小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案。小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果。之前在NER系列中我们已经介绍过Data Augmentation,不熟悉的童鞋看过来 中文NER的那些事儿4. 数据增强在NER的尝试。样本增强是通过提高标注样本的丰富度来提升模型泛化性,另一个方向半监督方案则是通过利用大量的相同领域未标注数据来提升模型的样本外预测能力。这一章我们来聊聊半监督方案中的一致性正则~
一致性正则~一个好的分类器应该对相似的样本点给出一致的预测,于是在训练中通过约束样本和注入噪声的样本要拥有相对一致的模型预测,来降低模型对局部扰动的敏感性,为模型参数拟合提供更多的约束。施工中的SimpleClassifcation提供了Temporal Ensemble的相关实现,可以支持多种预训练或者词袋模型作为backbone,欢迎来一起Debug >(*^3^)<

上图很形象的描述了一致性正则是如何利用标注和未标注数据来约束曲线拟合
a. 指用两个标注样本训练(大蓝点),因为样本少所以对模型拟合缺乏约束
b. 对标注样本注入噪音(小蓝点),并约束噪声样本和原始样本预测一致,通过拓展标注样本覆盖的空间,对模型拟合施加了更多的约束
c. 在对标注样本拟合之后,冻结模型,对未标注样本(空心点)进行一致性约束。因为一致性约束并不需要用到label因此可以充分利用未标注数据
d. 用未标注样本上一致性约束的loss来更新模型,使得模型对噪声更加鲁棒
以下三种方案采用了不同的噪声注入和Ensemble方式,前两个方案来自【REF1】Temporal Ensemble,第三个方案来自【REF2】Mean Teacher。因为合并了2篇paper,所以我们先整体过一下3种训练框架,再说训练技巧和一致性正则的一些insights。
Π-MODEL

如上图,针对每个样本,Π-MODEL会进行两次不同的增强,以及网络本身的随机drop out得到两个预测结果,一致性正则loss使用了MSE来计算两次预测结果的差异,既约束模型对输入样本的局部扰动要更加鲁棒。模型目标是有标注样本的cross- entropy,结合全样本的一致性正则loss
Π-MODEL的训练效率较低,因为每个样本都要计算两遍。
Temporal Ensemble
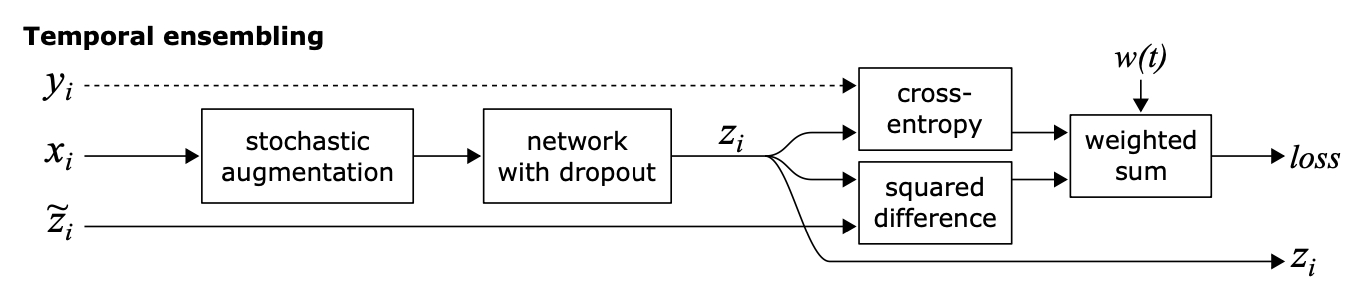
以上Π-MODEL在同一个epoch内对样本注入不同噪音的预测值进行约束,这部分约束会存在噪声较大,以及在epoch之间相对割裂的问题。因此作者引入Ensemble的思路在时间维度(epoch)做移动平均,来降低一致性loss的波动性。Temporal Ensemble通过约束各个epoch预测值的加权移动平均值\(Z\),和当前epoch预测值\(z\)的相对一致,来实现一致性正则,当\(\alpha=0\)的时候Temporal就退化成了Π-MODEL。
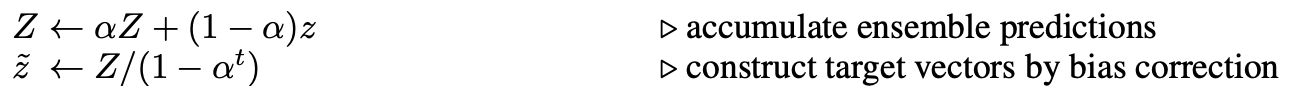
因此Temporal需要引入Sample_size * label_size的额外变量\(Z\),来存储每个样本在各个epoch上预测值的加权移动平均,如果你的样本非常大,则Temporal额外存储预测的变量会是很大的内存开销,以下为temporal部分的相关实现~
with tf.variable_scope('temporal_ensemble'):
temporal_ensemble = tf.get_variable(initializer=tf.zeros_initializer,
shape=(self.params['sample_size'], self.params['label_size']),
dtype=tf.float32, name='temporal_ensemble', trainable=False)
self.Z = tf.nn.embedding_lookup(temporal_ensemble, features['idx']) # batch_size * label_size
self.Z = self.alpha * self.Z + (1 - self.alpha) * preds
self.assign_op = tf.scatter_update(temporal_ensemble, features['idx'], self.Z)
add_layer_summary('ensemble', self.Z)
所以对比Π-MODEL,Temporal的一致性约束更加平滑,整体效果更好,以及计算效率更高因为每个样本只需要做一次预测,不过因为移动平均的引入会占用更多的内存~
Mean Teacher
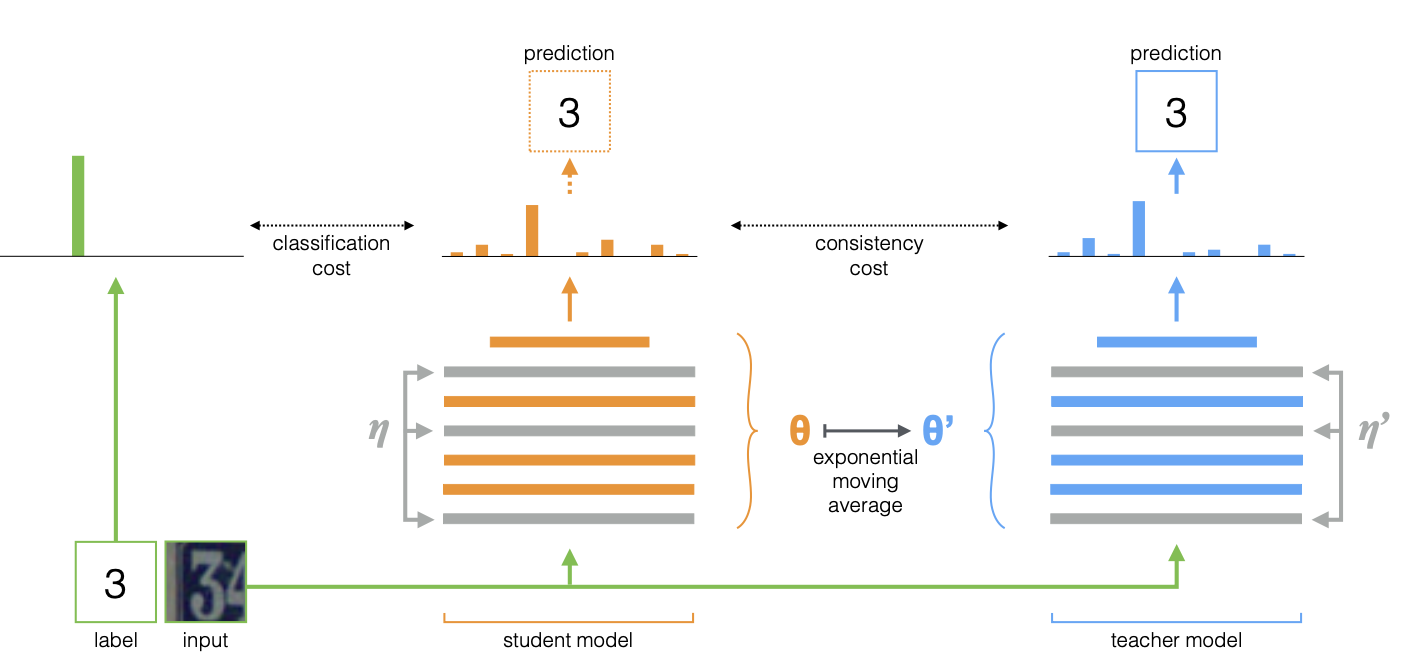
Mean Teacher是在Temporal的基础上调整了Ensemble实现的方案。Temporal是对每个样本的模型预测做Ensemble,所以每个epoch每个样本的移动平均才被更新一次,而Mean Teacher是对模型参数做Ensemble,这样每个step,student模型的更新都会反应在当前teacher模型上。
和Temporal无比相似的公式,差异只在于上面的Z是模型输出,下面的\(\theta\)是模型参数, 同样当\(\alpha=0\)的时候,Mean Teacher也退化成Π-MODEL。
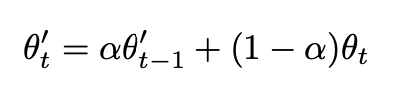
所以训练过程如下
- student模型对每个随机增强后的样本计算输出
- 每个step,student模型权重会移动更新teacher模型的权重
- 更新后的teacher模型对相同样本随机增强后计算输出
- 计算teacher和student模型预测结果的一致性loss,这里同样选用了MSE
- 监督loss + 一致性loss共同更新student模型参数
效果上Mean Teacher要优于Temporal,不过在计算效率上和Π-MODEL一样都需要预测两遍,所以要比Temporal慢不少,以及因为要存储模型参数的移动平均,所以内存占用也让人很头疼,所以Mean Teacher这块并没做相关的实现,对大模型并不太友好~
训练技巧
以上的噪声注入和Ensemble需要搭配一些特定的训练技巧。
- ramp up weight
在训练初期,模型应该以有监督目标为主,逐步增加一致性loss的权重,在temporal ensemble上更容易解释,因为当epoch=0时,\(\hat{z}\)是拿不到前一个epoch的预测结果的,因此一致性loss权重为0。代码中支持了线性,cosine,sigmoid等三种权重预热方案,原文中使用的是sigmoid
def ramp_up(cur_epoch, max_epoch, method):
"""
根据训练epoch来调整无标注loss部分的权重,初始epoch无标注loss权重为0
"""
def linear(cur_epoch, max_epoch):
return cur_epoch / max_epoch
def sigmoid(cur_epoch, max_epoch):
p = 1.0 - cur_epoch / max_epoch
return tf.exp(-5.0 * p ** 2)
def cosine(cur_epoch, max_epoch):
p = cur_epoch / max_epoch
return 0.5 * (tf.cos(np.pi * p) + 1)
if cur_epoch == 0:
weight = tf.constant(0.0)
else:
if method == 'linear':
weight = linear(cur_epoch, max_epoch)
elif method == 'sigmoid':
weight = sigmoid(cur_epoch, max_epoch)
elif method == 'cosine':
weight = cosine(cur_epoch, max_epoch)
else:
raise ValueError('Only linear, sigmoid, cosine method are supported')
return tf.cast(weight, tf.float32)
- 有标注样本权重
因为以上方案多用于半监督任务,因此需要根据无标注样本的占比来调整一致性正则部分的权重。最简单的就是直接用有标注样本占比来对以上的weight做rescale,有标注占比越高,一致性loss的权重约高,避免模型过度关注正则项。
- 损失函数选择
针对一致性正则的损失函数到底使用MSE还是KL,两篇paper都进行了对比,虽然从理论上KL更合逻辑,因为是对预测的概率分布进行一致性约束,但整体上MSE的效果更好。我猜测和NN倾向于给出over confident的预测相关,尤其是Bert一类的大模型会集中给出0.9999这种预测概率,在KL计算时容易出现极端值
Insights
以上两种ensemble的策略除了能提升半标注样本的效果之外,还有以下的额外效果加成
模糊标签:作者在全标注的样本上也尝试了self-ensemble的效果,对预测结果也有提升,猜测这源于一致性正则在一定程度上可能改进边缘/模糊label的样本效果
降噪:作者把x%的训练样本赋予随机label,然后对比常规训练和temporarl ensemble的效果。结果如下temporal对局部的标注噪音有很好的降噪效果。正确样本的监督loss帮助模型学习文本表征到label的mapping,而在正确样本附近的误标注样本会被一致性正则约束,从而降低错误标签对模型的影响。

分类效果
这里在头条15分类的数据集上进行了测试。分别在Fasttext和Bert上进行了测试,左是原始模型,右加入Temporal Ensemble。考虑NLP的样本层面的增强效果对比CV相对有限,这里的随机增强只用了Encoder层的Drop out,原论文是CV领域所以增强还包括crop/flip这类图像增强。
首先是Fasttext,受限于词袋模型本身的能力,即便是不加入未标注样本,只是加入Temporal一致性损失都带来了整体效果上的提升,具体参数设置详见checkpoint里面的train.log
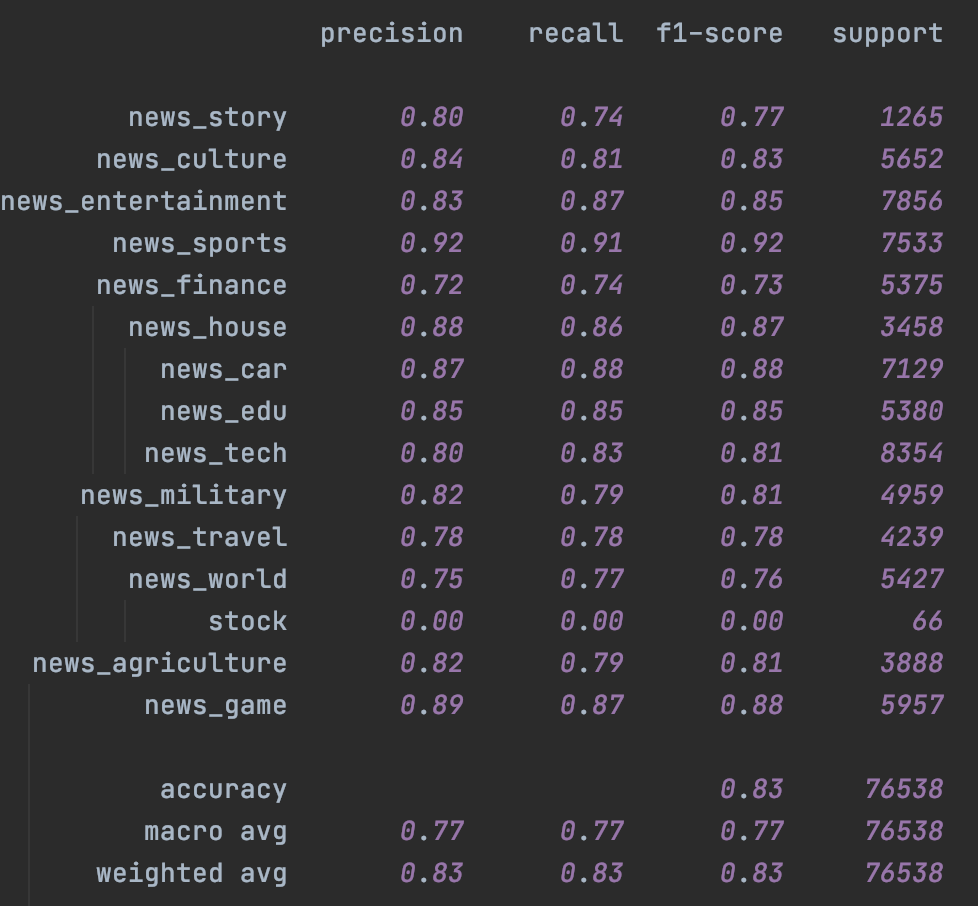 |
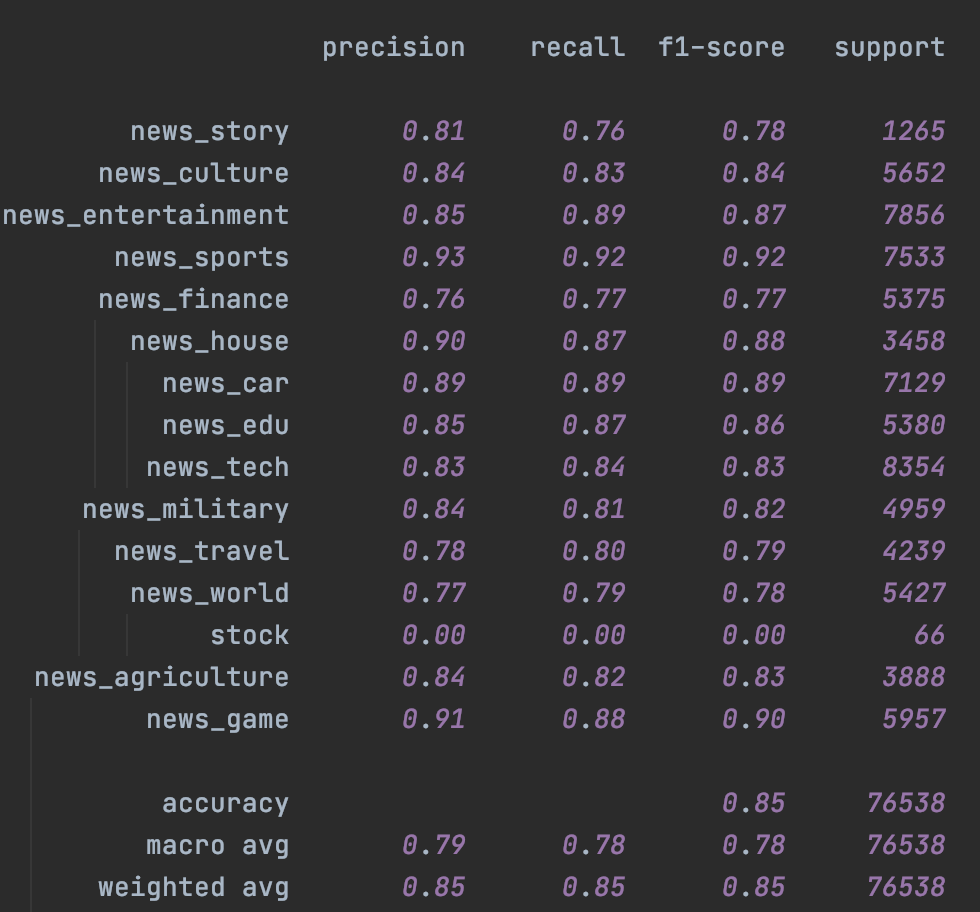 |
|---|
其次是Bert,这里加入了chinanews的无标注样本,不过效果比较有限,主要提升是在样本很少的stock分类上。这里一定程度和缺少有效的样本增强有关,后面结合隐藏层增强我们会再试下temporal~
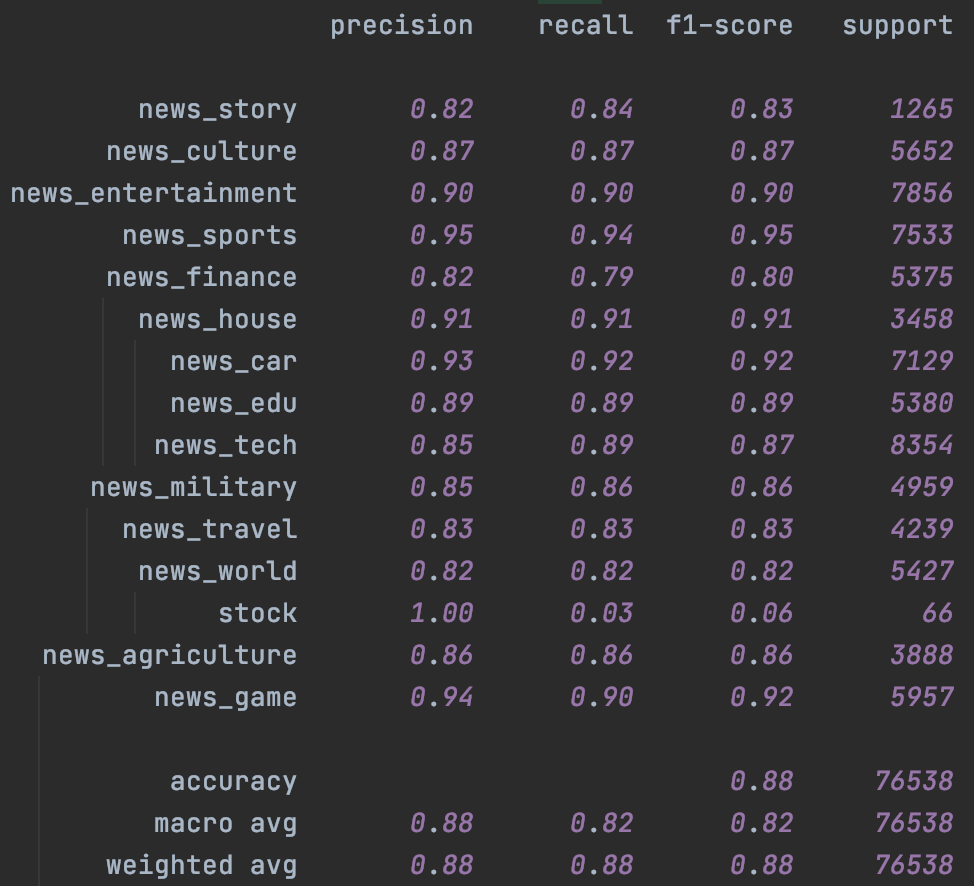 |
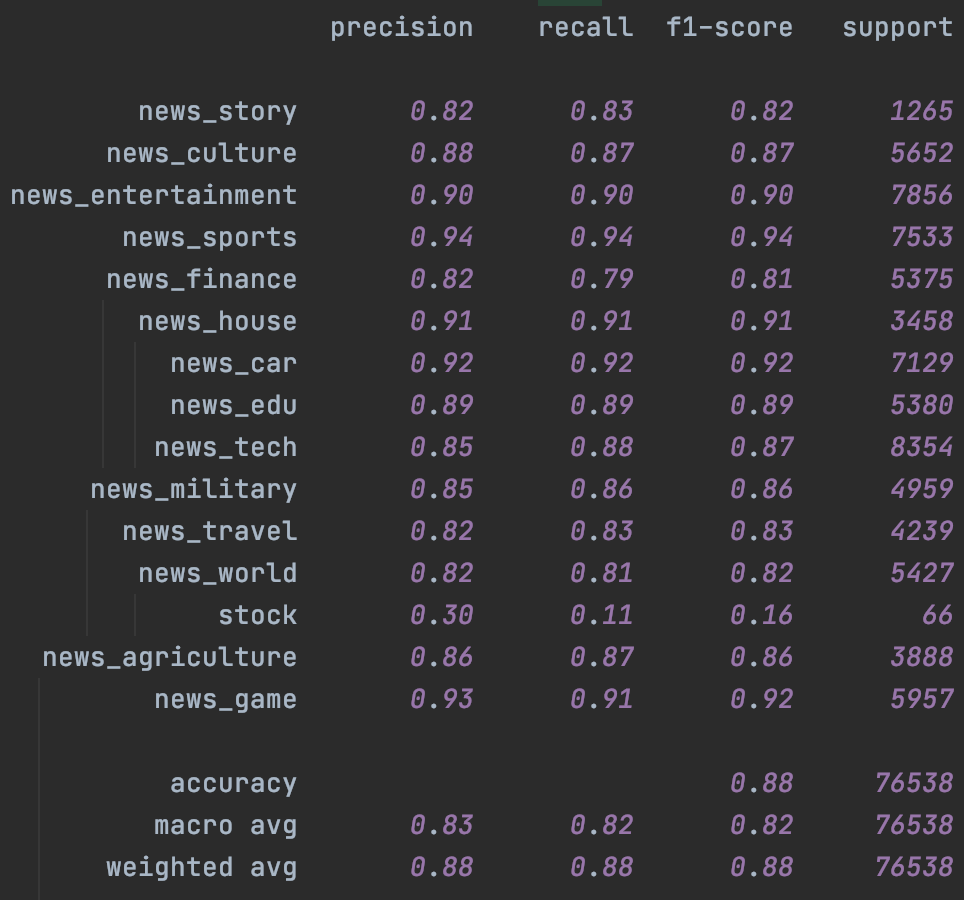 |
|---|
Reference
- Laine, S., Aila, T. (2016). Temporal Ensembling for Semi-Supervised Learning arXiv https://arxiv.org/abs/1610.02242
- Tarvainen, A., Valpola, H. (2017). Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results arXiv https://arxiv.org/abs/1703.01780
- https://tech.meituan.com/tags/半监督学习.html
- https://zhuanlan.zhihu.com/p/250278934
- https://zhuanlan.zhihu.com/p/128527256
- https://zhuanlan.zhihu.com/p/66389797
- https://github.com/diyiy/ACL2022_Limited_Data_Learning_Tutorial
小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现的更多相关文章
- 小样本利器3. 半监督最小熵正则 MinEnt & PseudoLabel代码实现
在前两章中我们已经聊过对抗学习FGM,一致性正则Temporal等方案,主要通过约束模型对细微的样本扰动给出一致性的预测,推动决策边界更加平滑.这一章我们主要针对低密度分离假设,聊聊如何使用未标注数据 ...
- 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现 上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力.这一章我们结合FG ...
- 小样本利器4. 正则化+数据增强 Mixup Family代码实现
前三章我们陆续介绍了半监督和对抗训练的方案来提高模型在样本外的泛化能力,这一章我们介绍一种嵌入模型的数据增强方案.之前没太重视这种方案,实在是方法过于朴实...不过在最近用的几个数据集上mixup的表 ...
- 常见半监督方法 (SSL) 代码总结
经典以及最新的半监督方法 (SSL) 代码总结 最近因为做实验需要,收集了一些半监督方法的代码,列出了一个清单: 1. NIPS 2015 Semi-Supervised Learning with ...
- cips2016+学习笔记︱NLP中的消岐方法总结(词典、有监督、半监督)
歧义问题方面,笔者一直比较关注利用词向量解决歧义问题: 也许你寄希望于一个词向量能捕获所有的语义信息(例如run即是动车也是名词),但是什么样的词向量都不能很好地进行凸显. 这篇论文有一些利用词向量的 ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- 详解使用EM算法的半监督学习方法应用于朴素贝叶斯文本分类
1.前言 对大量需要分类的文本数据进行标记是一项繁琐.耗时的任务,而真实世界中,如互联网上存在大量的未标注的数据,获取这些是容易和廉价的.在下面的内容中,我们介绍使用半监督学习和EM算法,充分结合大量 ...
- 数据量与半监督与监督学习 Data amount and semi-supervised and supervised learning
机器学习工程师最熟悉的设置之一是访问大量数据,但需要适度的资源来注释它.处于困境的每个人最终都会经历逻辑步骤,当他们拥有有限的监督数据时会问自己该做什么,但很多未标记的数据,以及文献似乎都有一个现成的 ...
- 半监督学习方法(Semi-supervised Learning)的分类
根据模型的训练策略划分: 直推式学习(Transductive Semi-supervised Learning) 无标记数据就是最终要用来测试的数据,学习的目的就是在这些数据上取得最佳泛化能力. 归 ...
随机推荐
- PAT1018 锤子剪刀布
大家应该都会玩"锤子剪刀布"的游戏:两人同时给出手势,胜负规则如图所示: 现给出两人的交锋记录,请统计双方的胜.平.负次数,并且给出双方分别出什么手势的胜算最大. 输入格式: 输入 ...
- Blazor组件自做八 : 使用JS隔离封装屏幕键盘kioskboard.js组件
1. 运行截图 演示地址 2. 在文件夹wwwroot/lib,添加kioskboard子文件夹,添加kioskboards.js文件 2.1 常规操作,懒加载js库, export function ...
- SpringBoot注解自动扫描-底层实现
分析上文Spring Boot快速入门 @SpringBootApplication public class HelloWorldApplication { public static void m ...
- Js中的三个错误语句:try、catch、throw
Js中的三个错误语句:try.catch.throw
- 《码处高效:Java开发手册》之代码风格
流水淡,碧天长,鸿雁成行.编码风格,简捷清爽,反引无限风光. 在美剧<硅谷>中有这样一个经典镜头,主人公 Richard 与同为开发工程师的女友闹分手,理由是两人对缩进方式有着截然不同的编 ...
- partOne测试收获总结
测试收获总结 执行类中构造多个方法,将各个功能分解出来,将大的,复杂的问题转化成小的,简单的问题,来进行处理,正所谓复杂问题简单化,简单问题流程化.大道至简编程精益.现总结编程中的一些问题,①在J ...
- thinkphp6事件监听event-listene
事件系统可以看成是行为系统的升级版,相比行为系统强大的地方在于事件本身可以是一个类,并且可以更好的支持事件订阅者. 事件相比较中间件的优势是事件比中间件更加精准定位(或者说粒度更细),并且更适合一些业 ...
- Java第十五周作业
Cola公司的雇员分为以下若干类:(知识点:多态) [必做题]• 4.1 ColaEmployee :这是所有员工总的父类,属性:员工的姓名,员工的生日月份.方法:getSalary(int mont ...
- JavaWeb和WebGIS学习笔记(三)——GeoServer 发布shp数据地图
系列链接: Java web与web gis学习笔记(一)--Tomcat环境搭建 Java web与web gis学习笔记(二)--百度地图API调用 JavaWeb和WebGIS学习笔记(三)-- ...
- 基本命令学习 -(3)Linux压缩和解压缩命令汇总
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 前言 Linux下的压缩和解压缩工具比较多,有时经常记不住,这里给大家汇总一下,方便大家查阅. ...