repulsion-loss
行人检测中的mr,fppi这些指标???
3种距离:欧式距离、SmoothL1距离、IoU距离
总的loss公式:3个部分组成Lattr是预测框和匹配的gt尽可能接近,Lrepgt是预测框和周围没匹配的gt尽可能远离 ,Lrepbox是预测框和周围的其他预测框尽可能远离
整体上loss的计算是针对每个正样本的预测框
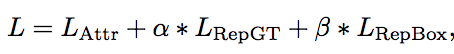
p+是所有的正样本proposal的集合
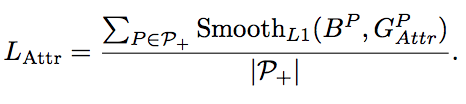
Lattr是为了公平的对比,依旧采用了smoothL1
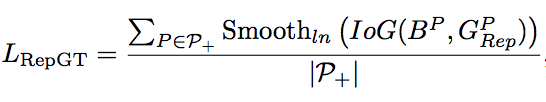
1.Lrepgt中G的公式如下:
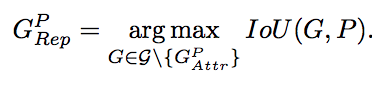
也就是说G是除了与预测框匹配的gt意外所有其他剩下的gt中与预测框iou最大的gt
2.Lrepgt采用的smoothLn和iog
为什么使用iog、iou+smoothLn,而不使用smoothl1?
原论文中说:smoothl1是让预测框和遮挡的gt越来越远,但iog、iou+smoothLn是缩小两者的交集,更符合motivation
为什么采用iog,而不使用iou?
首先明确gt框的大小和位置是不变的,如果使用iou,可能会通过放大预测框的方式来降低loss,也就是通过增大并集,iou的分母部分(当然这种情况也可能分子也会增加,但最大的可能是分子的增加赶不上分母的增加);使用iog,就只能优化分子部分,也就是两个框的交集部分,这也是作者的目的(当然最想要的是预测框远离另一个gt,但也可能通过缩小预测框达到这个目的,不过总比iou这种好)。总的来说,iou会比iog多一个优化的变量,让可能的优化的目标走偏,并且iog更符合作者的motivation
进一步问题:为什么不是远离,而是让两者的交集越来越小?

这个loss的目的是使预测框远离相邻不是预测同一真实目标的预测框。首先根据真实目标框GT将P_+分为不同的子集, ,然后使得来自与不同子集的proposal的overlap尽可能的小。分母中的示性函数,其实就是iou大于0就直接输出结果,iou等于0就输出0,表示的意思是:必须是有交集的预测框才计入损失值,如果两个proposal完全不相邻,则不计入。
,然后使得来自与不同子集的proposal的overlap尽可能的小。分母中的示性函数,其实就是iou大于0就直接输出结果,iou等于0就输出0,表示的意思是:必须是有交集的预测框才计入损失值,如果两个proposal完全不相邻,则不计入。
这个为什么能解决nms的问题???
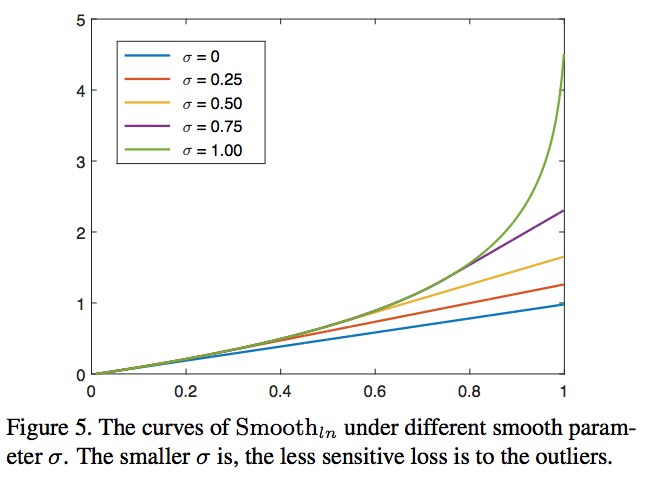
delta越小,对异常值就越不敏感。iou或者iog的取值在[0,1]之间,一般来说1这种就算异常值了,可以看到delta越小,取值就越小,并且相对于其他值变化不是那么大,这样就越不敏感了。
这其实类似于smoothl1跟l2-loss的对比关系,smoothl1相对于l2-loss对异常值更加不敏感。
正如Smooth_l1不会对特别大的偏差给予过大的penalty,Smooth_ln对于很小接近于1的输入也不会像原始的ln函数一样给予负无穷那么大的loss,从而可以稳定训练过程,而且对抗一些outlier。
RepBox相对于RepGT有更多的outliers,所以应该弱化其对σ的敏感性,论文实验中RepGT和RepBox分别在σ=1和σ=0取得更好的效果。
当delta为1时,就跟iou-loss一样,-ln(1-IoG) (unitbox)
https://zhuanlan.zhihu.com/p/43655912
https://www.zhihu.com/search?type=content&q=repulsion%20loss
https://blog.csdn.net/weixin_42615068/article/details/82391354
repulsion-loss的一个实现:https://github.com/JegernOUTT/repulsion_loss/blob/master/repulsion_loss.py
repulsion-loss的更多相关文章
- 目标检测——深度学习下的小目标检测(检测难的原因和Tricks)
小目标难检测原因 主要原因 (1)小目标在原图中尺寸比较小,通用目标检测模型中,一般的基础骨干神经网络(VGG系列和Resnet系列)都有几次下采样处理,导致小目标在特征图的尺寸基本上只有个位数的像素 ...
- caffe的python接口学习(7):绘制loss和accuracy曲线
使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupy ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- loss function
什么是loss? loss: loss是我们用来对模型满意程度的指标.loss设计的原则是:模型越好loss越低,模型越差loss越高,但也有过拟合的情况. loss function: 在分 ...
- caffe中accuracy和loss用python从log日志里面获取
import re import pylab as pl import numpy as np if __name__=="__main__": accuracys=[] loss ...
- Derivative of the softmax loss function
Back-propagation in a nerual network with a Softmax classifier, which uses the Softmax function: \[\ ...
- How To Handle a Loss of Confidence in Yourself
Do you feel like you've lost confidence in yourself? Have you had strong self doubts? Perhaps you we ...
- loss function与cost function
实际上,代价函数(cost function)和损失函数(loss function 亦称为 error function)是同义的.它们都是事先定义一个假设函数(hypothesis),通过训练集由 ...
- Fragment提交transaction导致state loss异常
下面自从Honeycomb发布后,下面栈跟踪信息和异常信息已经困扰了StackOverFlow很久了. java.lang.IllegalStateException: Can not perform ...
随机推荐
- python中GIL和线程与进程
线程与全局解释器锁(GIL) 一.线程概论 1.何为线程 每个进程有一个地址空间,而且默认就有一个控制线程.如果把一个进程比喻为一个车间的工作过程那么线程就是车间里的一个一个流水线. 进程只是用来把资 ...
- 原型相关的方法isPrototypeOf、Object.getPrototypeOf、hasOwnProperty、Object.getOwnPropertyName、Object.keys
在看<高程3>第六章的<面向对象的程序设计>的原型那一节时,有一下5个函数,功能较为接近,但是又都很基础,很重要 所以在此,加以说明,以便日后复习 function Perso ...
- Spring Boot—20Zookeeper
https://docs.spring.io/spring-boot/docs/2.0.1.RELEASE/reference/htmlsingle/ pom.xml <dependency&g ...
- JavaScript写九九乘法表
<script language=javascript> for(i=1;i<=9;i++){ for(j=1;j<=9;j++){ document.write (i+&qu ...
- OneNet平台初探成功
1.经过半个月的研究,终于成功对接OneNet平台,实现远程控制LED灯的亮灭 2.在调试的过程中也遇到了很多问题,做一下总结 3.硬件:STM32F103C8T6的最小系统板,ESP8266-WiF ...
- LeetCode题解之Find the Difference
1.题目描述 2.题目分析 比较两个字符串中加入的一个字符,由于可能在字符串中加入一个已经存在的字符,因此使用hash table 去统计字符个数最好. 3.代码 char findTheDiffer ...
- leetCode题解之Array Partition I
1.题目描述 2.分析 按照题目要求,主要就是对数组进行排序 3.代码 int arrayPairSum(vector<int>& nums) { ; sort( nums.beg ...
- 如何在 Azure 中均衡 Linux 虚拟机负载以创建高可用性应用程序
负载均衡通过将传入请求分布到多个虚拟机来提供更高级别的可用性. 本教程介绍了 Azure 负载均衡器的不同组件,这些组件用于分发流量和提供高可用性. 你将学习如何执行以下操作: 创建 Azure 负载 ...
- 关于SQL Server 2017中使用json传参时解析遇到的多层解析问题
开发新的系统,DB部分使用了SQL Server从2016版开始自带的Json解析方式. 用了快半年,在个人项目,以及公司部分项目上使用了,暂时还没遇到大的问题,和性能问题. 今天在解析Json的多级 ...
- MySQL的前缀索引及Oracle的类似实现
MySQL有一个很有意思的索引类型,叫做前缀索引,它可以给某个文本字段的前面部分单独做索引,从而降低索引的大小. 其实,Oracle也有类似的实现,对于文本,它可以通过substr的函数索引,实现同样 ...