R数据分析:扫盲贴,什么是多重插补
好多同学跑来问,用spss的时候使用多重插补的数据集,怎么选怎么用?是不是简单的选一个做分析?今天写写这个问题。
什么时候用多重插补
首先回顾下三种缺失机制或者叫缺失类型:

上面的内容之前写过,这儿就不给大家翻译了,完全随机缺失,缺失量较小的情况下你直接扔掉或者任你怎么插补都可以,影响不大的。随机缺失可以用多重插补很好地处理;非随机缺失,任何方法都没得救的,主分析做完之后自觉做敏感性分析才是正道;这个我好像在之前的文章中给大家解释过原因。
When it is plausible that data are missing at random, but not completely at random, analyses based on complete cases may be biased. Such biases can be overcome using methods such as multiple imputation that allow individuals with incomplete data to be included in analysesly, it is not possible to distinguish between missing at random and missing not at random using observed data. Therefore, biases caused by data that are missing not at random can be addressed only by sensitivity analyses examining the effect of different assumptions about the missing data mechanism
多重插补的思想
写多重插补之前我们先回忆简单插补,叫做single imputation,就是缺失值只插一个,无论是用均值,用中位数,用众数等等,反正只挑一个,只形成一个完整数据集,叫做简单插补。
这里面就有一个问题:就插了一个值,你怎么就敢说这个值对?是不是偏倚的可能性其实挺高的?
多重插补就不一样了,进行多重插补的时候我会对一个缺失值会插补很多个可能的值,我们会得到很多个完整的数据集(mutliple),比如每个缺失的地方我们插补5个值,就会得到5个数据集。这5个数据集的原来的缺失的数据都被算法插补好了,但是插补的值不尽相同,多重插补的思想精髓在于:对这插补出来的每一个数据集都做一遍我们的目标分析,然后将效应汇总从而得到误差最小的合并效应。
现在给出多重插补的定义(来自BMJ):
Multiple imputation is a general approach to the problem of missing data that is available in several commonly used statistical packages. It aims to allow for the uncertainty about the missing data by creating several different plausible imputed data sets and appropriately combining results obtained from each of them.
具体的思路就是,首先插补多个数据集,就是每个缺失的地方会插补多次,每一次插补的值都是基于现有数据分布的缺失值的预测值;第一步做完之后我们不是有很多个完整数据集了嘛,然后我们将我们感兴趣的分析在每一个数据集中都做一次,得到多个结果;第三步就是将这些结果汇总。
以上就是思路流程。
In the first step, the dataset with missing values (i.e. the incomplete dataset) is copied several times. Then in the next step, the missing values are replaced with imputed values in each copy of the dataset. In each copy, slightly different values are imputed due to random variation. This results in mulitple imputed datasets. In the third step, the imputed datasets are each analyzed and the study results are then pooled into the final study result.
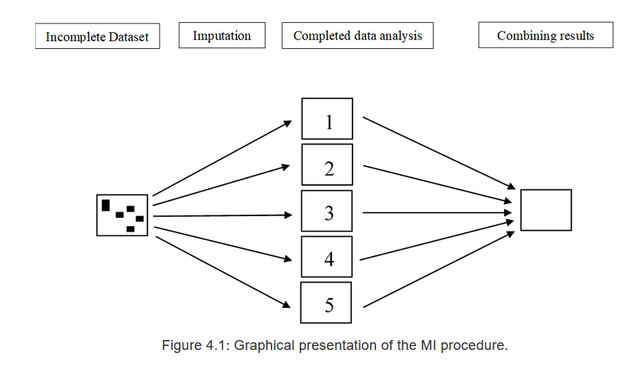
所以说如果你用多重插补处理缺失数据,分析的时候却只用某一个数据集来做分析肯定都是不正确的,所以以后千万别问,到底选哪个这样的问题了,选哪个都不对。
介绍完思想我们再看实操。
实例操练
在spss中的多重插补实操,大家请阅读下面的链接,写的很细哈:
https://bookdown.org/mwheymans/bookmi/multiple-imputation.html#:~:text=After%20multiple%20imputation%2C%20the%20multiple%20imputed%20datasets%20are,that%20separates%20the%20original%20from%20the%20imputed%20datasets.
今天我们写如何在R中进行多重插补
我现在有数据如下:
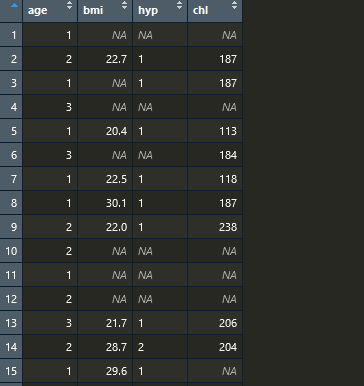
很简单的数据,可以看到数据中有很多缺失值的,我想要做的目标分析是一个以hyp为因变量的逻辑回归,如果我不插补数据直接做,可以写出如下代码:
model <- glm(hyp ~ bmi, family = binomial(link = 'logit'), data)
model_or <- exp(cbind(OR = coef(model), confint(model)))运行后得到想要的OR和置信区间如下:
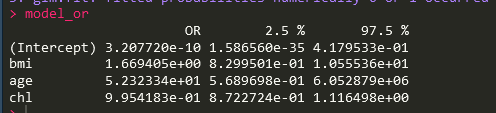
跑出来结果了,但是你要明白这个时候模型是默认将有缺失值的观测删掉的。结果不一定对。
现在我们对刚刚的数据集进行一个多重插补,需要用到mice函数,这个函数接受的参数如下:

其中重要的参数包括m,就是插补的完整数据集的个数;method就是插补的算法,这个就比较多了,常见如下:
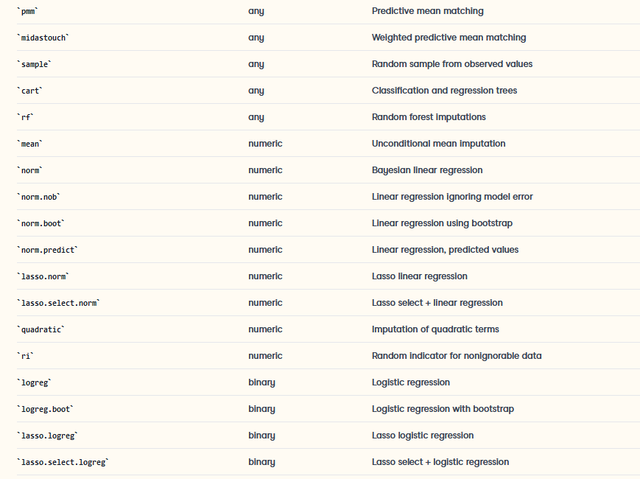
例如,我想对原始数据用pmm法进行多重插补,可以写出代码如下:
imputed_data <- mice::mice(data, m = 25, method = "pmm",
maxit = 10, seed = 12345, print = FALSE)运行上面代码插补自动完成,我们可以看到
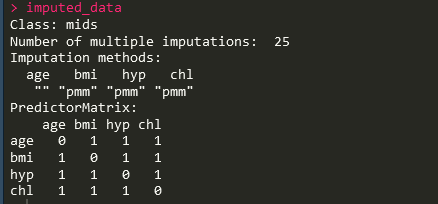
每一个变量都会作为其他变量的预测因子,同时每一个变量都会被其余所有变量所预测从而完成插补。插补完成后我们可以查看插补后的数据集,代码如下:
complete(imputed_data, action = "long", include = TRUE)最重要的一步是进行分析并进行效应合并,这个需要用到mice包中的with函数,可不是base包中的with函数,这个需要注意

这个with是专门用来帮助我们在插补后的数据集中目标分析的函数,刚刚写到我的目标分析是要做一个以hyp为因变量的逻辑回归,此时对于插补后的数据,可以写出代码如下:
imputed_model <- with(imputed_data,
glm(hyp ~ bmi+age+chl, family = binomial(link = 'logit')))得到结果如下:
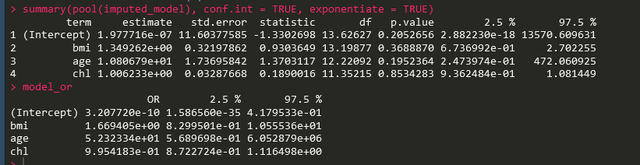
上图中上面是插补后的逻辑回归的结果,下图是之前没有插补的时候逻辑回归的结果,可以看到差异还是蛮大的。
多重插补的报告
对于多重插补的结果报告,BMJ也给了指南:

完整文章如下,大家可以自己去阅读:
Sterne J A C, White I R, Carlin J B, Spratt M, Royston P, Kenward M G et al. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls BMJ 2009; 338 :b2393 doi:10.1136/bmj.b2393
其中的重点就是要报告用的啥软件进行的多重插补,补了几个数据集,补的时候用了哪些变量,非正态分布变量和分类变量用的什么method补的,如果目标分析有交互,补的时候考虑交互没有;补的数据如果 太多,补与不补的个案需要对比的;还有建议对缺失机制做一个讨论。
以上就是今天给大家介绍的多重插补的内容。
R数据分析:扫盲贴,什么是多重插补的更多相关文章
- R语言︱缺失值处理之多重插补——mice包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:缺失值是数据清洗过程中非常重要的问题 ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- R数据分析:用R建立预测模型
预测模型在各个领域都越来越火,今天的分享和之前的临床预测模型背景上有些不同,但方法思路上都是一样的,多了解各个领域的方法应用,视野才不会被局限. 今天试图再用一个实例给到大家一个统一的预测模型的做法框 ...
- 菜鸟学四轴控制器之3:数字积分法DDA实现直线插补
上一篇的逐点比较法显然是无法画一条有倾角的直线的.因为X轴和Y轴永远都不同步,也就是像打台球一样,你打一个,我打一个,如果我进了球,我再接着打一个. 也就是说,如果直线为45度,也是没有办法画出来的, ...
- 倍福TwinCAT(贝福Beckhoff)应用教程13.2 TwinCAT控制松下伺服 NC自定义直线插补
对于MOVEJ的关节运动来说,我们只关心每个电机的角度(只需要考虑多个电机协同开始运动和结束运动,关键是对每个电机加速度均一化,从而一起跑一起停,这部分内容可以参考机器人学导论以获取更加详细的说明), ...
随机推荐
- z—libirary最新地址获取,zlibirary地址获取方式,zliabary最新地址,zliabary官网登录方式,zliabary最新登陆
Z-Library(缩写为z-lib,以前称为BookFinder)是Library Genesis的镜像,一个影子图书馆项目,用于对学术期刊文章.学术文本和大众感兴趣的书籍(其中一些是盗版的)进行文 ...
- Go语言知识查漏补缺|基本数据类型
前言 学习Go半年之后,我决定重新开始阅读<The Go Programing Language>,对书中涉及重点进行全面讲解,这是Go语言知识查漏补缺系列的文章第二篇,前一篇文章则对应书 ...
- C++工厂方法模式讲解和代码示例
在C++中使用模式 使用示例: 工厂方法模式在 C++ 代码中得到了广泛使用. 当你需要在代码中提供高层次的灵活性时, 该模式会非常实用. 识别方法: 工厂方法可通过构建方法来识别, 它会创建具体类的 ...
- Mac隔空投送功能
使用mac 或iphone 的隔空投送功能可以互发文件,亲测可用 具体可以看mac的文档 需要注意的是: 如果是mac传iphone,iphone会显示你需要存储文件的地方,比如选择在文稿中.然后在文 ...
- 运维利器-ClusterShell
前言 和ansible类似,但是更加高效 安装 yum install -y clustershell clush命令: clush -a 全部 等于 clush -g all clush -g 指定 ...
- setw()
setw() 头文件是 #include<iomanip> setw(2)是下一个数据输出宽度为2,超过2则以实际输出为准,不足2补空格.仅对下一个数据的输出有效,即只有一次效果.(set ...
- Java安全之freemaker模版注入
Java安全之freemaker模版注入 freemaker简介 FreeMarker 是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等 ...
- 类似微信聊天小程序-网易云信,IM DEMO小程序版本
类似微信聊天小程序-网易云信,IM DEMO小程序版本 代码地址: https://github.com/netease-im/NIM_Web_Weapp_Demo 云信IM DEMO 小程序版本 ( ...
- JS 模块化 - 02 Common JS 模块化规范
1 Common JS 介绍 Common JS 是模块化规范之一.每个文件都是一个作用域,文件里面定义的变量/函数都是私有的,对其他模块不可见.Common JS 规范在 Node 端和浏览器端有不 ...
- Elasticsearch:如何调试集群状态 - 定位错误信息
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/108973356