TINY语言采用递归下降分析法编写语法分析程序
参考来源:聊聊编译原理(二) - 语法分析
自顶向下分析方法
自顶向下分析方法:递归下降分析法,LL1分析法。其实本质上核心思想是一样的,也就是LL,从左至右,最左推导,因而我觉得其实可以把前一个称为LL0分析法,即不使用向前看符号,这也是他们的不同点,具体实现不同罢了,递归下降需要用回溯和分治,调用递归函数,因为递归调用,耗费时间当然要长一点,而LL1使用first和follow函数(当然前者也用到了)创建了一个预测分析表,可以知道,这个算法不需要再去遍历尝试每一种语法树组合,而是根据表肯定能选出最优的组合去匹配,这也就是典型的牺牲空间换时间的算法。
TINY文法

为简单起见,丢弃了read和write语句(但实际上也就加两条语法的问题,可直接补充)
program -> stmt-sequence
stmt-sequence -> stmt-sequence;statement | statement
statement -> if-stmt | repeat-stmt | assign-stmt //丢弃了读写语句
if-stmt -> if exp then stmt-sequence end //条件语句
| if exp then stmt-sequence else stmt-sequence end
repeat-stmt -> repeat stmt-sequence until exp //循环语句
assign-stmt -> id := exp //赋值语句
exp -> simple-exp compar-op simple-exp | simple-exp //算数表达式
compar-op -> < | =
simple-exp -> simple-exp add-op term | term
add-op -> + | -
term -> term mul-op factor | factor
mul-op -> * | /
factor -> ( exp ) | number | id
消左提左、构造first follow



基本思想
- 为每个非终结符构造一个分析函数
- 用前看符号指导产生式规则的选择
第一点简单来说就是A -> Bc B -> d
构造函数A(),B()
第二点即是说会用到first(A)和first(B) 即上图中的红色部分
python构造源码
对于文法来说分三种情况
- A -> B C
没有其他的终结符和|,则直接调用两个产生式右部的非终结符函数
如: stmt-sequence -> statement ST

- A -> B | C
存在 | ,则需要看A的first,| 等价于if-else,所以需要看first(A)的结果去分类判断该调用哪个非终结符函数,同时,这里需要putback,因为这个token是多读的,需要将指针调回去
如:statement -> if-stmt | repeat-stmt | assign-stmt
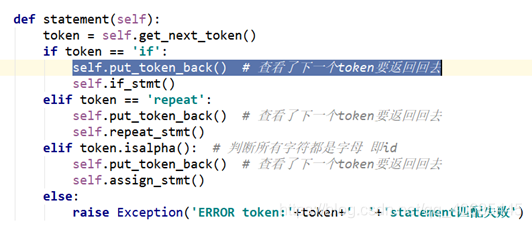
- A -> B |
存在 空,则需要回溯,因为A可以在此不做任何事情,因而读取的token不满足first(B)时,则同样需要putback,将指针倒回去重新读取token
如:ST -> ;statement ST |

主要函数:
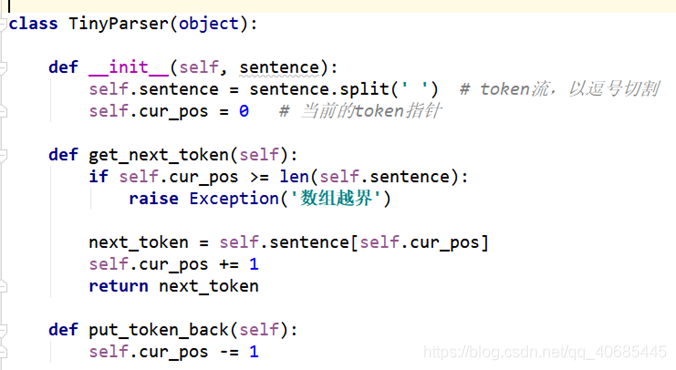
- 基本的函数定义
init初始化函数,得到已经特意写好的token流,指针位置初始化为0
get_next_token 得到下一个token
put_token_back 回溯上一个token
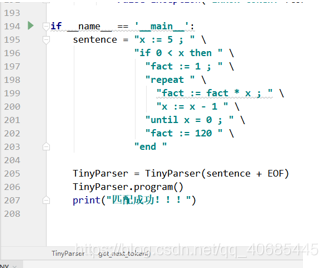
- main函数
预置好了token流,用空格分开,因为上面init是根据空格切开为数组的
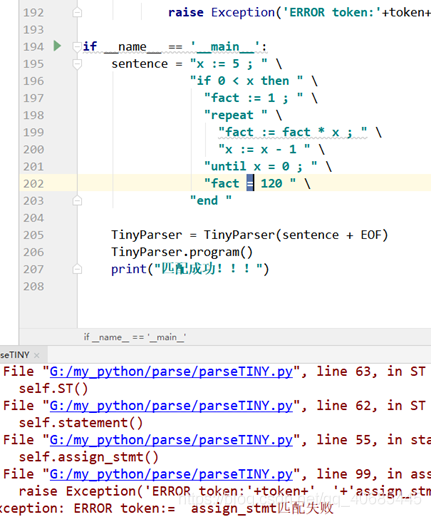
匹配过程中如果有错误,会直接抛出异常,则程序是不会走到最后的print的,故输出匹配成功了则是匹配无误
- 非终结符函数
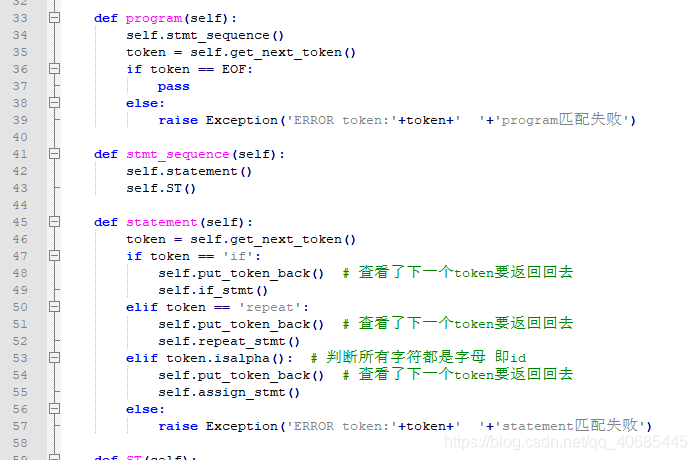


运行结果
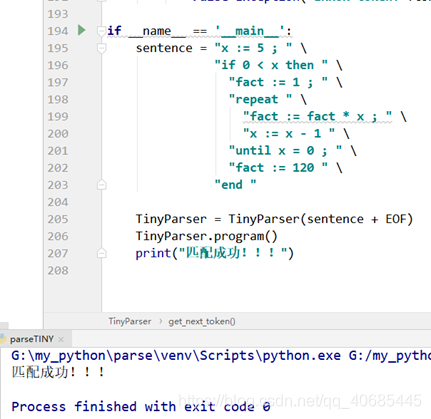
故意改错语法 tiny语言赋值语法为’ := ’ 而非’ = ’
完整源码:parseTINY
TINY语言采用递归下降分析法编写语法分析程序的更多相关文章
- 编译原理-递归下降分析法 c程序部分的分析
实验三 语法分析程序实验 专业 商软2班 姓名 黄仲浩 学号 201506110166 一. 实验目的 编制一个部分文法分析程序. 二. 实验内容和要求 输入:源程序字符串 输出:正确 ...
- Tiny语法分析器(递归下降分析法实现)
递归规约规则是这样的 program→stmt-sequence stmt-sequence→stmt-sequence;statement|statement statement→if-stmt|r ...
- 编译原理 #02# 简易递归下降分析程序(js实现)
// 实验存档 截图: 代码: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
- 作业十一——LL(1)文法的判断,递归下降分析程序
作业十一——LL(1)文法的判断,递归下降分析程序 判断是否为LL(1)文法 选取有多个产生式的求select,只有一条产生式的无需求select 同一个非终结符之间求交集,全部判断为空后则为LL(1 ...
- 递归下降和LL(1)语法分析
什么是自顶向下分析法 在语法分析过程中一般有两种语法分析方法,自顶向下和自底向上,递归下降分析和LL(1)都属于是自顶向下的语法分析 自顶向下分析法的过程就像从第一个非终结符作为根节点开始根据产生式进 ...
- 十一次作业——LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
- LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da | ε (3)B -> cC (4)C -> aADC | ε (5)D -> b | ε 验证文法 G ...
- 编译原理之LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
- 第十一次作业 LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
随机推荐
- 报错----运行springboot项目出现:Type javax.xml.bind.JAXBContext not present
目的:运行springboot项目出现:Type javax.xml.bind.JAXBContext not present 环境: 问题:运行springboot项目出现:Type javax.x ...
- Spring AOP调用本类方法为什么没有生效
首先请思考一下以下代码执行的结果: LogAop.java //声明一个AOP拦截service包下的所有方法@Aspectpublic class LogAop { @Around("ex ...
- hashlib 模块 摘要算法
应用于用户登陆,对密码进行加密操作, #文件操作 # hashlib 摘要算法 #md5 算法: 是32位的16进制组成的数字字符组成的字符串 #应用最广的摘要算法 #效率高,相对不复杂,如果只是传统 ...
- 项目构建工具之maven01
Maven 是一个项目管理工具,可以对 Java 项目进行构建.依赖管理.Maven 也可被用于构建和管理各种项目,例如 C#,Ruby,Scala 和其他语言编写的项目.Maven 曾是 Jakar ...
- luoguP4383 [八省联考2018]林克卡特树(树上dp,wqs二分)
luoguP4383 [八省联考2018]林克卡特树(树上dp,wqs二分) Luogu 题解时间 $ k $ 条边权为 $ 0 $ 的边. 是的,边权为零. 转化成选正好 $ k+1 $ 条链. $ ...
- 羽夏看Win系统内核——调试篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- springboot项目配置类
一.在springboot项目中,如果不进行配置,直接访问静态页面是无法访问的,需要进行配置,springboot舍弃了XML文件的配置方式,这里我们采用开发配置类的方式.新建MvcConfig类,加 ...
- abstract的method是否可同时是static,是否可同时是native,是否可同时是synchronized?
abstract的method 不可以是static的,因为抽象的方法是要被子类实现的,而static与子类扯不上关系! native方法表示该方法要用另外一种依赖平台的编程语言实现的,不存在着被子类 ...
- PowerDesigner生成MySQL脚本,表和字段进行转义
打开Power Designer数据库建模工具,软件基本信息如下 如果PowerDesigner内置的(table_option)表物理操作没有,请看以下步骤 打开 Edit Current DBMS ...
- 使用 Spring 框架的好处是什么?
轻量:Spring 是轻量的,基本的版本大约 2MB.控制反转:Spring 通过控制反转实现了松散耦合,对象们给出它们的依 赖,而不是创建或查找依赖的对象们.面向切面的编程(AOP):Spring ...