Python数据科学手册-Pandas数据处理之简介

Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构
本质是带行标签 和 列标签、支持相同类型数据和缺失值的 多维数组
增强版的Numpy结构化数组
行和列不在只是简单的整数索引,还可以带上标签,
- 三个基本数据结构
Series DataFrame Index
Series
Series将一组数据和一组索引绑定在一起
可以通过values 和 index属性获取数据,
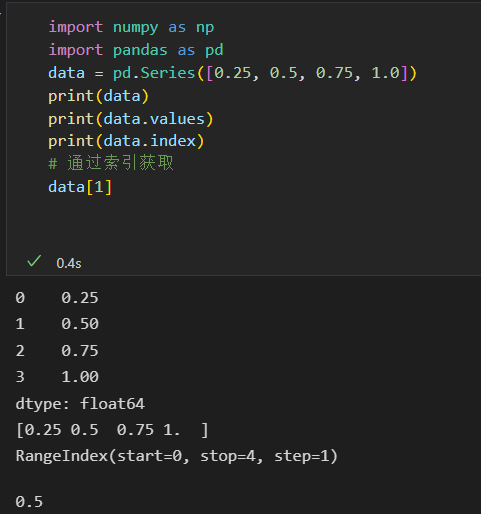
与Numpy数据的区别:Numpy数组通过隐式定义的整数索引获取数值,Pandas 的Series用显示定义的索引与数值关联
Series是特殊的字典
字典是一种将任意键映射到一组任意值的数据结构
Series对象是一种将类型键映射到一组类型值 的数据结构, 类型至关重要。
因为有类型信息,所以比Python字典更高效
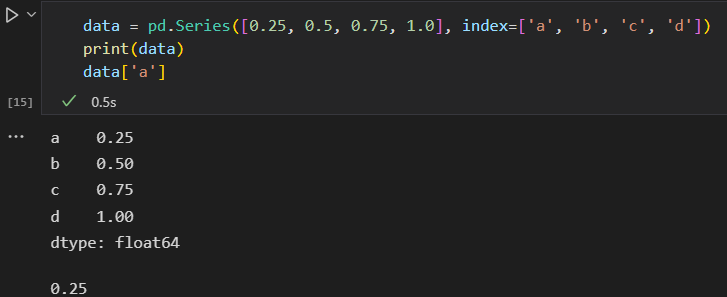
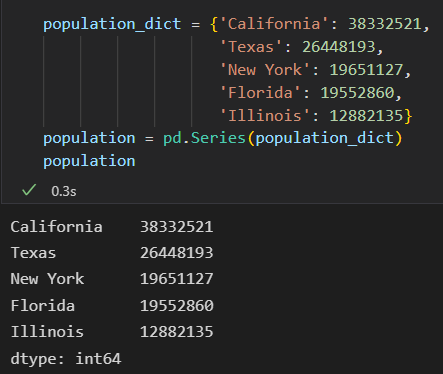
可以直接使用Python字典创建一个Series对象
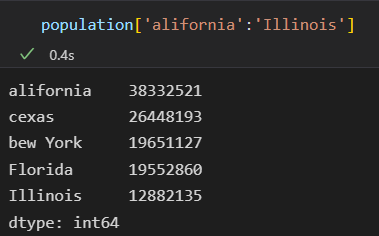
- 和字典不同,Series对象还支持数组形式的操作
创建Series对象
pd.Series(data, index=index)
index是一个可选参数,data参数支持多种数据类型, 可以是列表 或 Numpy数组, index默认值为整数序列
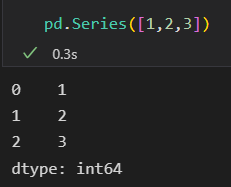
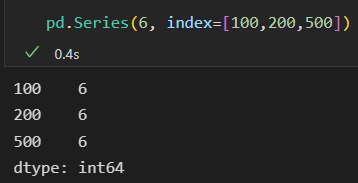
data可以是个标量,创建对象是会重复填充到每个索引上。
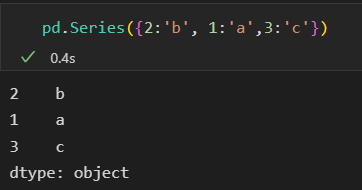
data可以是字典,索引是默认的,不排序,老版本的好像对index进行排序了。
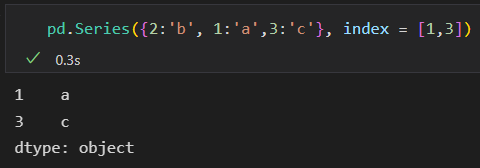
每一种形式都可以通过显示指定索引 筛选需要的结果
Pandas的DataFrame对象
也可以作为一个通用型的Numpy数组,也可以看做特殊的Python字典
DataFrame :通用的Numpy数组
Series是 有 灵活索引的一维 数组 , DataFrame是 一种 既有 灵活的行索引,又有灵活列名 的二维数组 。
DataFrame也可以看成 是若干个Series对象。。索引相同。

index属性获取索引标签

DataFrame还有一个columns属性, 是存放列标签的Index对象:
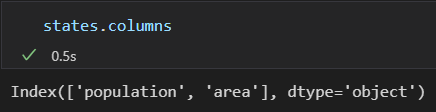
DataFrame :特殊的字典
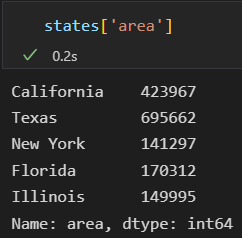
字典是一个键映射一个值,而DataFrame是 一个列名映射一个Series的数据。
创建DataFrame对象
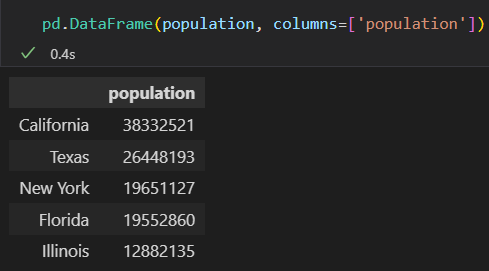
1)通过单个Series对象创建。DataFrame是一组Series对象的集合
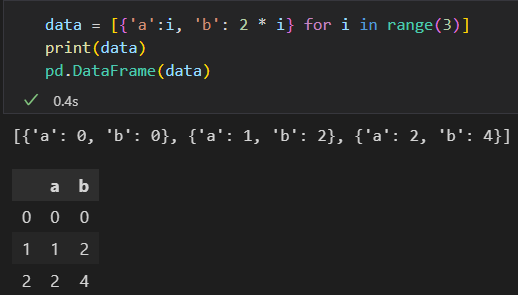
2)通过字典列表创建。 任何元素是字典的列表都可以变成DataFrame
3)通过Series对象常见,开始介绍那样子。
4)通过Numpy二维数组创建
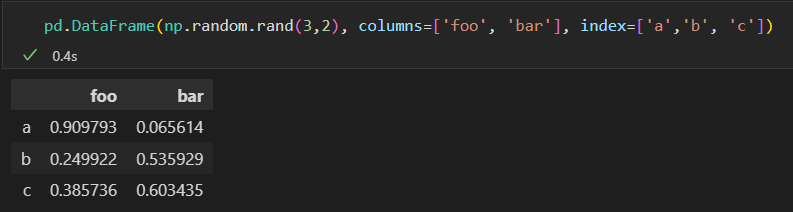
5)通过Numpy结构化数组创建
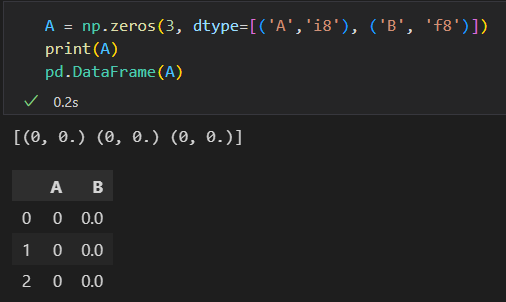
Pandas的Index对象
Series 和 DataFrame 对象都使用便于引用和调整的 显示索引。
Pandas的Index对象是一个很有趣的数据结构。 可以将它看作是一个 不可变数组 或 有序集合,
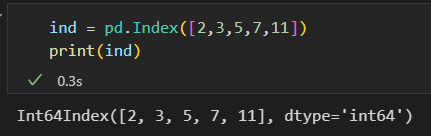
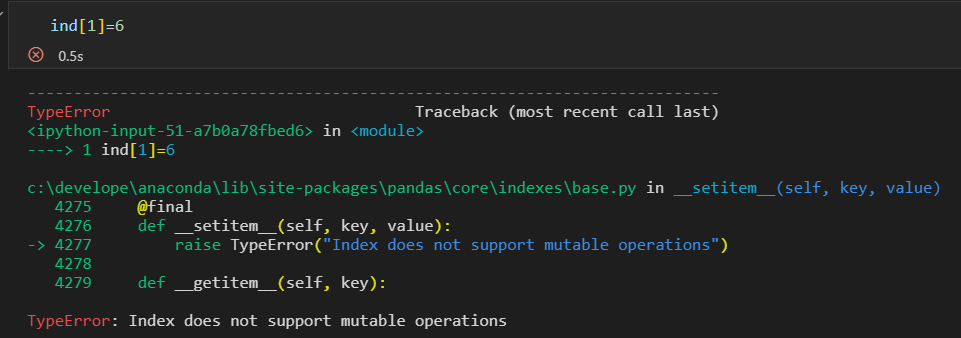
1)将Index看作不可变数组
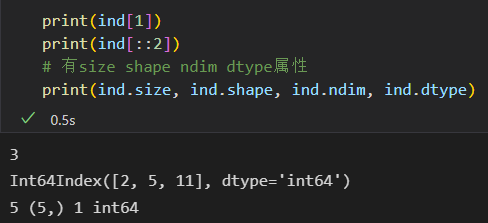
如果修改索引值会报错。对象的不可变性,使得多个DataFrame和数组之间进行索引共享是更加安全
2)将Index看作有序集合
Pandas对象被设计用于实现多操作。 如连接数据集。并集 交集 差集
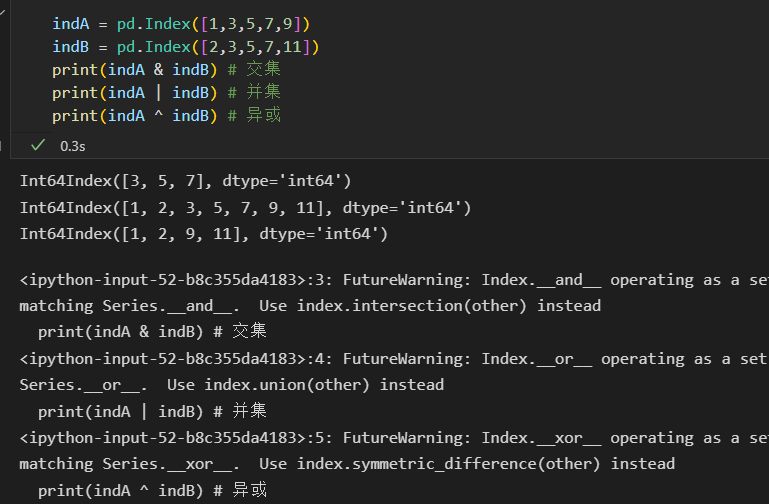
不过好像不推荐用这种方式了。哈哈
使用对象方法

Python数据科学手册-Pandas数据处理之简介的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- Java 常用Set集合和常用Map集合
目录 常用Set集合 Set集合的特点 HashSet 创建对象 常用方法 遍历 常用Map集合 Map集合的概述 HashMap 创建对象 常用方法 遍历 HashMap的key去重原理 常用Set ...
- Linux快捷方式创建模板
1.创建快捷方式文件 sudo gedit /usr/share/applications/Navicat.desktop 模板: [Desktop Entry] Name=Navicat Exec= ...
- 002面试题_Switch...case的数据
1.byte 2.short 3.int 4.char 5.String 6.枚举
- jdbc 11: 封装自己的jdbc工具类
jdbc连接mysql,封装自己的jdbc工具类 package com.examples.jdbc.utils; import java.sql.*; import java.util.Resour ...
- C#基础-面向对象详解
面向对象详解 一.什么是面向对象 1>面向对象是一种程序设计思想 2>面向过程和面向对象是什么? 例如要把大象放冰箱怎么做? 面向过程:打开冰箱门->把大象扔进去->关上冰箱门 ...
- 网易云UI模仿-->侧边栏
侧边栏 效果图 界面分解 可以看到从上到下的流式布局.需要一个Column来容纳,并且在往上滑动的过程中顶部的个人信息是不会动的.所以接下来需要将剩余部分占满使用Flexibel组件. 实现 个人信息 ...
- css基础06
精灵图就是只要导入一张照片(这张照片里面有很多很多的小图标和照片),然后通过background-position来移动位置,使网页显示出对应图片或者图标.一般都是负值. 下载然后导入项目里. 不同浏 ...
- linux常见命令搜集
查找根目录下txt和pdf文件 find / \( -name "*.txt" -o -name "*.pdf" \) -print 正则查找根目录下所有的tx ...
- 针对多个球体的World类
World类其他都一样的,就修改build函数就行了,以后测试所有代码,都是基于两个或多个球体的,不再重复阐述. void World::build() { vp.set_hres(200); vp. ...
- django中的静态文件
静态文件 1.什么是静态文件 在django中静态文件是指那些图片.css样式.js样式.视频.音频等静态资源. 2.为什么要配置静态文件 这些静态文件往往不需要频繁的进行变动,如果我们将这些静态文件 ...