Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间。这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBERT给出的方案,看作者这两篇paper是一个组的作品,所以彼此之间也有一些共同点~
RoBERTa
RoBERTa与其说是一个新模型,更像是一个篇炼丹手札( ˘•ω•˘ )。作者针对BERT预训练中的几个超参数进行了测试,给出了更好的方案。相信你一定也在不少paper里都看到过“训练方案参考RoBERTa,此处省略1K字”之类的,RoBERTa主包括以下几点改良
- 更大的batch size
- 更多的训练数据,训练更多的epochs
- 使用一个长文本替代BERT的两段短文本, 并剔除NSP任务
- Dynamic MASK
更大的batch size
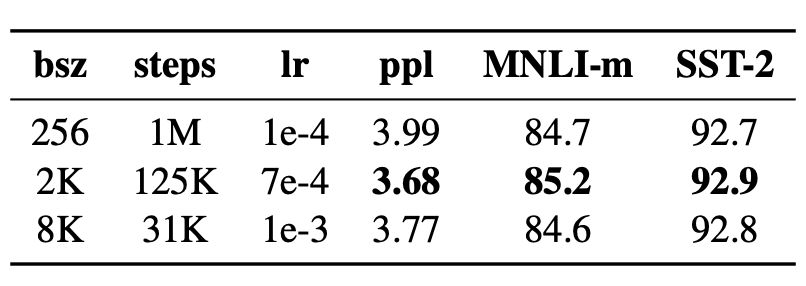
RoBERTa对batch size进行了参数调优,发现增加batch size可以有效提高MLM任务,以及下游迁移任务的效果。batch size越大,能更高的利用并行计算加速训练,以及batch之间的gradient波动越小越平滑,更容易拟合,当然也会有更高的内存占用,以及过于平滑的梯度可能会导致模型快速收敛到局部最优的问题。
对比结果如下,作者控制了相同的训练数据和epochs,增加batch size并相应的对lr进行调优,最终考虑到训练效率没有选择表现略好的2K而是用8K作为batch size。
看到这里其实有一些疑惑,因为平时训练很少用到如此大的batch size,虽然样本确实很大,但是控制batch size更多是考虑到batch太大会导致梯度过于平滑。个人感觉这里使用如此大的batch size,部分原因是MLM只对15%掩码的token计算loss,训练效率很低,更大的batch size一定程度上抵消了低效的掩码策略。
更多的TrainSample & Epochs
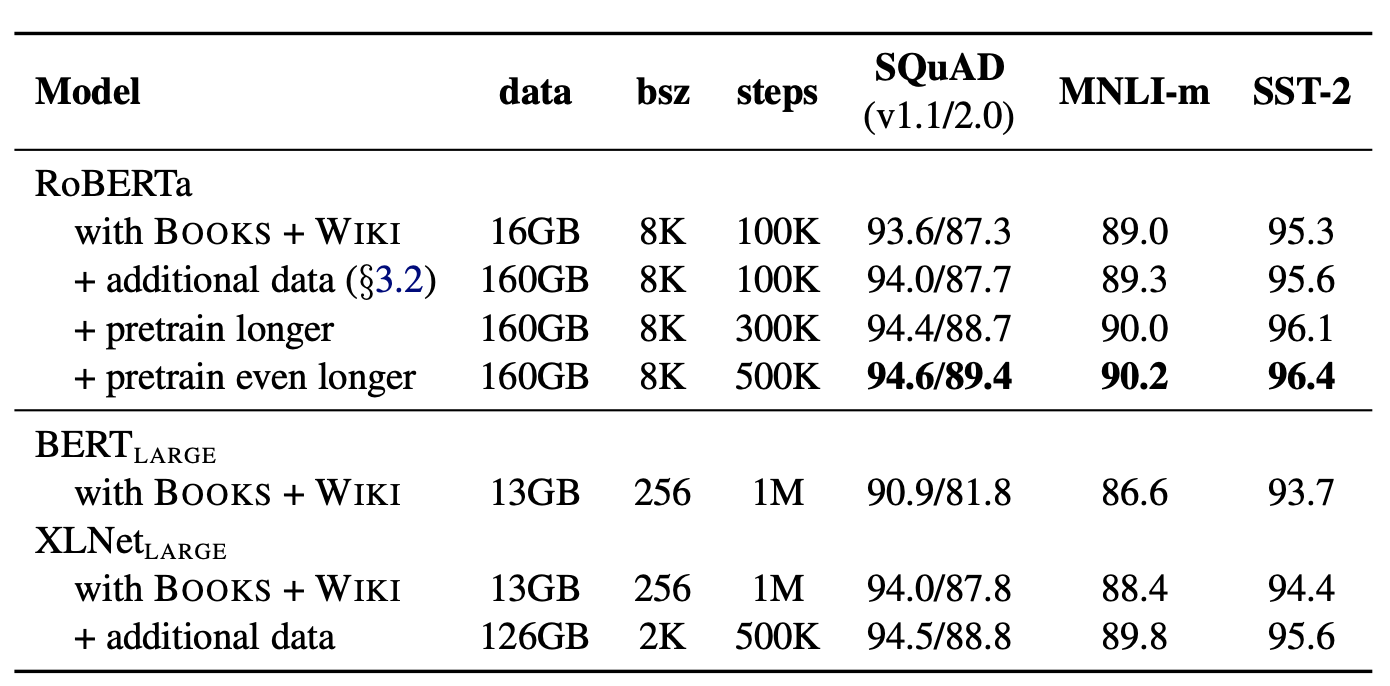
进一步佩服作者的耐心,这里作者清洗了160G的训练样本vs BERT(13G) vs XLNET(126G)。在BERT已经使用的BookCorpus和Wiki的基础上,加入了新闻CC-News,网页文本OpenWebTet,以及故事类文本Stories。
并一步控制变量进行测试,分别先增加样本量,再增加训练epochs。结论是在原始epochs上增加样本会带来效果提升,训练更多的epoches会进一步提升效果。其实也就是在BERT当前的参数量级下,我们可以用更多的样本塞进更多的文本信息,一定程度上可以说BERT其实是under fit的。NLP确实是一个大力可以出奇迹的领域。。。
NSP任务到底有用没用?
BERT除了捕捉双向文本信息的核心MLM任务之外,还使用了NSP任务。NSP其实比较早在Quick Thought里面就被提出了(不熟悉的童鞋看过来无所不能的Embedding5 - skip-thought的兄弟们[Trim/CNN-LSTM/quick-thought])。最初skip-thought这类文本表征模型,一般通过ENcoder-Decoder来进行建模,然后使用Encoder的Embedding作为句子表征。但这种训练方式比较低效,因为Decoder在推理中并不需要,以及Decoder的训练方式会导致文本表征过于关注表面文本信息。因此Quick-Thought直接丢掉了Decoder部分,把任务简化为通过文本表征判断两个文本是否是连续的上下文。
BERT这里借鉴了这个任务,来帮助学习文本关联关系,主要用于QA,NLI这类考虑文本间关联的任务。样本构建方式是50%正样本(A,B)是连续上下文,50%负样本(A,C)是从其他文本中随机采样得到。
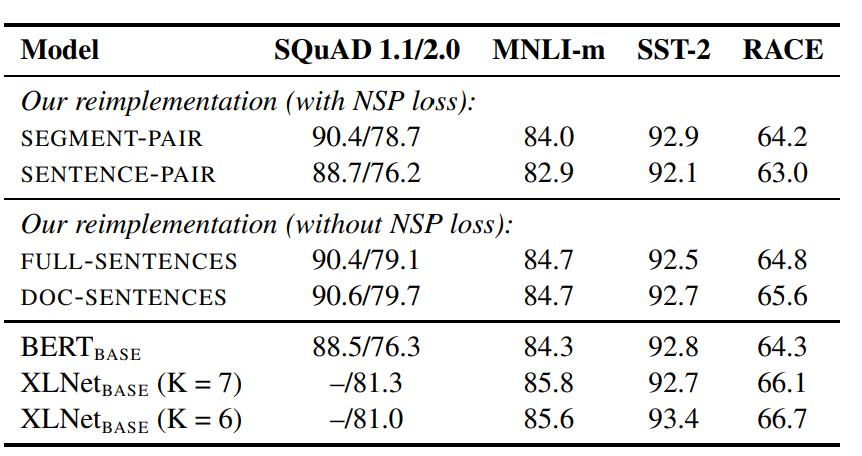
RoBERTa分别对比了4种方案
- Segment Pair + NSP:和BERT一致,segment包含多个句子,控制整体长度<512
- Sentence Pair + NSP: 只使用单个句子,因为长度会短很多,因此适当增加batch size,让每个batch的token和以上方案相似
- Full-Sentence:完整一段文本,允许跨document,只是在document之间加入sep,控制整体长度<512,不使用NSP Loss
- Doc-Sentences: 完整一段文本,不允许跨document,因为长度可能更短,所以动态增加batch size,不使用NSP Loss
对比结果如下
- 单句的效果显著比多个句子更差。作者认为这来自于单个句子影响模型学习长依赖的能力,以及我认为这里多个句子本身在MLM任务中也会学习句子间的关联性
- 移除NSP任务,并没有影响在NLI以及QA任务上的表现
- 使用一个文档内的文本效果略优于跨文档,不过实现起来略麻烦,因此RoBERTa最终还是选取了Full-Sentence的方案
虽然RoBERTa这里验证了移除NSP的效果并不比BERT差,不过我还不想这么快把NSP任务打入冷宫,感觉还有几个需要验证的点。第一NSP任务其实用了negative sampling对比学习的思路来学习文本表征,但是它构建负样本的方式是从其他文档中采样,过于easy因此容易导致模型偷懒通过学习主题信息来识别正负样本,感觉负采样这里存在优化空间。第二NSP任务作为二分类任务,比MLM本身要简单很多,所以二者的拟合速度存在比较大的差异,有可能MLM拟合的时候NSP已经过拟或者发生了塌陷。嘿嘿所以我个人还是对NSP无用持一定的怀疑态度~
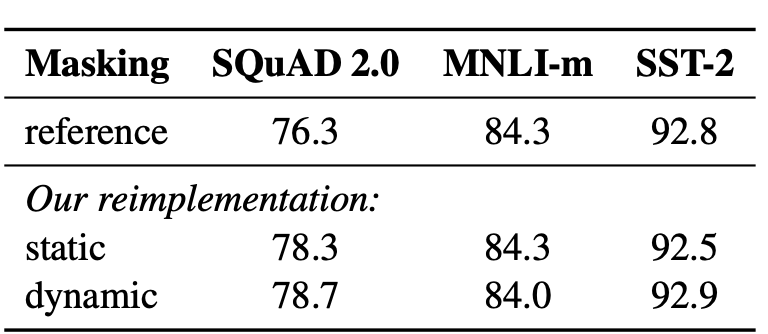
Dynamic MASK vs Static MASK
BERT本身的MASK策略是放在数据预处理阶段的,为了保证样本MASK在不同epoch的随机性。BERT是随机生成了10份不同MASK的样本,总共训练40个epoch,所以每份MASK样本会被用到4次。而RoBERTa把MASK放到了input pipe过程中,因此不需要预先生成多份样本,考虑以上RoBERTa使用更多的数据,训练更多的epoch。这个改良更多是面向工程实现上的内存优化,在效果上带来的收益并如下,并不非常显著~
SpanBERT
SpanBERT主要针对MASK策略进行优化,包括以下三点创新
- 基于几何分布采样的长度随机的Span Mask策略
- 针对Span MASK设计的损失函数Span Boundary Objective
- 训练策略优化:去掉NSP任务,用一个长句替代两个短句
Span Mask
针对Bert MASK是在subword粒度进行随机掩码,已经有不少的改良方案,包括Whole word MASK通过全词掩码来更好的引入词粒度信息,以及ERINE的knowledge masking通过实体&短语掩码引入知识信息等等
而SpanBERT给出了更加通用的掩码方案,基于几何分布\(l \sim Geo(p)\),每次随机生成MASK的长度,再按均匀分布随机生成掩码的位置,位置必须为完整token而非subwords。对于几何分布参数的选取作者选择了\(p=0.2\),并且限制了长度最长为10,这样平均掩码长度是3.8。
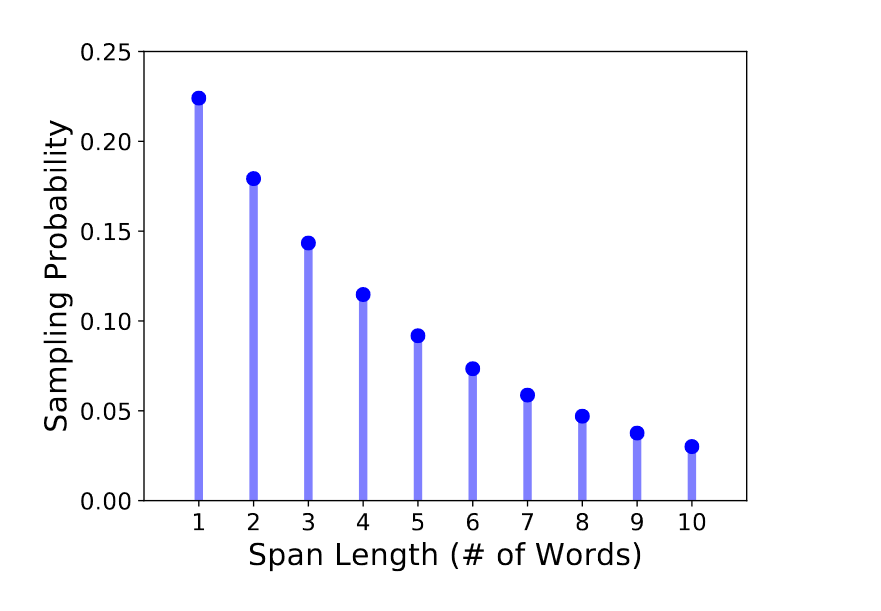
整体掩码的比例和策略Bert保持了一致都是15%,并且对其中80%的token使用MASK,10%用原始token替换,10%用随机token替换。以上策略针对span级别,如果使用MASK则整个span都会用MASK替换。
以下Whole Word Masking和knowledge Masking,其实都是Span Masking的一种特殊形式,只不过前两者强调MASK必须针对完整的词或者短语/实体,而Span Mask其实证明了随机连续掩码的效果更好。作者还通过更严谨的消融进行了验证,作者在原始Bert的预训练策略上,只改变MASK方式,对比whole word,entity,名词的掩码,整体上还是随机长度连续掩码的效果最好~~

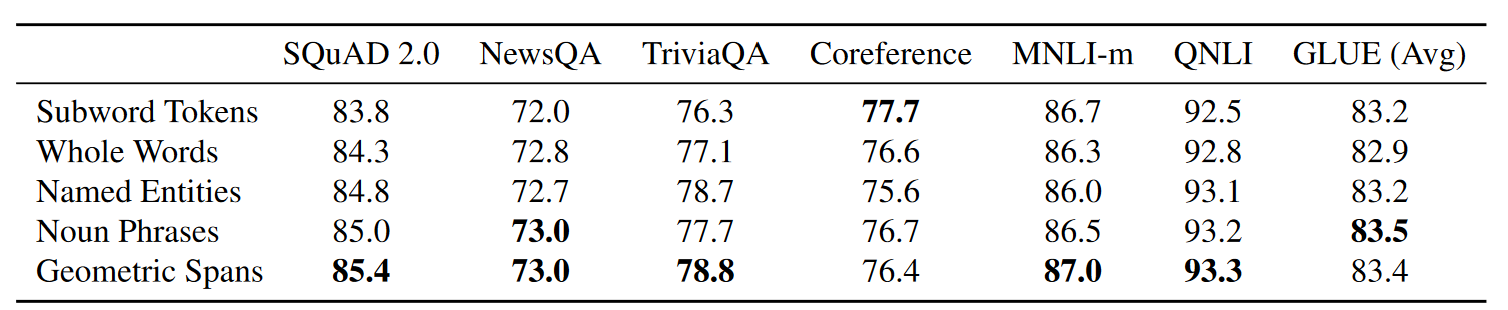
感觉这里的增益部分可能来自最大长度为10的几何分布相比词/短语遮盖长文本的概率更大,如果在随机长度掩码的基础上,保证掩码的边界是完整的词边界,是不是效果还会有提升嘞????
Span Boundary Obejctive
针对以上的掩码策略,作者也提出了新的训练目标。我带着自己的预期去看的这部分,结果发现和作者的设计完全不一样哈哈~本以为是一个Span级别的Cross Entropy来加强对Span内token联合概率的学习,结果作者设计的loss有比较强的针对性,主要面向span抽取任务
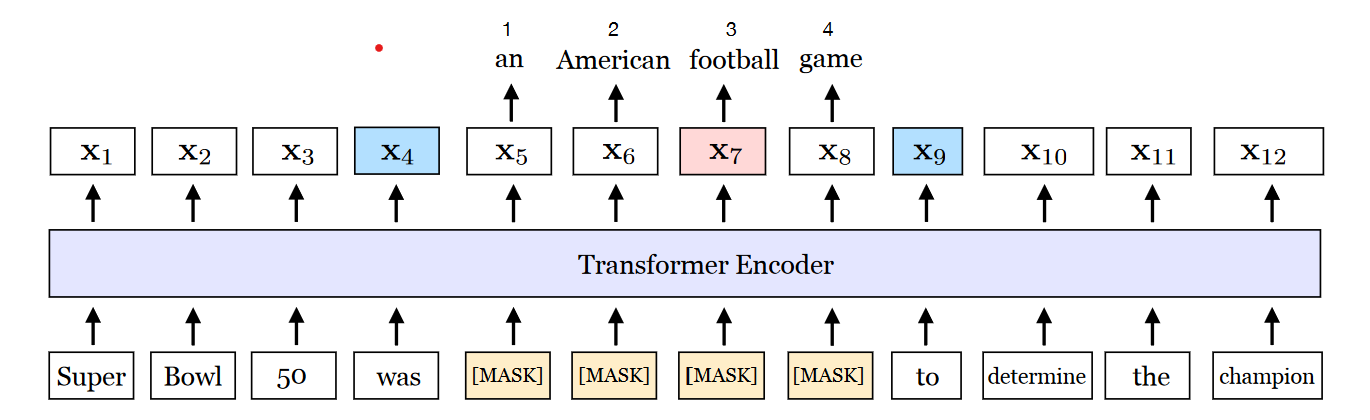
如上图,针对被MASK的部分\((x_s,...x_e) \in Y\),其中(s,e)是span的左右边界,作者在Transformer的Encoder Output上增加了一层变换\(f(\cdot)\)来预测Span内token。
\]
其中\(f(\cdot)\)是两层激活函数为Gelu的全连接层,并且加入了LayerNorm。预测的输入是Span的左右边界token,以及span内部的相对位置编码。SBO的核心是在更新全局信息的同时,span边界的token进行额外的更新,帮助他们学习和Span内部的语义交互,感觉会让每个token有机会学到更加丰富的语义表达,避免在全局交互时每个token学到的信息被稀释。整体损失是MLM和SBO的损失之和,对应上图football的损失函数为
L(football) &= L_{MLM}(football) + L_{SBO}(football) \\
&=-logP(football|x_7) -logP(football|x_4,x_9,p_3)
\end{align}
\]
在消融实验中SBO提升比较显著的是指代消歧任务和QA,其他任务感觉效果效果不大~所以如果你的下游迁移任务是span 抽取/理解类的,SpanBert可以考虑下哟~

训练策略
SpanBERT顺带着也对训练策略做了探索,和RoBERTa比较相似。主要是两点优化
- 一个长句比两个segment效果要好
- 不要NSP任务效果更好
这部分不算是SpanBERT的核心,这里就不做过多展开了~
Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT的更多相关文章
- Bert不完全手册6. Bert在中文领域的尝试 Bert-WWM & MacBert & ChineseBert
一章我们来聊聊在中文领域都有哪些预训练模型的改良方案.Bert-WWM,MacBert,ChineseBert主要从3个方向在预训练中补充中文文本的信息:词粒度信息,中文笔画信息,拼音信息.与其说是推 ...
- Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场 ...
- Bert不完全手册8. 预训练不要停!Continue Pretraining
paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks GitHub: https://github.com ...
- Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert
Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级.在我读Albert论文之前,因为Albe ...
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- Bert不完全手册9. 长文本建模 BigBird & Longformer & Reformer & Performer
这一章我们来唠唠如何优化BERT对文本长度的限制.BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力.不过Attention本身O(n^2)的计算和内存复杂度,也限制了Tr ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- 原来你是这样的BERT,i了i了! —— 超详细BERT介绍(一)BERT主模型的结构及其组件
原来你是这样的BERT,i了i了! -- 超详细BERT介绍(一)BERT主模型的结构及其组件 BERT(Bidirectional Encoder Representations from Tran ...
随机推荐
- iOS - TableViewCell分割线 --By吴帮雷
千万别小看UI中得线,否则你的设计师和测试组会无休止地来找你的!!(如果是美女还好,如果是恐龙....) 在开发中运用最多的是什么,对,表格--TableView,之所以称作表格,是因为他天生带有分割 ...
- MySQL5.7修改登录密码的几种方式
1.更新mysql.user表 use mysql UPDATE user SET authentication_string = password('新密码') where user = 'root ...
- 06.python语法入门--与用户交互、运算符
与用户交互 输入 input # python2与python3的区别 '''python3''' # 将获取到的用户输入赋值给变量名res res = input(' ...
- ThinkPHP5中使用第三方类库
在TP5中有两种方式使用第三方类库,如果类库支持composer方式安装那就很方便了,使用composer安装的类库存储在Vendor目录下,可以直接使用,以phpmailer为例,使用如下命令安装: ...
- 使用 WebView2 封装一个生成 PDF 的 WPF 控件
使用 WebView2 封装一个生成 PDF 的 WPF 控件 最近在迁移项目到 .net6,发现项目中用的 PDF 库不支持 .net6,于是想着换一个库.结果找了一大圈,发现不是版本不支持,就是收 ...
- 设计模式在实际业务应用中的介绍之3——外观或门面模式Facade对AOP装配业务工厂的应用
在C#中实现的基于外观或门面模式打造的业务应用案例 以前一直没有想过写一些东西来把项目中用到的知识点及技术实现做一个归纳整理并分享出来.现在打算逐渐的把项目中的一些东西整理并分享出来,与大家共勉! 外 ...
- NSSCTF-error
打开网页出现一个输入框,尝试使用127.0.0.1发现只是回显我们输入的内容 尝试进行注入,输入数字1会回显没有提示......,order by进行判断列数,得到有三列 接着就是正常注入的思路,使用 ...
- [GAMEDEV] 个人开发如何找到合适的图片素材?
1. 起因 起因是想找一些UI设计方面的素材(具体地说,类似于Web或者App上一些按钮/页签/进度条等元素),用到游戏GUI中来,毕竟扁平化的网页设计还是很清爽的. 本以为这方面的素材会比游戏中的图 ...
- vim编辑以及脚本编程练习
转至:http://www.178linux.com/88128 vim编辑器的使用总结: vim在工作过程当中有三种模式:编辑模式.输入模式.末行模式. 1.编辑模式:即命令模式,键盘操作常被理解为 ...
- 《Selenium+Pytest Web自动化实战》随到随学在线课程,零基础也能学!
课程介绍 课程主题:<Selenium+Pytest Web自动化实战> 适合人群: 1.功能测试转型自动化测试 2.web自动化零基础的小白 3.对python 和 selenium 有 ...