Bert不完全手册7. 为Bert注入知识的力量 Baidu-ERNIE & THU-ERNIE & KBert
借着ACL2022一篇知识增强Tutorial的东风,我们来聊聊如何在预训练模型中融入知识。Tutorial分别针对NLU和NLG方向对一些经典方案进行了分类汇总,感兴趣的可以去细看下。这一章我们只针对NLU领域3个基于实体链接的知识增强方案Baidu-ERNIE,THU-ERNIE和K-Bert来聊下具体实现~
知识增强
Knowledge is any external information absent from the input but helpful for generating the output
Tutorial里一句话点题,知识就是不直接包含在当前文本表达中的,但是对文本理解起到帮助作用的补充信息,大体可以分成
- 通用领域:例如中国的首都是北京
- 特殊领域:例如医疗,金融,工业等场景中的领域知识,
- 常识:例如狗有4条腿,鸡不会飞,猪不能上树
常规预训练预语料也是包含部分知识的,不过受限于知识出现的频率,以及非结构化的知识表征,预训练任务的设计等等因素,知识信息往往等不到充分的训练,因此BERT不可避免会给出一些不符合知识但是符合语言表达的预测结果,于是有了尝试在预训练阶段融入结构化知识信息的各种尝试
LM中融入知识的一般分成3个步骤:定位知识(knowledge grounding),知识表征(knowledge representation),融入知识(knowledge fusion),这么说就像把大象放进冰箱一样easy,不过实现起来细节问题颇多,例如定位知识时的消歧问题,知识表征和文本表征的不一致问题,知识融入时如何不干扰原始的上下文语义等等,下面我们来看下3种不同的增强方案
Baidu-ERNIE
- paper: ERNIE: Enhanced Representation through Knowledge Integratiion
- Github: https://github.com/PaddlePaddle/ERNIE
- Take Away: 通过knowledge masking学到隐含的实体以及短语内部一致信息

ERNIE的主要创新是在预训练阶段引入了knowledge masking,这里的knowledge包括短语和实体两种。所以ERINE定位知识的方式是通过分词定位短语,以及通过实体匹配定位到实体。对比BERT对独立token进行掩码,ERNIE分阶段采用token,phrase和entity这三种不同粒度的span进行掩码。实体和短语内部的字符,因为被同时掩码,所以会被相同的上下文信息进行梯度更新,使得token之间学到内部关联信息,以及更清晰的实体边界信息,在NER等局部信息抽取任务上更有优势。不过模型本身并没有引入更丰富的实体关联等知识信息~
THU-ERNIE
- paper:ERNIE: Enhanced Language Representation with Informative Entities
- github: https://github.com/thunlp/ERNIE
- Take Away: 引入KG预训练Embedding,通过FusionLayer进行知识融入
论起名的重要性,这两篇ERNIE其实是完全不同的方向。THU-ERNIE更完整的给出了在预训练中融入知识的方案。THU-ERNIE由T-Encoder和K-Encoder构成,其中T-Encoder就是常规的Transformer Block用来学习基于上下文的文本表征,而K-Encoder负责知识表征和融入,同时ERNIE设计了新的预训练目标dAE来辅助知识信息融入。以’Bob Dylan wrote Blowin in the Wind in 1962‘为例,分别看下THU-ERNIE如何定位,表征和融入知识
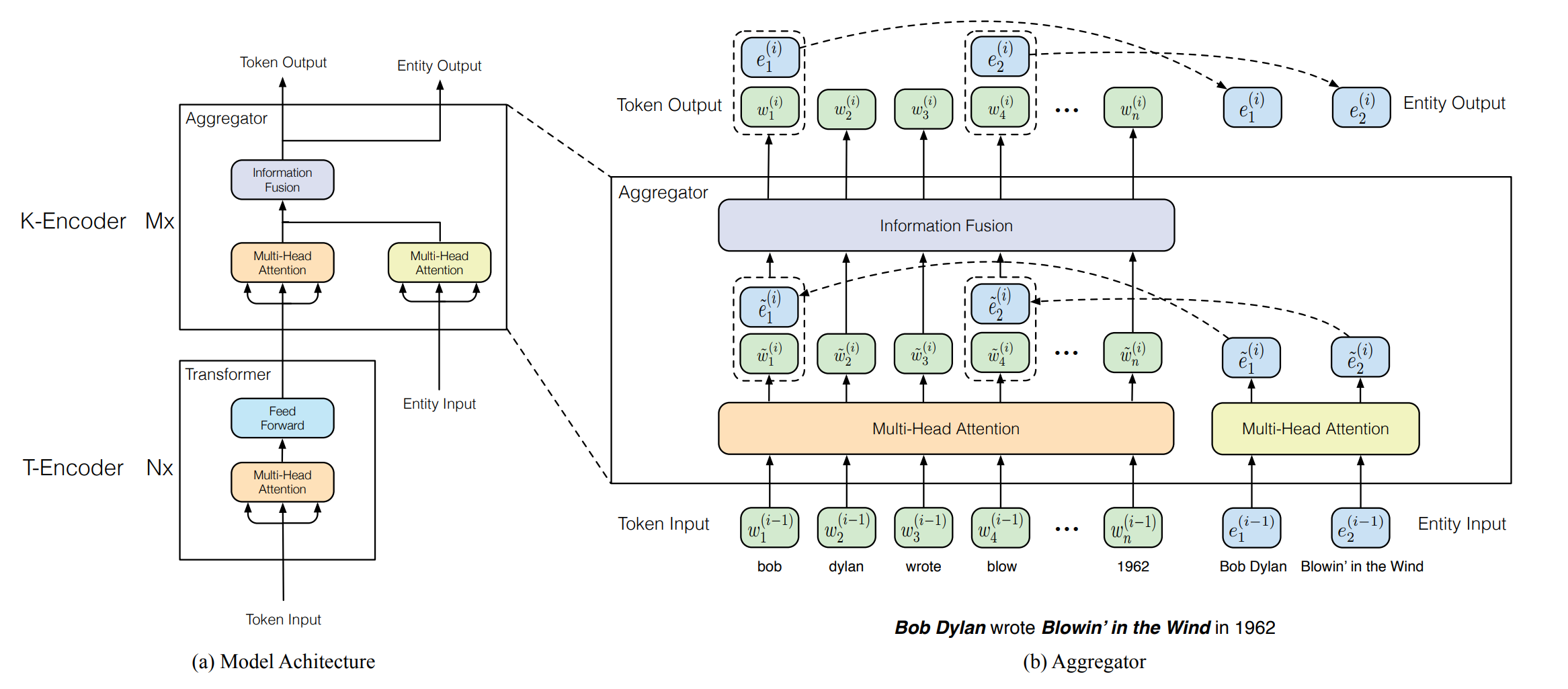
knowledge Encoder
ERNIE通过TAGME从句子中定位到实体知{e1, ...en},并使用TransE预训练的实体embedding作为知识表征。在知识融入上,首先原始文本输入会过T-Encoder得到考虑上下文的文本表征,然后会通过K-Encoder中的多个Aggregator层进行知识融合,这里的知识融合包括知识表征和文本表征的对齐以及双方的信息交互。每个Aggregator层由两部分构成
- 多头注意:文本表征W和实体表征E分别各自做多头注意力,文本表征是上下文交互,实体表征是学习实体关联
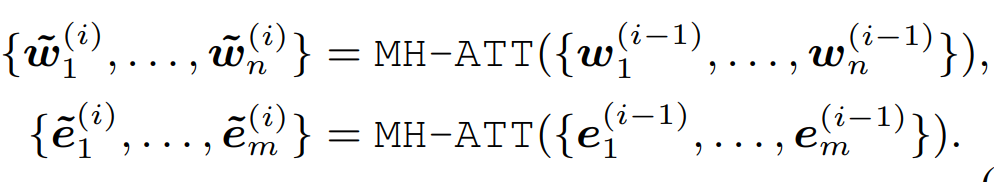
- Fusion:多头输出的文本表征和实体表征进行拼接[w,e],过feed forward来进行信息融合,这里的激活函数选用了gelu。对于非实体的文本因为没有相关联的实体所以等同于拼接了全0向量。融合表征h分别做两次非线性映射得到文本和实体的表征,作为下一层aggregator的输入。
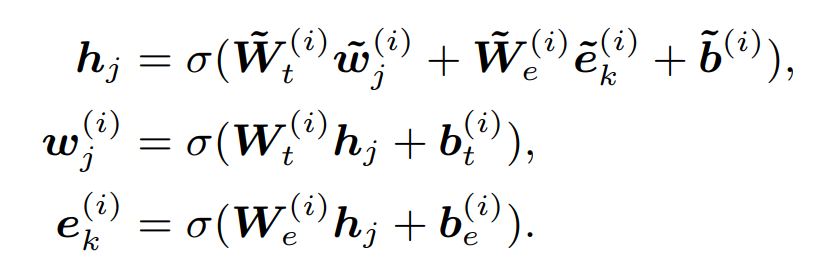
预训练任务dAE

作者在MLM和NSP的预训练任务的基础上,加入了实体还原dAE任务,来帮助模型融合知识相关信息。同样是AutoEncoder任务,实体还原和MLM任务主要有两个差异
- 掩码差异:dAE采用5%随机实体掩码,15%同时对token和实体掩码,85%保持不变的掩码策略
- 还原差异:和token还原相比,实体还原采用了负采样的逻辑,没有从全部KG实体中进行预测,而是只从当前句子的所有实体中去选择MASK位置的实体。
整体上dAE的任务设计偏简单,首先是掩码部分和BERT只保留10%的原始token相比,dAE85%的概率都保留原始token;同时还原任务只使用当前句子的实体作为候选,候选集较小。至于为什么把任务调整的更加简单,作者只简单说是因为token-entity对齐会存在一定error,不过我对这部分的任务设计还是有些疑惑~有了解的同学求解答
ERNIE的预训练过程使用了google BERT的参数来初始化T-Encoder,TransE的实体Embedding在训练过程中是Freeze的,K-Encoder的参数会随机初始化。效果上在Entity Typing和Relation Classification上都有较明显的效果提升
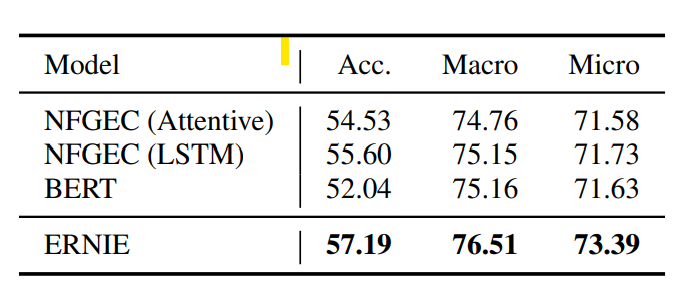
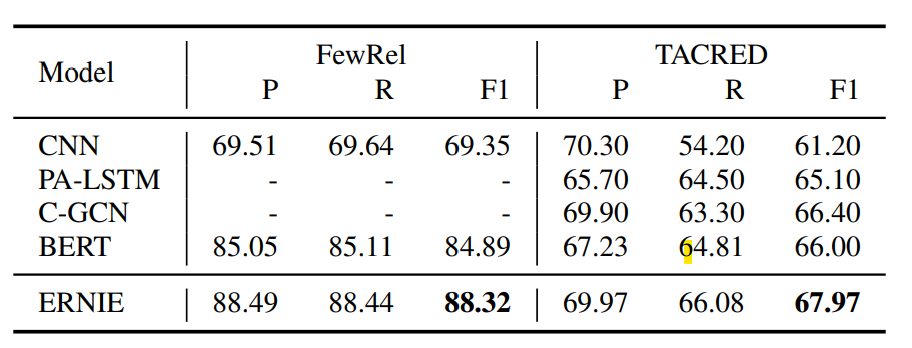
在常规的GLUE Benchmark上,针对样本量较大的任务ERNIE和BERT持平,但是对样本较小的任务上存在波动有好有坏,不过波动本身并不小。。。所以感觉不太能说明实体信息引入完全没有影响到原始上下文信息
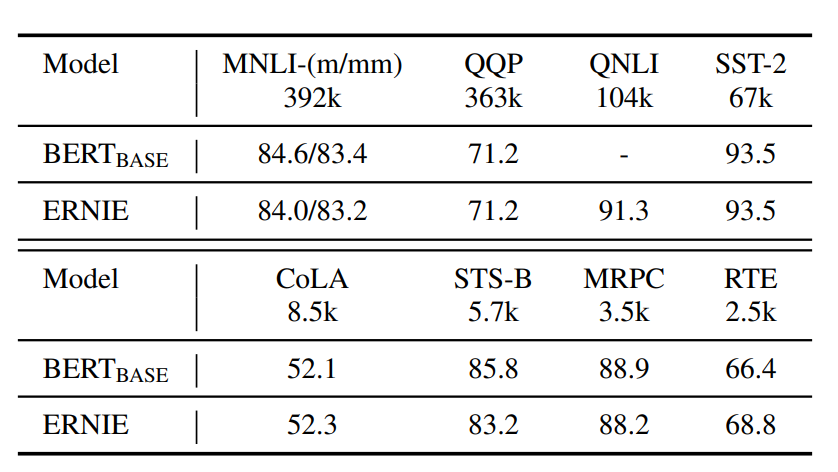
整体上ERNIE的效果提升还是显著的,几个能想到的讨论方向有
- 预训练任务的优化
- 特殊处理引入实体信息后可能对上下文语义产生的影响
- 模型本身因为额外的K-Encoder的加入,模型复杂度较高,想要落地难度较大
K-BERT
- paper: ERNIE: Enhanced Language Representation with Informative Entities
- gitub: https://github.com/autoliuweijie/K-BERT
- Take Away: 通过soft MASK和soft PE在引入知识表征的同时不影响原有文本语义
K_BERT通过soft-Mask和soft-position,在不影响原始语义的情况下,把知识图谱的3元组信息直接融入文本表征。以’CLS Tim Cook is visiting Beijing Now‘ 为例,分别看下K-bert如何定位,表征和融入知识
knowledge Layer
K-bert在输入层之前加入知识层,负责知识的定位和表征。K-Bert通过字符匹配的方式先定位到句子中的实体,然后去图谱中请求实体相关的全部3元组。句子中的Tim Cook和Beijing实体,分别能请求到如下三元组:[Tim Cook, CEO, Apple], [Beijing, capital, China],[Beijing, is_a , City]。这里请求深度为1,也就是Beijing请求得到的China后,不会用China去进一步检索。所有请求到的三元组会构建如下的句子树
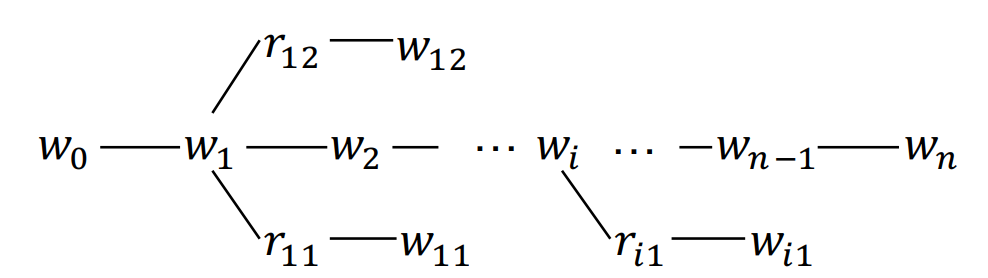
定位到知识后,在知识表征上K-Bert没有引入图谱相关的预训练知识表征,而是选择把三元组信息和原始token一同输入模型,使用相同的token embedding来进行语义表征。所以需要对以上的句子树进行展开,展开的顺序是按照原始句子遍历,如果碰到分支就把分支的token加入,然后继续遍历原始句子,展开后的句子如下。输入和BERT相同是token+position+segment embedding

Seeing Layer & position Encoding
不过以上的知识表征方式存在一个问题,就是对句子树进行展开时,人为引入了噪音,主要包括3个方面
- 因为知识的插入,人为改变了原始句子中token间的距离
- 插入知识后的句子并不符合常规的文本表达
- 引入的知识和其他知识以及其他与文本交互时会引入噪音,例如Apple和China不应该存在显示的交互
针对这些问题,作者提出了Soft—PE和Soft-MASK的实现。核心就是让原始token的PE保持不变,原始token之间的交互不变,每个token只和自己的知识进行交互。
Soft-PE就是保持原始句子的位置编码不变,对于插入的知识会从实体的位置开始向后顺延,于是会存在重复的PE,例如is在原始句子中的位置id是3,CEO对应的实体是TimCook位置是2,顺延后位置id也是3,他们的位置编码就是相同的,这样就解决了以上的问题1
Soft-Mask就是通过掩码对知识部分进行隔离,CEO Apple只和Tim Cook进行交互,不和其他token进行交互,保证知识的引入只是为当前实体提供补充信息,不会干扰整体上下文语义,也不会和其他token交互引入噪音,这样就解决了以上的问题2和3
作者也通过消融实验证明了,如果不使用Soft-MASK和Soft-PE, k-bert的效果会显著低于原始BERT。

训练
K-Bert只在下游任务微调中使用了KG,核心问题在于如果在预训练中加入KG,因为知识表征中使用了和原始文本相同的词向量,所以会导致实体三元组中两个实体的文本表征变得变得高度相似,导致语义信息损失。所以K-Bert只在微调中引入了实体三元组信息。
效果上,医疗领域KG对医疗NER的效果提升最明显,通用知识KG对与金融和法律的NER有部分提升,对推理类任务有微小提升,情感分类任务因为和知识关系不大所以效果有限~
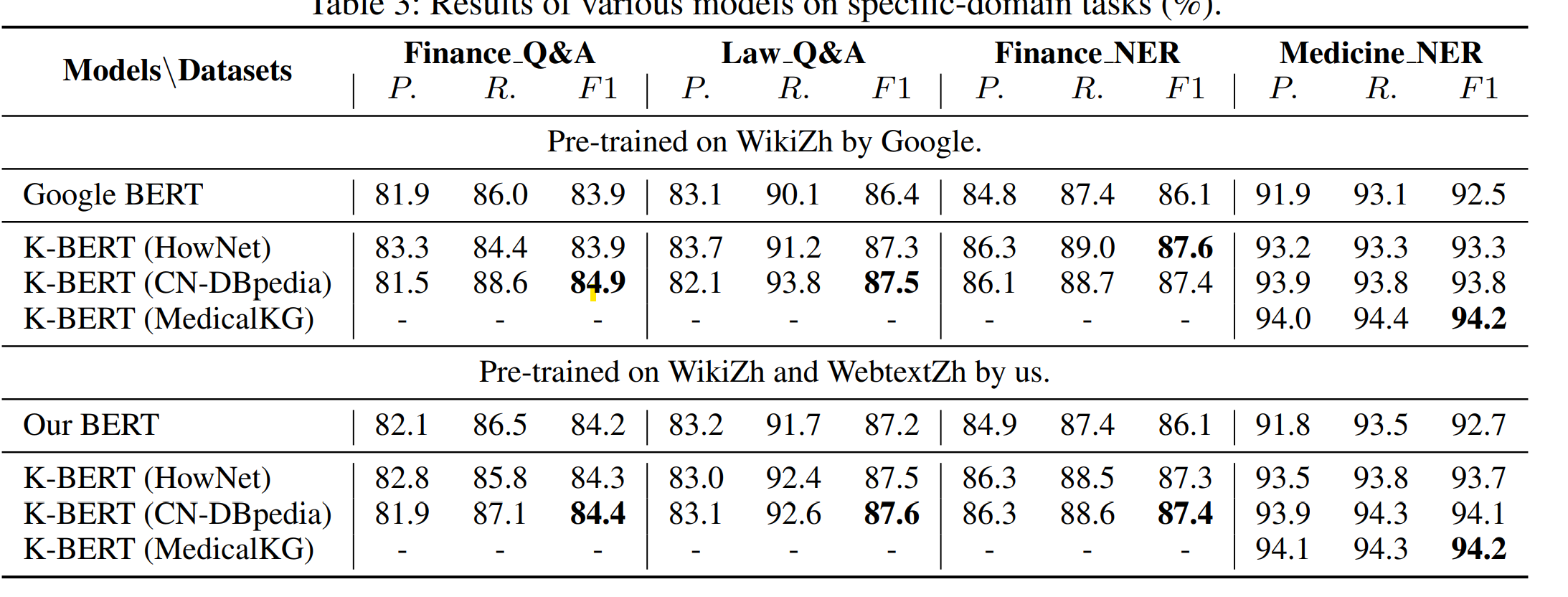
K-BERT只在微调中引入KG的好处是迁移到不同领域的成本较低,几个能想到的讨论点有
- 微调中引入知识,微调的样本量和拟合目标一定程度限制了KG的融合效果
- Soft-MASK矩阵的构造成本较高,batch中的每个句子都需要独立构造掩码矩阵
- 复用文本token来表征知识信息,虽然解决了知识表征和文本表征不一致的问题,但是只引入实体三元组信息,会丢失掉KG中更丰富的关联信息
Reference
Bert不完全手册7. 为Bert注入知识的力量 Baidu-ERNIE & THU-ERNIE & KBert的更多相关文章
- Bert不完全手册6. Bert在中文领域的尝试 Bert-WWM & MacBert & ChineseBert
一章我们来聊聊在中文领域都有哪些预训练模型的改良方案.Bert-WWM,MacBert,ChineseBert主要从3个方向在预训练中补充中文文本的信息:词粒度信息,中文笔画信息,拼音信息.与其说是推 ...
- Bert不完全手册8. 预训练不要停!Continue Pretraining
paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks GitHub: https://github.com ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- Bert不完全手册1. 推理太慢?模型蒸馏
模型蒸馏的目标主要用于模型的线上部署,解决Bert太大,推理太慢的问题.因此用一个小模型去逼近大模型的效果,实现的方式一般是Teacher-Stuent框架,先用大模型(Teacher)去对样本进行拟 ...
- Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场 ...
- Bert不完全手册3. Bert训练策略优化!RoBERTa & SpanBERT
之前看过一条评论说Bert提出了很好的双向语言模型的预训练以及下游迁移的框架,但是它提出的各种训练方式槽点较多,或多或少都有优化的空间.这一章就训练方案的改良,我们来聊聊RoBERTa和SpanBER ...
- Bert不完全手册5. 推理提速?训练提速!内存压缩!Albert
Albert是A Lite Bert的缩写,确实Albert通过词向量矩阵分解,以及transformer block的参数共享,大大降低了Bert的参数量级.在我读Albert论文之前,因为Albe ...
- Bert不完全手册9. 长文本建模 BigBird & Longformer & Reformer & Performer
这一章我们来唠唠如何优化BERT对文本长度的限制.BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力.不过Attention本身O(n^2)的计算和内存复杂度,也限制了Tr ...
- ERNIE:知识图谱结合BERT才是「有文化」的语言模型
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一.例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 N ...
随机推荐
- [算法学习] dsu on tree
简介 dsu on tree跟dsu没有关系,但是dsu on tree借鉴了dsu的启发式合并的思想. 它是用来解决一类树上的询问问题,一般这种问题有以下特征: \(1.\)只有对子树的查询: \( ...
- VS Code - Vim 插件自动切换输入法
前言: 在使用 Linux 的过程中,vim 是一个不错的编辑器,以至于多数人将其用成了习惯,在没有 vim 的环境下还是习惯用 vim 的快捷键来编辑文本.所以便有开发者们为众多的 IDE 和文本编 ...
- 【freertos】010-消息队列概念及其实现细节
目录 前言 10.1 消息队列概念 10.2 消息队列的数据传输机制 10.3 消息队列的阻塞访问机制 10.4 消息队列使用场景 10.5 消息队列控制块 10.5.1 队列控制块源码 10.5.2 ...
- Python3 filter()函数和map()函数
filter(function or None,iterable) 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换. 该接收两个参数,第 ...
- BI与SaaS碰撞,让数据处理更加轻松(下)
背景 在上篇内容中,我们从SaaS各种功能的角度为大家介绍了在数据处理中SaaS的巨大价值,而本次我们将用实例将为大家展示SaaS与BI间的碰撞又会产生怎样的火花. BI与SaaS集成示例 通常BI分 ...
- 29.MySQL高级SQL语句
MySQL高级SQL语句 目录 MySQL高级SQL语句 创建两个表 SELECT DISTINCT WHERE AND OR IN BETWEEN 通配符 LIKE ORDER BY 函数 数学函数 ...
- Mybatisi和Spring整合源码分析
一.MybatisSpring的使用 1.创建 Maven 工程. 2.添加依赖,代码如下 <dependency> <groupId>org.mybatis</grou ...
- # 【由浅入深_打牢基础】WEB缓存投毒(上)
image-20220611092344882 [由浅入深_打牢基础]WEB缓存投毒(上) 1. 什么是WEB缓存投毒 简单的来说,就是利用缓存将有害的HTTP响应提供给用户 什么是缓存,这里借用Bu ...
- UiPath存在图像Image Exists的介绍和使用
一.Image Exists的介绍 检查是否在指定的UI元素中找到图像,输出的是一个布尔值 二.Image Exists在UiPath中的使用 1. 打开设计器,在设计库中新建一个Sequence,为 ...
- get前言之版本控制-get和SVN的区别
版本控制什么是版本控制版本控制(Revision control)是一种在开发的过程中用于管理我们对文件.目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术. ~实 ...