三分钟速览GPT系列原理
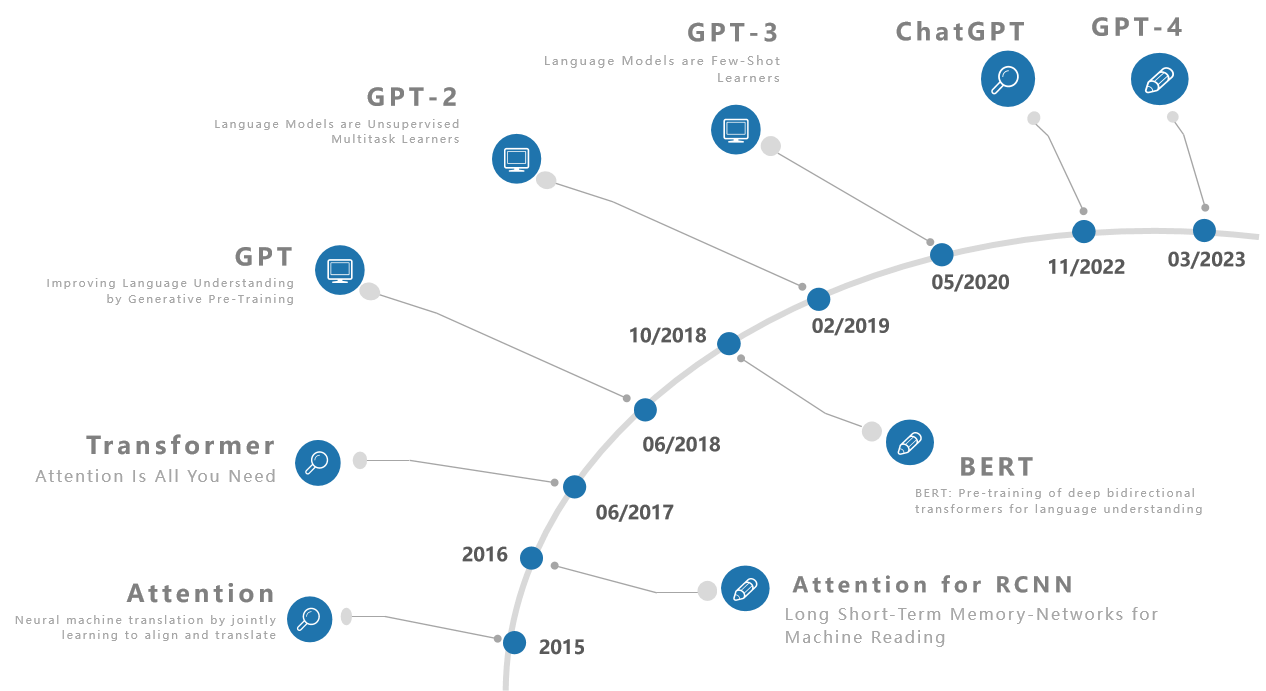
其中,Transformer和BERT来自Google,GPT系列【GPT、GPT-1、GPT-2、GPT-3、ChatGPT、GPT-4】来自OpenAI。
GPT
Paper名为Improving Language Understanding by Generative Pre-Training,通过生成式预训练模型来提高语言理解。
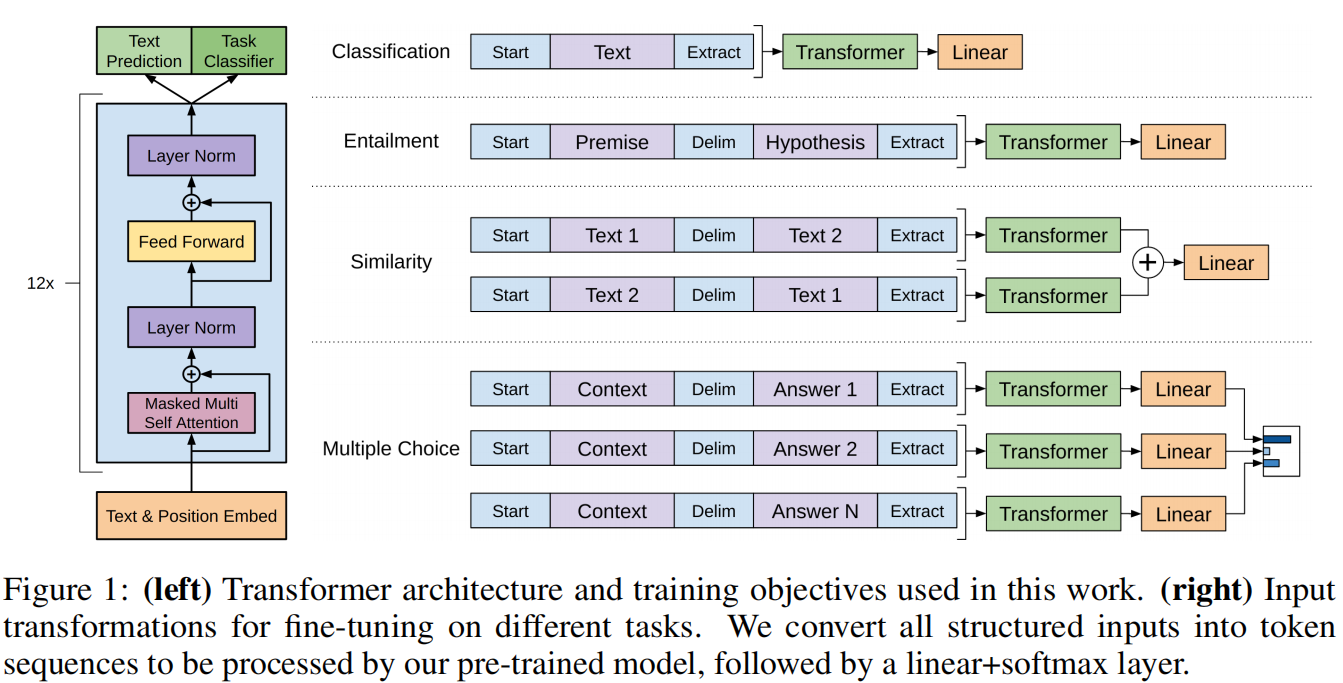
- GPT,将Transformer的Decoder拿出来,在大量没有标注的文本数据上进行训练,得到一个大的预训练的语言模型。然后再用它在不同子任务上进行微调,最后得到每一个任务所要的分类器。
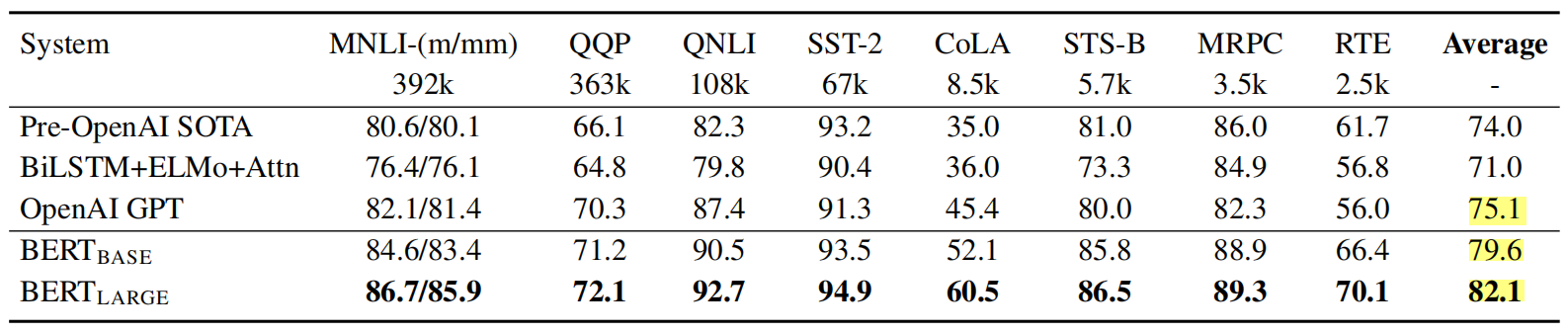
- BERT虽然大家更为熟知,但其实发布晚于GPT,是将Transformer的Encoder拿出来,收集了一个更大的数据集做训练,取得了比GPT好很多的效果。BERT给了BERT-Base和BERT-Large两个模型,BERT-Base的模型大小与GPT相当,效果更好,BERT-large模型更大数据效果也更好,下图是BERT论文[1]中给出的一组对比数据。
我们知道,BERT中使用(1)扣取某个单词,学习完形填空(2)判断是否为下一句来学习句子的相关性,两个任务来使用海量数据进行训练。
在GPT中,训练分为无监督的预训练和有监督的微调,无监督的预训练使用标准语言模型,给定前i-1个单词,预测第i个单词;有监督的微调使用标准交叉熵损失函数。
针对不同的任务,只需要按照下列方式将其输入格式进行转换,转换为一个或多个token序列,然后送入Transformer模型,后接一个任务相关的线性层即可。
GPT-2
之前,大家倾向于为每个任务收集单独的数据集(single task training on single domain datasets),OpenAI在这篇文章中使用了zero-shot的设定来解决下游任务。
We demonstrate language models can perform down-stream tasks in a zero-shot setting -- without any parameters or architecture modification.
GPT的时候,针对不同的任务构造不同的输入序列进行微调,这里直接使用自然语言的方式训练网络并可以使用到不同的任务上去。
例如,对于一个机器翻译任务的训练样本【translation training example】为:
translate to french, english text, french text
对于阅读理解训练样本【reading comprehension training example】:
answer the question, document, question, answer
这种方法并不是作者首提的,但是作者将其用到了GPT的模型上,并取得了一个相对的效果【如果没有GPT-3的惊艳效果,估计它也就是一个不怎么被人所知的工作了】。
从GPT-2开始不再在子任务上做微调,直接使用预训练模型进行预测,这个是很牛掰的。
GPT-3
GPT-3基于GPT-2继续做,GPT-2有1.5Billion【15亿】的参数量,GPT-3做到了175Billion【1750亿】的参数量。
Specififically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specifified purely via text interaction with the model.
摘要中这里详述了,GPT-3参数量翻了10倍,同时推理的时候使用了few-shot。对于所有的子任务,都不进行梯度更新,而是纯使用few-shot的形式改变输入。
Finally, we find that GPT-3 can generate samples of news articles which human evaluators have diffificulty distinguishing from articles written by humans.
GPT-3取得了非常经验的效果,已经能够写出人类无法分辨真假的假新闻。
这里详述一下zero-shot、one-shot、few-shot:
- zero-shot:推理时,输入包含:任务描述 + 英文单词 + prompt[=>]
- one-shot:推理时,输入包含:任务描述 + 一个例子 + 英文单词 + prompt[=>]
- few-shot:推理时,输入包含:任务描述 + 多个例子 + 英文单词 + prompt[=>]

Reference
[1] Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In ACL, 2019.
[2] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under standing with unsupervised learning. Technical report, OpenAI. [GPT]
[3] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. [GPT-2]
[4] Brown, Tom B. et al. “Language Models are Few-Shot Learners.” ArXiv abs/2005.14165 (2020): n. pag. [GPT-3]
[5] 沐神 GPT,GPT-2,GPT-3 论文精读【论文精读】
三分钟速览GPT系列原理的更多相关文章
- js基础进阶--图片上传时实现本地预览功能的原理
欢迎访问我的个人博客:http://www.xiaolongwu.cn 前言 最近在项目上加一个图片裁剪上传的功能,用的是cropper插件,注意到选择本地图片后就会有预览效果,这里整理一下这种预览效 ...
- 4. OpenAI GPT算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
- faster-rcnn系列原理介绍及概念讲解
faster-rcnn系列原理介绍及概念讲解 faster-rcnn系列原理介绍及概念讲解2 转:作者:马塔 链接:https://www.zhihu.com/question/42205480/an ...
- socket 由浅入深系列------ 原理(一)
来自:网络整理 个人觉得写一个网络应用程序没有是一件非常easy的事.其实,我们刚開始的时候总觉得的原则: 建立------>连接套接字------->接受一个连接---->发送数据 ...
- java并发编程系列原理篇--JDK中的通信工具类Semaphore
前言 java多线程之间进行通信时,JDK主要提供了以下几种通信工具类.主要有Semaphore.CountDownLatch.CyclicBarrier.exchanger.Phaser这几个通讯类 ...
- Java中map集合系列原理剖析
看了下JAVA里面有HashMap.Hashtable.HashSet三种hash集合的实现源码,这里总结下,理解错误的地方还望指正 HashMap和Hashtable的区别 HashSet和Hash ...
- [目标检测]RCNN系列原理
1 RCNN 1.1 训练过程 (1) 训练时采用fine-tune方式: 先用Imagenet(1000类)训练,再用PASCAL VOC(21)类来fine-tune.使用这种方式训练能够提高8个 ...
- Hive基础语法5分钟速览
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- Linux和Shell回炉复习系列文章总目录
本页内容都是本人回炉Linux时整理出来的.这些文章中,绝大多数命令类内容都是翻译.整理man或info文档总结出来的,所以相对都比较完整. 本人的写作方式.风格也可能会让朋友一看就恶心到直接右上角叉 ...
- 2. Attention Is All You Need(Transformer)算法原理解析
1. 语言模型 2. Attention Is All You Need(Transformer)算法原理解析 3. ELMo算法原理解析 4. OpenAI GPT算法原理解析 5. BERT算法原 ...
随机推荐
- Day12-面向对象初识
面向对象编程 Java的核心思想就是OOP 一.面向过程&面向对象 面向过程思想: 步骤清晰简单,第一步做什么,第二步做什么...... 面对过程适合处理一些较为简单的问题 面向对象思想: 物 ...
- GPS时钟之户外防水防雷细节
GPS时钟之户外防水防雷细节------专业LED时钟厂家![点击进入] GPS的脆弱性: 由于在GPS设计时,干扰环境下的工作能力不是优先考虑的因素,它只是作为一种导航的辅助工具,而不是用于精确制导 ...
- vue 数组对象去重
unique(arr) { const res = new Map(); return arr.filter((arr) => !res.has(arr.id) &&am ...
- CAD2023卸载方法,如何完全彻底卸载删除清理干净cad各种残留注册表和文件?【转载】
cad2023卸载重新安装方法,使用清理卸载工具箱完全彻底删除干净cad2023各种残留注册表和文件.cad2023显示已安装或者报错出现提示安装未完成某些产品无法安装的问题,怎么完全彻底删除清理干净 ...
- WebStorm 2021.3 的永久激活教程
关注公众号回复 webstorm 即可获取激活脚本和教程 更新时间 2022年9月2日. 不定时更新 激活码可在公众号中回复[激活码]获取.
- Verilog中的时间尺度与延迟
在Verilog的建模中,时间尺度和延迟是非常重要的概念,设置好时间尺度和延迟,可以充分模拟逻辑电路发生的各种情况和事件发生的时间点,来评估数字IC设计的各种要求,达到充分评估和仿真的作用.注意延迟语 ...
- 许可协议 :GPL、BSD、MIT、Mozilla、Apache和LGPL
原文摘自:https://blog.csdn.net/testcs_dn/article/details/38496107 首先借用有心人士的一张相当直观清晰的图来划分各种协议:开源许可证GPL.BS ...
- 龙中华著《Spring Boot实战派》读书笔记之入门篇
第一章 进入Spring Boot的世界 理念:默认大于配置.有很多集成好的方案,开箱即用.针对痛点:环境配置耗时. 1.1 Spring Boot 的特色: 使用简单 注解方式实现类的定义和功能开发 ...
- 1js 高级
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- webpack配置跨域proxy
首先新建一个项目: 安装vue-cli: npm i -g @vue/cli npm i -g @vue/cli-init 安装webpack: npm install webpack -g vue新 ...