Pytorch实战学习(五):多分类问题
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Softmax Classifer
1、二分类问题:糖尿病预测
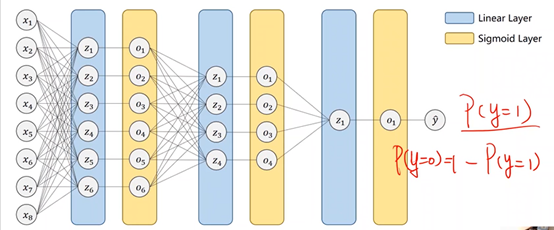
2、多分类问题
MNIST Dataset:10个标签,图像数字(0-9)识别
①用sigmoid:输出每个类别的概率
但这种情况下,类别之间所存在的互相抑制的关系没有办法体现,当一个类别出现的概率较高时,其他类别出现的概率仍然有可能很高。
换言之,当计算输出为1的概率之后,再计算输出为2的概率时,并不是在输出为非1的条件下进行的,也就是说,所有输出的概率之和实际上是大于1的。
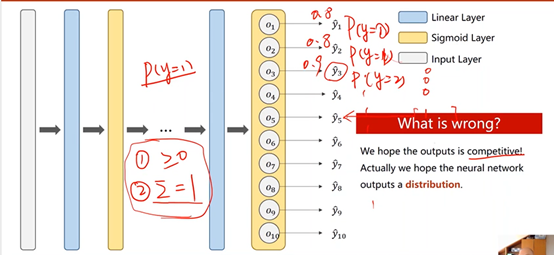
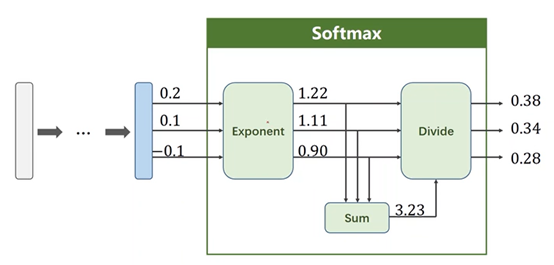
②用softmax:输出每个类别的概率的分布
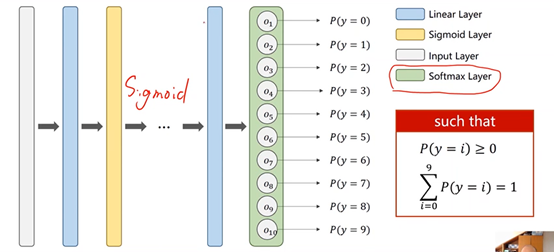
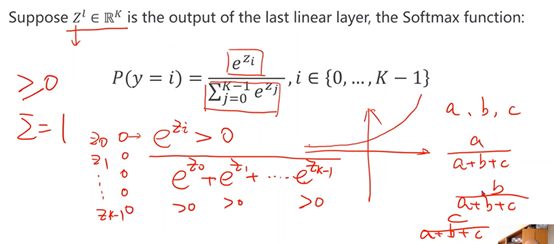
3、softmax原理
保证两点:
※每个类别概率都>0------指数函数
※所有类别概率相加为1------求和,占比
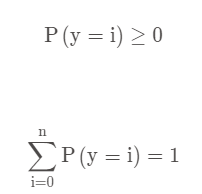
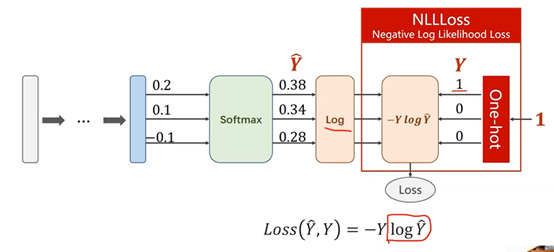
4、Softmax Loss Function
①NLLLoss
②Torch.nn.CrossEntropyLoss()中包含了最后一层的softmax激活
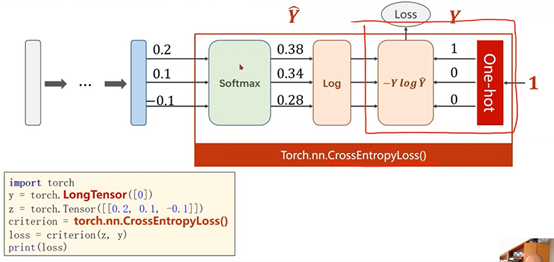
③交叉熵损失(CrossEntropyLoss)和NLL损失之间的差别
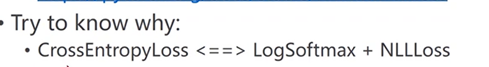
5、实例:MNIST Dataset
①数据准备
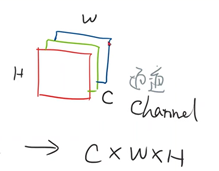
transform将图像转换成图像张量(CxWxH)(通道x宽x高),取值在[0,1]
再进行标准化
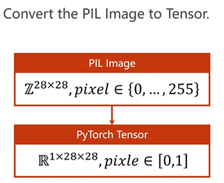
## 将图像数据转换成图像张量
transform = transforms.Compose([
transforms.ToTensor(),
# 标准化,均值和标准差
transforms.Normalize((0.1307,), (0.3081,))
])
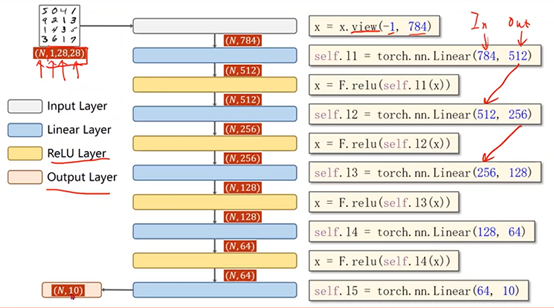
②模型构建
完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Aug 4 09:08:32 2021 @author: motoh
""" import torch
## 对图像数据进行处理的包
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
## 将图像数据转换成图像张量
# 标准化,均值和标准差
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10) def forward(self, x):
#变成矩阵 -1其实就是自动获取mini_batch,784是1*28*28,图片的像素数量
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
# 最后一层不做激活,不进行非线性变换
return self.l5(x) model = Net() # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
# 获得一个批次的数据和标签
inputs, target = data
optimizer.zero_grad()
# 获得模型预测结果(64, 10)
outputs = model(inputs)
# 交叉熵代价函数outputs(64,10),target(64)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
## 不计算梯度
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# dim = 1 列是第0个维度,行是第1个维度,## 每一行最大值的下标
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果

Pytorch实战学习(五):多分类问题的更多相关文章
- PyTorch深度学习实践——多分类问题
多分类问题 目录 多分类问题 Softmax 在Minist数据集上实现多分类问题 作业 课程来源:PyTorch深度学习实践--河北工业大学 <PyTorch深度学习实践>完结合集_哔哩 ...
- Pytorch实战(3)----分类
一.分类任务: 将以下两类分开. 创建数据代码: # make fake data n_data = torch.ones(100, 2) x0 = torch.normal(2*n_data, 1) ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- Spring实战第五章学习笔记————构建Spring Web应用程序
Spring实战第五章学习笔记----构建Spring Web应用程序 Spring MVC基于模型-视图-控制器(Model-View-Controller)模式实现,它能够构建像Spring框架那 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- Pytorch迁移学习实现驾驶场景分类
Pytorch迁移学习实现驾驶场景分类 源代码:https://github.com/Dalaska/scene_clf 1.安装 pytorch 直接用官网上的方法能装上但下载很慢.通过换源安装发现 ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
随机推荐
- mvn引用本地包
<dependency> <groupId>jna</groupId> <artifactId>jna</artifactId> <s ...
- drf-api接口、测试工具postman
1.web应用模式 """ django是一个web框架,专门用来写web项目,之前学的bbs项目,图书管理系统,用的是前后端混合开发. ""&quo ...
- vue + video.js/videojs-contrib-hls 实现hls拉流播放
当时接手拉流播放时使用的是西瓜播放器插件,神奇的是 安卓手机显示正常,但是苹果一直显示加载,pc端使用https格式不能播放,但是去掉s改为http即可进行播放 后面查看大佬文章后总算解决了这一需求 ...
- 从 PyTorch DDP 到 Accelerate 到 Trainer,轻松掌握分布式训练
概述 本教程假定你已经对于 PyToch 训练一个简单模型有一定的基础理解.本教程将展示使用 3 种封装层级不同的方法调用 DDP (DistributedDataParallel) 进程,在多个 G ...
- Spring Cloud Openfeign Get请求发生405错误
kust-retrieve服务 @Resource private AuthFeignService authFeignService; @ApiOperation("获取用户信息" ...
- 2021级《JAVA语言程序设计》上机考试试题8
专业教师功能页: <%@ page language="java" contentType="text/html; charset=UTF-8" page ...
- GitHub 入门 与 2023年2月18日10:29:02
用 GitHub 有一段时间了,之前一直用来做 Hexo 的服务器,直到前阵子搞 GitHub Action 因为命令不熟,把 GitHub 上的源码强制拉到本地把本地的 Hexo 搞崩了,博客源码都 ...
- 吐血整理!2万字Java基础面试题(带答案)请收好!
熬夜整理了这么多年来的Java基础面试题,欢迎学习收藏,手机上可以点击这里,效果更佳https://mp.weixin.qq.com/s/ncbEQqQdJo0UaogQSgA0bQ 1.1 Hash ...
- ABP微服务学习系列-修复System.Text.Json不支持序列化Exception
前面我们已经把服务都启动了,然后我们试试请求API.发现请求出现500 返回错误 System.NotSupportedException: Serialization and deserializa ...
- Mysql习题系列(一):基本select语句与运算符
Mysql8.0习题系列 软件下载地址 提取码:7v7u 数据下载地址 提取码:e6p9 文章目录 Mysql8.0习题系列 1. 基本select语句 1.1 题目 1.2答案 1.查询员工12个月 ...