Pytorch实战学习(五):多分类问题
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Softmax Classifer
1、二分类问题:糖尿病预测
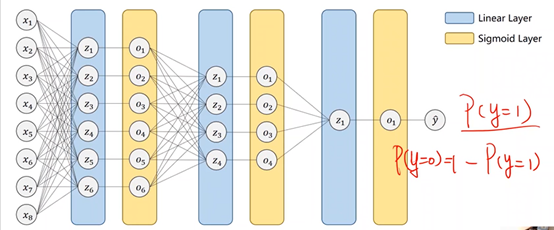
2、多分类问题
MNIST Dataset:10个标签,图像数字(0-9)识别
①用sigmoid:输出每个类别的概率
但这种情况下,类别之间所存在的互相抑制的关系没有办法体现,当一个类别出现的概率较高时,其他类别出现的概率仍然有可能很高。
换言之,当计算输出为1的概率之后,再计算输出为2的概率时,并不是在输出为非1的条件下进行的,也就是说,所有输出的概率之和实际上是大于1的。
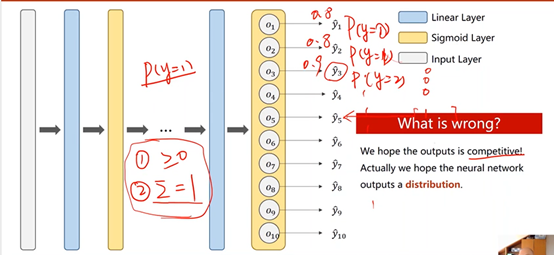
②用softmax:输出每个类别的概率的分布
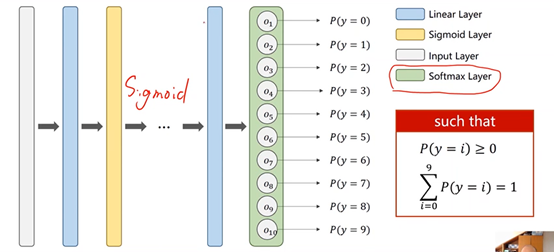
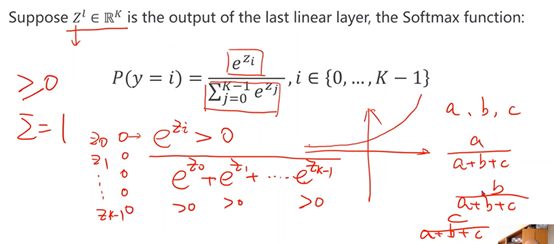
3、softmax原理
保证两点:
※每个类别概率都>0------指数函数
※所有类别概率相加为1------求和,占比
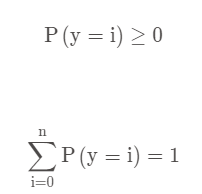
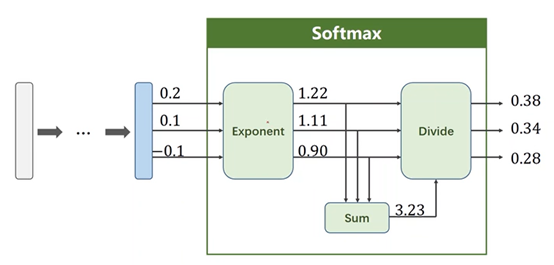
4、Softmax Loss Function
①NLLLoss
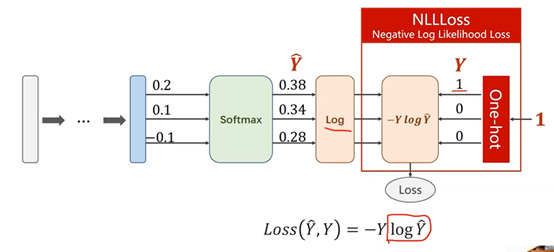
②Torch.nn.CrossEntropyLoss()中包含了最后一层的softmax激活
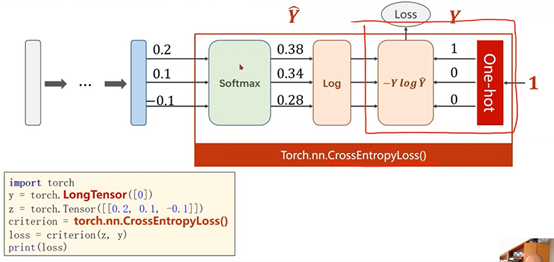
③交叉熵损失(CrossEntropyLoss)和NLL损失之间的差别
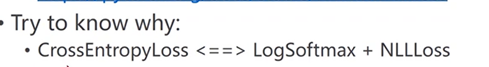
5、实例:MNIST Dataset
①数据准备
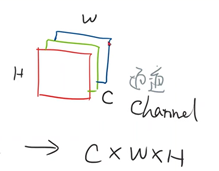
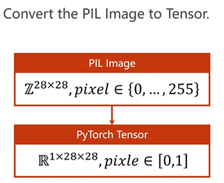
transform将图像转换成图像张量(CxWxH)(通道x宽x高),取值在[0,1]
再进行标准化
## 将图像数据转换成图像张量
transform = transforms.Compose([
transforms.ToTensor(),
# 标准化,均值和标准差
transforms.Normalize((0.1307,), (0.3081,))
])
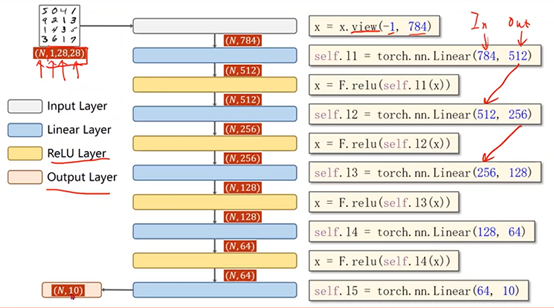
②模型构建
完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 4 09:08:32 2021 @author: motoh
""" import torch
## 对图像数据进行处理的包
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
## 将图像数据转换成图像张量
# 标准化,均值和标准差
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10) def forward(self, x):
#变成矩阵 -1其实就是自动获取mini_batch,784是1*28*28,图片的像素数量
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 最后一层不做激活,不进行非线性变换
return self.l5(x) model = Net() # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
## 不计算梯度
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# dim = 1 列是第0个维度,行是第1个维度,## 每一行最大值的下标
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果

Pytorch实战学习(五):多分类问题的更多相关文章
- PyTorch深度学习实践——多分类问题
多分类问题 目录 多分类问题 Softmax 在Minist数据集上实现多分类问题 作业 课程来源:PyTorch深度学习实践--河北工业大学 <PyTorch深度学习实践>完结合集_哔哩 ...
- Pytorch实战(3)----分类
一.分类任务: 将以下两类分开. 创建数据代码: # make fake data n_data = torch.ones(100, 2) x0 = torch.normal(2*n_data, 1) ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- Spring实战第五章学习笔记————构建Spring Web应用程序
Spring实战第五章学习笔记----构建Spring Web应用程序 Spring MVC基于模型-视图-控制器(Model-View-Controller)模式实现,它能够构建像Spring框架那 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- Pytorch迁移学习实现驾驶场景分类
Pytorch迁移学习实现驾驶场景分类 源代码:https://github.com/Dalaska/scene_clf 1.安装 pytorch 直接用官网上的方法能装上但下载很慢.通过换源安装发现 ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
随机推荐
- springboot输出json日志
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-lo ...
- TCP与UDP、socket模块
1.传输层之TCP与UDP协议 1.TCP协议 1.传输控制协议(也称为TCP协议或可靠协议)是为了在不可靠的互联网络上提供可靠的端到端字节流而专门设计的一个传输协议,(数据不容易丢失);造成数据不容 ...
- Dijkstra求最短路 I(朴素算法)
这道题目又是一个新算法,名叫Dijkstra 主要思路是:输入+dist和vis初始化(都初始化为0x3f)+输入g(邻接矩阵)+Dijkstra函数 Dijkstra函数:先将dist[ ...
- Vue12 监视属性
1 简介 所谓监听就是对内置对象的状态或者属性变化进行监听并且做出反应的响应,监听属性,意思就是可以监视其他数据的变化 2 使用 使用watch配置项,在配置项里面写上要监视的属性,每次属性值的变化都 ...
- mysql19-锁
1.什么是锁 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源(如CPU.RAM.I/O等)的争用以外,数据也是一种供许多用户共享的资源.如何保证数据并发访问的一致性. ...
- JZOJ 2020.01.11【NOIP提高组】模拟B组
2020.01.11[NOIP提高组]模拟B组 今天的题是不是和 \(C\) 组放错了? 呵呵 然,却只有 \(300\) 分 首先,\(T4\) 看错题了 后,一时想不到正解 讨论区,一看,三个字- ...
- AcWing 141 周期
题目:https://www.acwing.com/problem/content/143/ 一个字符串的前缀是从第一个字符开始的连续若干个字符,例如"abaab"共有5个前缀,分 ...
- 3D模型在线查看工具
3D场景工具推荐:NSDT场景编辑器. glTF Viewer 2.0是一个可以在线查看GLTF格式3D模型的,可以对模型进行显示设置.灯光设置来查看模型效果,除此之外还可以对模型进行性能分析和模型验 ...
- 慧销平台ThreadPoolExecutor内存泄漏分析
作者:京东零售 冯晓涛 问题背景 京东生旅平台慧销系统,作为平台系统对接了多条业务线,主要进行各个业务线广告,召回等活动相关内容与能力管理. 最近根据告警发现内存持续升高,每隔2-3天会收到内存超过阈 ...
- fabric学习笔记9
fabric学习笔记9 20201303张奕博 2023.1.20 Python Web3 与智能合约的交互 开发合约,或者开源合约,都会有一份该合约的ABI JSON文件 ABI文件包括了智能合约的 ...