小样本利器5. 半监督集各家所长:MixMatch,MixText,UDA,FixMatch
在前面的几个章节中,我们介绍了几种基于不同半监督假设的模型优化方案,包括Mean Teacher等一致性正则约束,FGM等对抗训练,min Entropy等最小熵原则,以及Mixup等增强方案。虽然出发点不同但上述优化方案都从不同的方向服务于半监督的3个假设,让我们重新回顾下(哈哈自己抄袭自己):
- moothness平滑度假设:近朱者赤近墨者黑,两个样本在高密度空间特征相近,则label应该一致。优化方案如Mixup,一致性正则和对抗学习
- Cluster聚类假设:高维特征空间中,同一个簇的样本应该有相同的label,这个强假设其实是Smoothness的特例
- Low-density Separation低密度分离假设:分类边界应该处于样本空间的低密度区。这个假设更多是以上假设的必要条件,如果决策边界处于高密度区,则无法保证簇的完整和边缘平滑。优化方案入MinEntropy
MixMatch则是集各家所长,把上述方案中的SOTA都融合在一起实现了1+1+1>3的效果,主要包括一致性正则,最小熵,Mixup正则这三个方案。想要回顾下原始这三种方案的实现可以看这里
本章介绍几种半监督融合方案,包括MixMatch,和其他变种MixText,UDA,FixMatch
MixMatch
- Paper: MixMatch: A Holistic Approach to
Semi-Supervised Learning- Github: https://github.com/YU1ut/MixMatch-pytorch
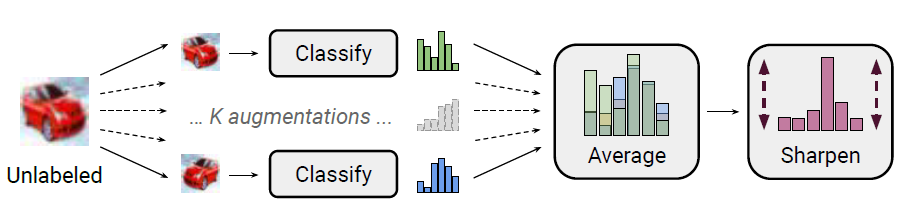
针对无标注样本,MixMatch融合了最小熵原则和一致性正则, 前者最小化模型预测在无标注样本上的熵值,使得分类边界远离样本高密度区,后者约束模型对微小的扰动给出一致的预测,约束分类边界平滑。实现如下
- Data Augmentation: 对batch中每个无标注样本做K轮增强\(\hat{u_{b,k}}=Augment(u_b)\),每轮增强得到一个模型预测\(P_{model}(y|u_{b,k};\theta)\)。针对图片作者使用了随机翻转和裁剪作为增强方案。
- Label Guessing: Ensemble以上k轮预测得到无标注样本的预估标签
\]
- Sharpening:感觉Sharpen是搭配Ensemble使用的,考虑K轮融合可能会得到置信度较低的标签,作者使用Temperature来降低以上融合标签的熵值,促使模型给出高置信的预测
\]
针对有标注样本,作者在原始Mixup的基础上加入对以上无标注样本的使用。
- 拼接:把增强后的标注样本\(\hat{X}\)和K轮增强后的无标注样本\(\hat{U}\)进行拼接得到\(W=Shuffle(Concat(\hat{X},\hat{U}))\)
- Mixup:两两样本对融合特征和标签得到新样本\(X^`,U^`\),这里在原始mixup的基础上额外约束mixup权重>0.5, 感觉这个约束主要针对引入的无标注样本,保证有标注样本的融合以原始标签为主,避免引入太多的噪声
\lambda &\sim Beta(\alpha, \alpha) \\
\lambda &= max(\lambda, 1-\lambda )\\
x^` &= \lambda x_1 + (1-\lambda)x_2 \\
p^` &= \lambda p_1 + (1-\lambda)p_2
\end{align}
\]
最终的损失函数由标注样本的交叉熵和无标注样本在预测标签上的L2正则项加权得到
L_x &= \frac{1}{X^`}\sum_{x \in X^`} CrossEntropy(p, P_{model}(y|x;\theta)) \\
L_x &= \frac{1}{k \cdot U^`}\sum_{u \in U^`}||q - P_{model}(y|u;\theta)||^2 \\
L & = L_x+ \lambda_u L_u
\end{align}
\]
Mixmath因为使用了多种方案融合因子引入了不少超参数,包括融合轮数K,温度参数T,Mixup融合参数\(\alpha\), 以及正则权重\(\lambda_u\)。不过作者指出,多数超惨不需要根据任务进行调优,可以直接固定,作者给的参数取值,T=0.5,K=2。\(\alpha=0.75,\lambda_u=100\)是推荐的尝试取值,其中正则权重作者做了线性warmup。
通过消融实验,作者证明了LabelGuessing,Sharpening,Mixup在当前的方案中缺一不可,且进一步使用Mean Teacher没有效果提升。
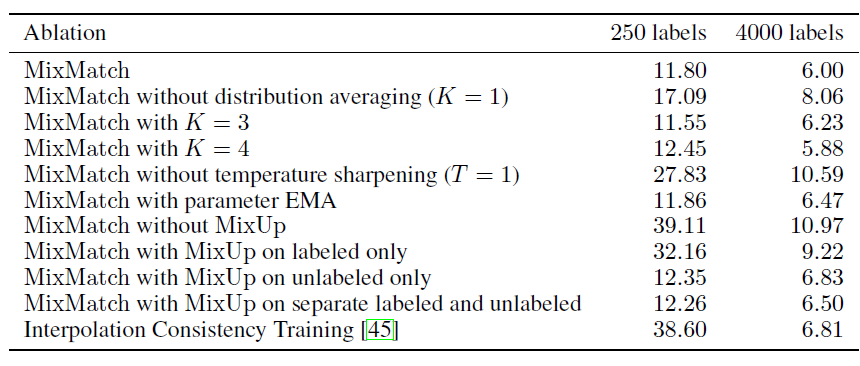
效果上对比单一的半监督方案,Mixmatch的效果提升十分显著

MixText
- Paper: MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
- Github:https://github.com/SALT-NLP/MixText
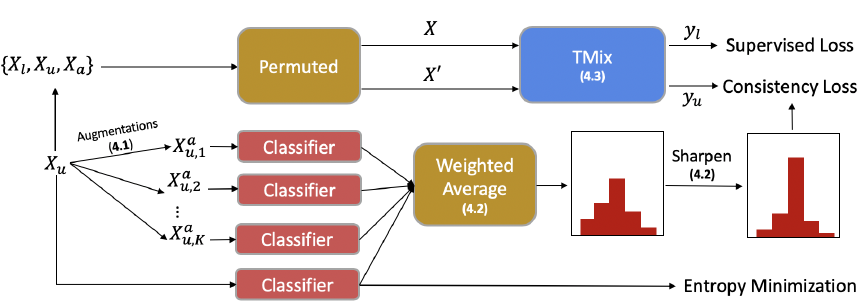
MixText是MixMatch在NLP领域的尝试,关注点在更适合NLP领域的Mixup使用方式,这里只关注和MixMatch的异同,未提到的部分基本上和MixMatch是一样的
- TMix:Mixup融合层
这一点我们在Mixup章节中讨论过,mixup究竟应该对哪一层隐藏层进行融合,能获得更好的效果。这里作者使用了和Manifold Mixup相同的方案,也就是每个Step都随机选择一层进行融合,只不过对选择那几层进行了调优(炼丹ing。。。), 在AG News数据集上选择更高层的效果更好,不过感觉这个参数应该是task specific的

- 最小熵正则
MixText进一步加入了最小熵原则,在无标注数据上,通过penalize大于\(\gamma\)的熵值(作者使用L2来计算),来进一步提高模型预测的置信度
L_{margin} &= E_{x \in U} max(0, \gamma - ||y^u||^2)\\
L_{MixText} &= L_{TMix} + \gamma_{m} L_{margin}
\end{align}
\]
- 无标注损失函数
MixMatch使用RMSE损失函数,来约束无标注数据的预测和Guess Label一致,而MixText使用KL-Divergance, 也就是和标注样本相同都是最小化交叉熵
UDA
- Paper:Unsupervised Data Augmentation for Consistency Training
- official Github: https://github.com/google-research/uda
- pytorch version: https://github.com/SanghunYun/UDA_pytorch
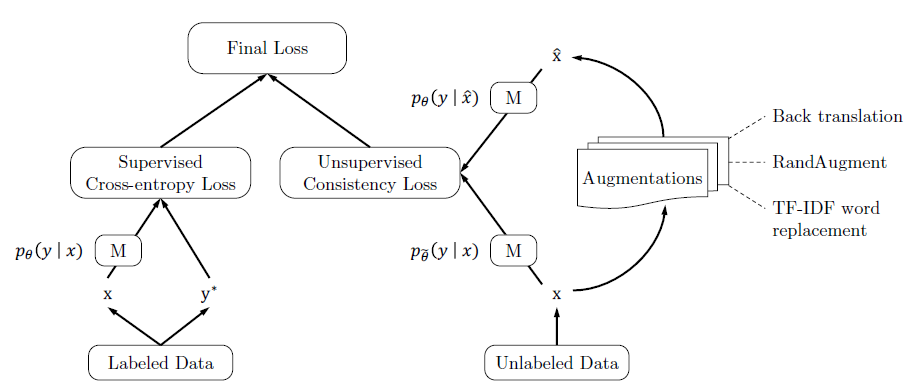
同样是MixMatch在NLP领域的尝试,不过UDA关注点在Data Augmentation的难易程度对半监督效果的影响,核心观点是难度高,多样性好,质量好的噪声注入,可以提升半监督的效果。以下只总结和MixMatch的异同点
Data Augmentation
MixMatch只针对CV任务,使用了随机水平翻转和裁剪进行增强。UDA在图片任务上使用了复杂度和多样性更高的RandAugment,在N个图片可用的变换中每次随机采样K个来对样本进行变换。原始的RandAugment是搜索得到最优的变换pipeline,这里作者把搜索改成了随机选择,可以进一步增强的多样性。
针对文本任务,UDA使用了Back-translation和基于TF-IDF的词替换作为增强方案。前者通过调整temperature可以生成多样性更好的增强样本,后者在分类问题中对核心关键词有更好的保护作用,生成的增强样本有效性更高。这也是UDA提出的一个核心观点就是数据增强其实是有效性和多样性之间的Trade-offPseudo Label
针对无标注样本,MixMatch是对K次弱增强样本的预测结果进行融合得到更准确的标签。UDA只对一次强增强的样本进行预测得到伪标签。Confidence-Based Maskin & Domain-relevance Data Filtering
UDA对无标注样本的一致性正则loss进行了约束,包括两个方面
- 置信度约束:在训练过程中,只对样本预测概率最大值>threshold的样本计算,如果样本预测置信度太低则不进行约束。这里的约束其实和MixMatch的多次预测Ensemble+Sharpen比较类似,都是提高样本的置信度,不过实现更简洁。
- 样本筛选:作者用原始模型在有标注上训练,在未标注样本上预测,过滤模型预测置信度太低的样本
核心是为了从大量的无标注样本中筛选和标注样本领域相似的样本,避免一致性正则部分引入太多的样本噪声。效果上UDA比MixMatch有进一步的提升,具体放在下面的FixMatch一起比较。
FixMatch
- Paper:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
- official Github: https://github.com/google-research/fixmatch
- pytorch version: https://github.com/kekmodel/FixMatch-pytorch
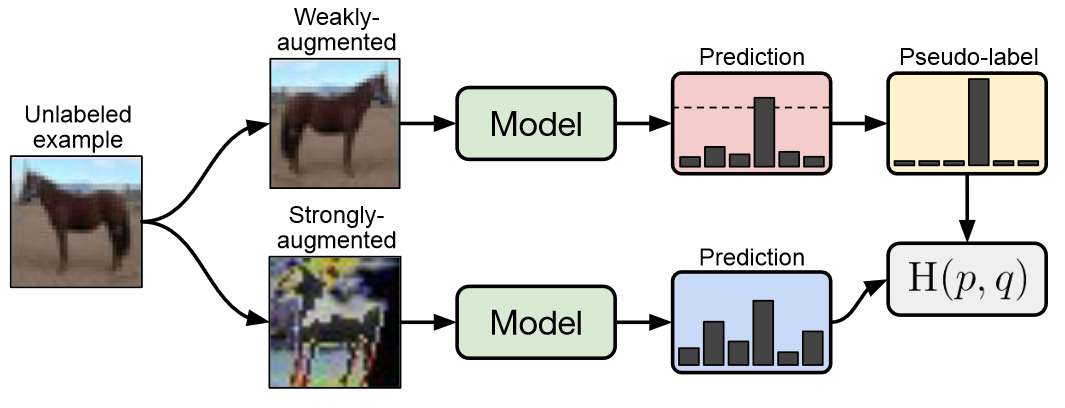
和MixMatch出自部分同一作者之手,融合了UDA的强增强和MixMatch的弱增强来优化一致性正则,效果也比MixMatch有进一步提升,果然大神都是自己卷自己~
- Pseudo Label
在生成无标注样本的伪标签时,FixMatch使用了UDA的一次预测,和MixMatch的弱增强Flip&Shift来生成伪标签,同时应用UDA的置信度掩码,预测置信度低的样本不参与loss计算。
- 一致性正则
一致性正则是FixMatch最大的亮点,它使用以上弱增强得到的伪标签,用强增强的样本去拟合,得到一致性正则部分的损失函数。优点是弱增强的标签准确度更高,而强增强为一致性正则提供更好的多样性,和更大的样本扰动覆盖区域,使用不同的增强方案提高了一致性正则的效果
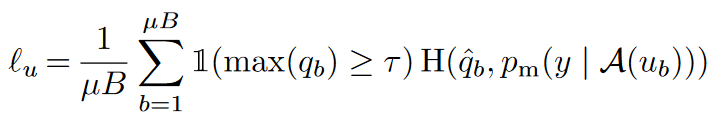
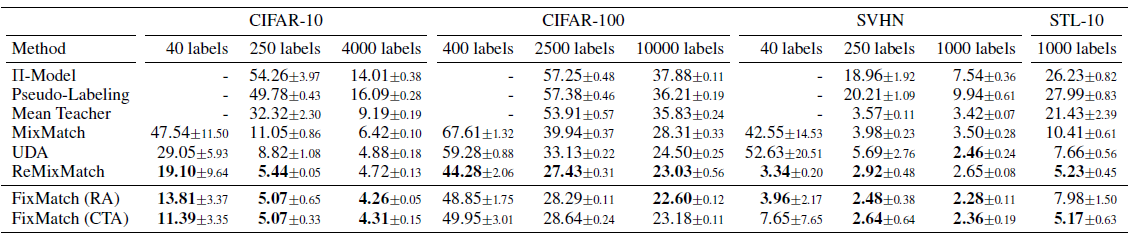
效果上FixMatch相比UDA,MixMatch和ReMixMatch均有进一步的提升
小样本利器5. 半监督集各家所长:MixMatch,MixText,UDA,FixMatch的更多相关文章
- 小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案.小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果.之前 ...
- 小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现
在前两章中我们已经聊过对抗学习FGM,一致性正则Temporal等方案,主要通过约束模型对细微的样本扰动给出一致性的预测,推动决策边界更加平滑.这一章我们主要针对低密度分离假设,聊聊如何使用未标注数据 ...
- 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现 上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力.这一章我们结合FG ...
- 小样本利器4. 正则化+数据增强 Mixup Family代码实现
前三章我们陆续介绍了半监督和对抗训练的方案来提高模型在样本外的泛化能力,这一章我们介绍一种嵌入模型的数据增强方案.之前没太重视这种方案,实在是方法过于朴实...不过在最近用的几个数据集上mixup的表 ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- 半监督学习方法(Semi-supervised Learning)的分类
根据模型的训练策略划分: 直推式学习(Transductive Semi-supervised Learning) 无标记数据就是最终要用来测试的数据,学习的目的就是在这些数据上取得最佳泛化能力. 归 ...
- GAN实战笔记——第七章半监督生成对抗网络(SGAN)
半监督生成对抗网络 一.SGAN简介 半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使 ...
- 常见半监督方法 (SSL) 代码总结
经典以及最新的半监督方法 (SSL) 代码总结 最近因为做实验需要,收集了一些半监督方法的代码,列出了一个清单: 1. NIPS 2015 Semi-Supervised Learning with ...
- cips2016+学习笔记︱NLP中的消岐方法总结(词典、有监督、半监督)
歧义问题方面,笔者一直比较关注利用词向量解决歧义问题: 也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显. 这篇论文有一些利用词向量的 ...
- 详解使用EM算法的半监督学习方法应用于朴素贝叶斯文本分类
1.前言 对大量需要分类的文本数据进行标记是一项繁琐.耗时的任务,而真实世界中,如互联网上存在大量的未标注的数据,获取这些是容易和廉价的.在下面的内容中,我们介绍使用半监督学习和EM算法,充分结合大量 ...
随机推荐
- ubuntu安装及使用
ubuntu教程 一. Ubuntu简介 Ubuntu(乌班图)是一个基于Debian的以桌面应用为主的Linux操作系统,据说其名称来自非洲南部祖鲁语或科萨语的"ubuntu"一 ...
- 学习ASP.NET Core Blazor编程系列六——新增图书(上)
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 学习ASP.NET Core Blazor编程系 ...
- logback.xml详解
介绍 之前博文有专门介绍过基于Log4j Appender 实现大数据平台组件日志的采集, 本篇主要对java项目中经常会接触到的logback.xml文件的配置做一个介绍和总结. logback.x ...
- 关于IOC容器
1.什么是 IOC (1)控制反转,把对象创建和对象之间的调用过程,交给 Spring 进行管理 (2)使用 IOC 目的:为了耦合度降低
- 小米MIUI禁止系统更新
删除downloaded_rom的文件夹,随便找一个文件(文件,不是文件夹),重名为downloaded_rom(是把一个文件重命名),这样系统后台偷偷下载时,就不知道该存放更新包的文件,就无法偷偷更 ...
- golang中的锁竞争问题
索引:https://www.waterflow.link/articles/1666884810643 当我们打印错误的时候使用锁可能会带来意想不到的结果. 我们看下面的例子: package ma ...
- 十八、Service的应用
Service 的应用 ClusterIP clusterIP 主要在每个 node 节点使用 ipvs,将发向 clusterIP 对应端口的数据,转发到 kube-proxy 中.然后 kube ...
- IDEA中Java项目创建lib目录并生成依赖
首先介绍说明一下idea在创建普通的Java项目,是没有lib文件夹的,下面我来带大家来创建一下1.右键点击项目,创建一个普通的文件夹 2.取名为lib 3.把项目所需的jar包复制到lib文件夹下 ...
- Flask(一)
pip install flask 依赖wsgi flask框架是基于werkzegu的wsgi实现,flask没有自己的wsgi 用户一旦请求,就会调用app.__call__方法 flask 路由 ...
- 6、将两个字符串连接起来,不使用strcat函数
/* 将两个字符串连接起来,不使用strcat函数 */ #include <stdio.h> #include <stdlib.h> void strCat(char *pS ...