Trino Master OOM 排查记录
背景
最近线上的 trino 集群 master 节点老是因为 OOM crash,我们注意到 trino crash 前集群正在运行的查询数量正常,不太像是因为并发查询数据太多导致的 OOM。遂配置 trino master 的 jvm,使其在崩溃后生成一份 dump 文件,方便我们进行问题排查。
排查问题过程
收集到了 Trino master oom dump 文件,用 mat 工具对其分析得出报告。
从报告得知,trino master crash 前有一条查询消耗掉了大量资源,还有一大堆的 DeleteFileIndex 实例也消耗掉很多资源。

我们有收集 trino 上所有的查询语句,通过 query_id 定位到那条异常 SQL。初看 SQL 逻辑,没太大问题,应该不会导致 trino master oom。
于是找一个 trino 集群做故障还原,发现并发执行 异常SQL 4条,master 就会 crash。
于是进 trino-master 容器内,用 arthas 实时观察 jvm 状况。
发现当 异常SQL 发起查询时,jvm 内 iceberg-work-pool 线程的 cpu 暂用率会飙升到 100%,且此时 jvm 内存也在飙升,过程持续 20s,刚好是异常SQL 生成执行计划所花费的时间。
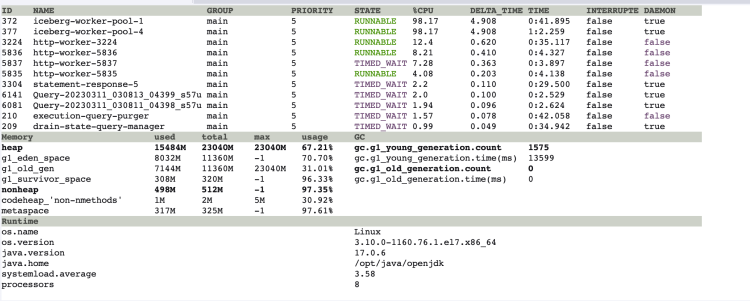
然后使用 arthas 查看 iceberg-work-pool 线程在干嘛?发现其在调用 DeleteFileIndex 这个类,在报告里面也是属于 top 10 comsumer 。

看栈信息,得到信息在扫描 iceberg 的 manifestlist 时,会去扫描已删除的文件。猜测大概率是需要找到已删除的数据 和 现在存在的数据 做一个 merge,才是当前快照的真实数据。
于是分析 怀疑表 nft_orders_v2 的元数据信息,发现 snapshow 里需要读取大量的删除文件。
snapshots
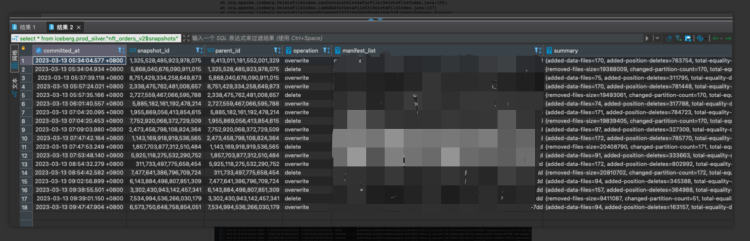
而 Trino 是使用 merge on read 模式进行 merge/update/delete 操作的,这样的话每次查询时,得扫描 "delete file" 来和 "data file" 进行合并,得出真实数据。

所以问题就出现在这,由于该表每半小时生产一次,底层存在大量的 'delete file' ,每次查询时都要扫描这些 'delete file' 然后做 merge 操作生成执行计划。这步操作消耗掉很多 cpu资源和内存资源,导致 trino master 节点崩溃。
解决方案
使用 trino 的小文件合并功能,重写底层数据文件即可修复。
ALTER TABLE nft_orders_v2 EXECUTE optimize (file_size_threshold => '100MB')
为了规避此类问题再次分析,还需要找出哪些查询的查询计划时间大于 10s,找出这些查询并分析用到的表的元数据是否合理,不合理要及时修正。
Trino Master OOM 排查记录的更多相关文章
- Linux 遭入侵,挖矿进程被隐藏排查记录
今天来给大家分享下这两天遇到的一个问题,服务器被挖矿了,把我的排查记录分享下,希望能帮到有需要的同学. 问题原因 多台服务器持续告警CPU过高,服务器为K8s的应用节点,正常情况下CPU使用率都挺低的 ...
- 【转】又一次线上 OOM 排查经过
又一次线上OOM排查经过 最近线上一个服务又出现了频繁Full GC的情况,导致提供的业务经常超时.问题出现非常不稳定,经过两周的时候,终于又捕捉到了一次Full GC,于是联系运维做Heap Dum ...
- FastDFS----recovery状态问题排查记录
FastDFS问题排查记录现象今天有人反馈,客户端部分图标时而不能显示问题定位用jemter将图片地址进行简单测试后,发现偶尔有404 NOT FOUND的情况在服务器上对八台nginx分别进行测试 ...
- Shiro权限管理框架(五):自定义Filter实现及其问题排查记录
明确需求 在使用Shiro的时候,鉴权失败一般都是返回一个错误页或者登录页给前端,特别是后台系统,这种模式用的特别多.但是现在的项目越来越多的趋向于使用前后端分离的方式开发,这时候就需要响应Json数 ...
- 一次内核 crash 的排查记录
一次内核 crash 的排查记录 使用的发行版本是 CentOS,内核版本是 3.10.0,在正常运行的情况下内核发生了崩溃,还好有 vmcore 生成. 准备排查环境 crash 内核调试信息rpm ...
- 记录一次OOM排查经历
我是用了netty搭建了一个UDP接收日志,堆启动配置 Xmx256 Xms256 ,项目刚启动的时候,系统进程占用内存很正常,在250M左右. 长时间运行之后发现,进程占用内存不断增长,远远超过了 ...
- 记录一次OOM排查经历(一)
一.经历概要 程序里有个跑数据的job,这个job的主要功能是往数据库写假数据. 既需要跑历史数据(传给job的日期是过去的时间),也需要能够上线后,实时跑(十秒钟触发一次,传入触发时的当前时间). ...
- Kubernetes Pod OOM 排查日记
一.发现问题 在一次系统上线后,我们发现某几个节点在长时间运行后会出现内存持续飙升的问题,导致的结果就是Kubernetes集群的这个节点会把所在的Pod进行驱逐OOM:如果调度到同样问题的节点上,也 ...
- 一次完整的JVM堆外内存泄漏故障排查记录
前言 记录一次线上JVM堆外内存泄漏问题的排查过程与思路,其中夹带一些JVM内存分配机制以及常用的JVM问题排查指令和工具分享,希望对大家有所帮助. 在整个排查过程中,我也走了不少弯路,但是在文章中我 ...
- 一次MySQL死锁的排查记录
前几天线上收到一条告警邮件,生产环境MySQL操作发生了死锁,邮件告警的提炼出来的SQL大致如下. update pe_order_product_info_test set end_time = ' ...
随机推荐
- react module.scss文件中弹窗中 keyframes动画不生效,
以下修改,亲测有效非弹窗内动画写法 .submit_btn{ animation: submit_btn 1.5s infinite; -webkit-animation: submit_ ...
- 在Windows系统上安装和配置Jenkins自动发布
一.安装jenkins的流程转载于: https://www.jianshu.com/p/de9c4f5ae7fa 二.在window中执行批处理文件bat或者powershell可以成功,但是Jen ...
- c# HttpServer 的使用
在很多的时候,我们写的应用程序需要提供一个信息说明或者告示功能,希望借助于HttpServer来发布一个简单的网站功能,但是又不想架一个臃肿的Http服务器功能, 这时候,标准框架提供的HttpSer ...
- docker部署服务器
Docker部署PostGres docker run -d --name postgres --restart always -e POSTGRES_USER='postgres' -e POSTG ...
- idea中怎么安装使用翻译插件?
1.打开File->Setting 2.plugins->Browse repositories 3.输入"translate",选择排序"Downloads ...
- 训练题——ADC读取温度
Author:XuanYu 利用ADC测量单片机内部温度 废话不多说,直接开搞. 科普 先科普一下ADC(不是 AD carry!),ADC是模数转化器,就是模拟信号转换成数字信号的东西,通常的模数转 ...
- 入库大文件csv文件
LOAD DATA LOCAL INFILE 'D:\\ss\\chongzhi\\T_RORD.csv' INTO TABLE cz_T_RECHARGE_SET_RECORDFIELDS TERM ...
- 插件和依赖的区别以及Java web开发层次结构
一:插件和依赖的区别 依赖:运行时和开发时都需要用到的包,比如项目中需要一个包,就要添加一个依赖(数据库驱动,连接池,mybatis...),这个依赖在项目运行时也需要,因此在项目打包时需要把这些依赖 ...
- Pytest+allure+requests接口自动化
实现功能 测试数据隔离: 测试前后进行数据库备份/还原 接口直接的数据依赖: 需要B接口使用A接口响应中的某个字段作为参数 对接数据库: 讲数据库的查询结果可直接用于断言操作 动态多断言: 可(多个) ...
- 20220720 第七组 陈美娜 Java String用法
关于String引用数据类型 1.字符串中,两个变量的==指的是虚地址 2.String一旦声明不可改变:赋值进去,原值不会被替代.原值也可能指向其他地址: 3.s.length():字符的个数 4. ...