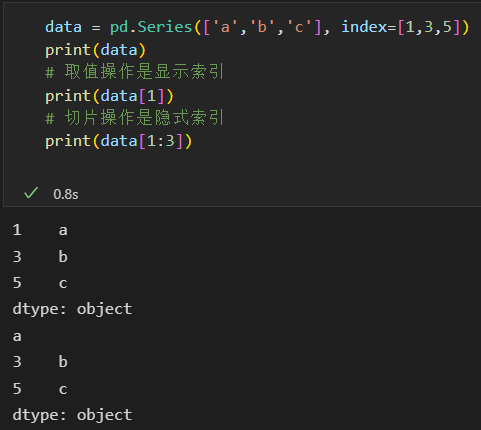
如果Series是显示整数索引,取值操作是显示索引,切片操作是隐式索引。
这样子就很容易混淆,索引Pandas提供了一些索引器(indexer)属性作为取值方法
loc 显示
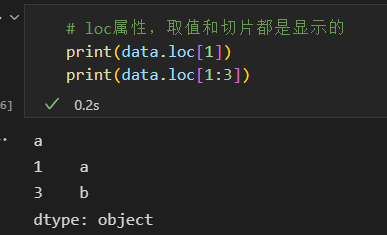
iloc 隐式
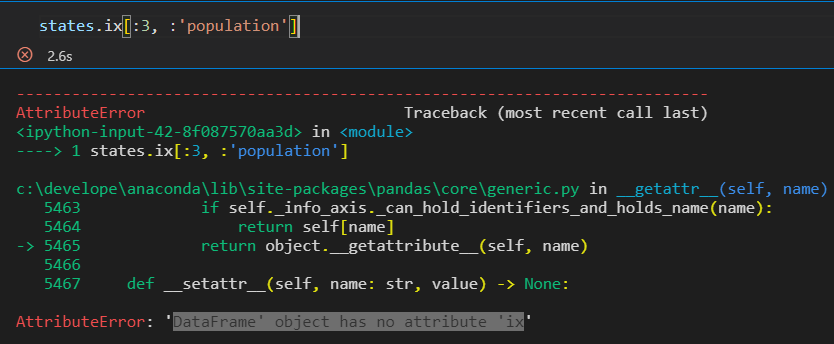
ix 是loc 和 iloc的混合形式,在Series对象中,ix等价与Python列表的取值方式。
ix主要用于DataFrame.
Python代码设计原则之一是“显示优于隐式”。 代码更容易维护 可读性更高。
DataFrame 数据选择方法
DataFrame像 二维或结构化数组,又像一个共享索引的若干Series对象的字典。
1)将DataFrame看作字典
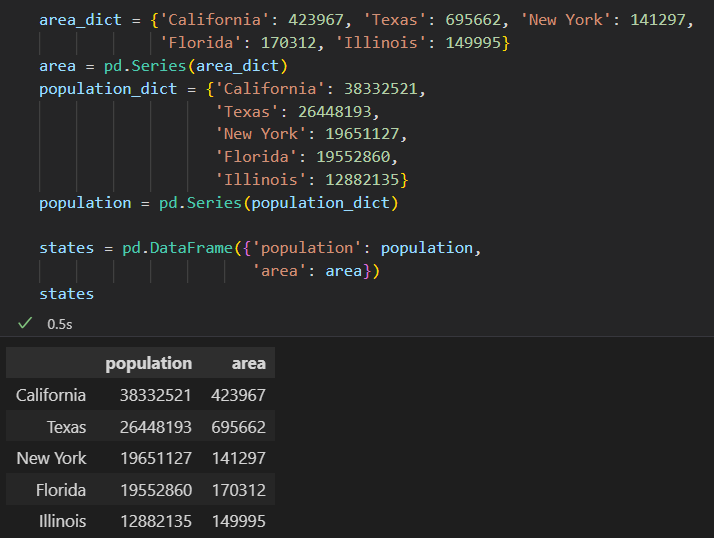
俩个Series分别构成DataFram的一列。可以通过列名进行字典形式的取值获取数据
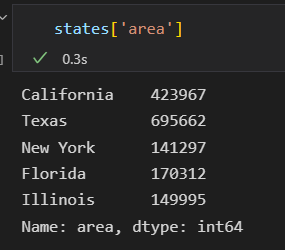
data['key'] 建议使用这个。
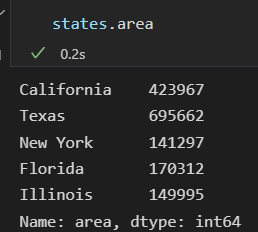
data.key
可以使用字典形式 调整对象,增加一列。
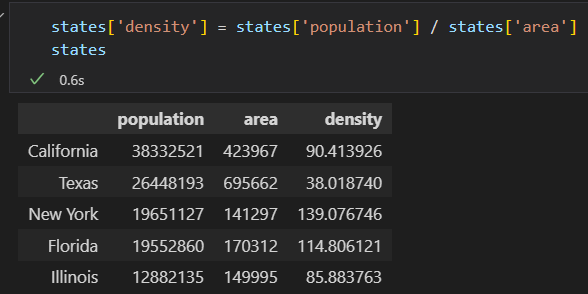
2)将DataFrame看作二维数组
DataFrame看出是一个增强版的二维数组。用values属性查看数组数据
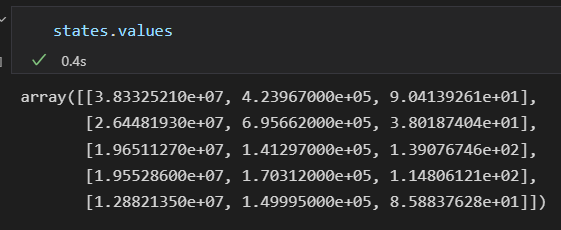
可以把许多对数组的操作用在DataFrame上
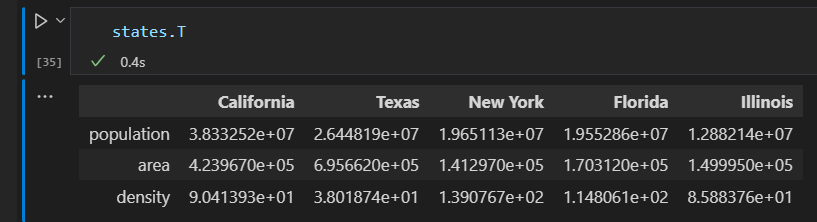
行列转置
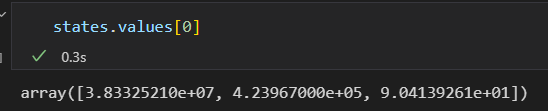
获取一行数据。
获取一列数据,需要向DataFrame传递单个列索引
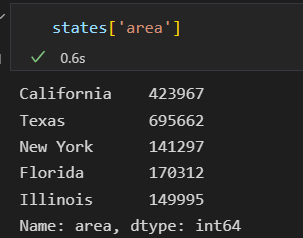
因此,进行数组形式的取值时, 需要使用索引器了。 隐式索引。 DataFrame的行列标签自动保留在结果中。

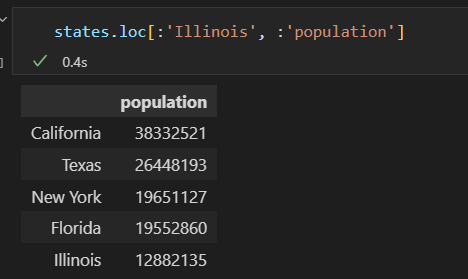
loc
ix 混合效果,新版本好像不支持了,被丢弃了。挺好。
Python数据科学手册-Pandas:数据取值与选择的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- 《Python数据科学手册》第五章机器学习的笔记
目录 <Python数据科学手册>第五章机器学习的笔记 0. 写在前面 1. 判定系数 2. 朴素贝叶斯 3. 自举重采样方法 4. 白化 5. 机器学习章节总结 <Python数据 ...
随机推荐
- JavaWeb的技术体系
客户端和服务器端的交互 browser/ server(B/S)浏览器/服务器. client/server(C/S)应用/服务器.
- 【cartographer_ros】四: 发布和订阅里程计odom信息
上一节介绍了激光雷达Scan传感数据的订阅和发布. 本节会介绍里程计Odom数据的发布和订阅.里程计在cartographer中主要用于前端位置预估和后端优化. 官方文档: http://wiki.r ...
- 一张图进阶 RocketMQ - 通信机制
前 言 三此君看了好几本书,看了很多遍源码整理的 一张图进阶 RocketMQ 图片,关于 RocketMQ 你只需要记住这张图!觉得不错的话,记得点赞关注哦. [重要]视频在 B 站同步更新,欢迎围 ...
- TMS320F280049 ADC 模块学习
1. 功能概述 2. 总体框图 block diagram 3. 可配置内容灵活分配到各个模块 或 某次转换中 4. 时钟配置 ADC 模块直接分频于系统最高时钟 5. SOC 机制 6. 如 ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- Operating System_via牛客网
题目 链接:https://ac.nowcoder.com/acm/contest/28537/F 来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 131072K,其他语 ...
- 华为交换机设置ntp时间同步
操作交换机型号:Huawei S5720 查看时间发现时间不对 [HUAWEI]display clock 2021-04-01 21:41:35 Thursday Time Zone(Default ...
- YII学习总结5(视图)
<?php namespace app\controllers; use yii\web\Controller; class HelloController extends Controller ...
- 使用Python3.7+Tornado5.1配合七牛云存储api来异步切分上传文件
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_123 之前写了几篇关于FastDfs分布式存储的文章:python3.7.3操作FastDfs来进行文件操作,其实市面上关于云存储 ...
- linux常见命令(十二)
sed/egrep将order.txt文件按行号展示出来,并删除第2,4行nl order.txt |sed '2,4d'将order.txt文件按行号展示出来,并删除第3行nl order.txt ...