Django_rest_framework_渲染器/解析器/路由控制/分页
目录
渲染器
简介
什么是渲染器
根据 用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件。
渲染器的作用
序列化、友好的展示数据
渲染器配置
首先要在settins.py中将rest_framework组件加进去
局部配置渲染器
引入渲染器类,然后将他们作为一个列表的元素赋值给renderer_classes 配置属性,如下:
|
1
2
3
4
5
6
|
from rest_framework.renderers import JSONRenderer,BrowsableAPIRendererclass BookViewSet(APIView): renderer_classes = [JSONRenderer,BrowsableAPIRenderer] def get(self,request): return Response('...') |
BrowsableAPIRenderer的渲染效果如下
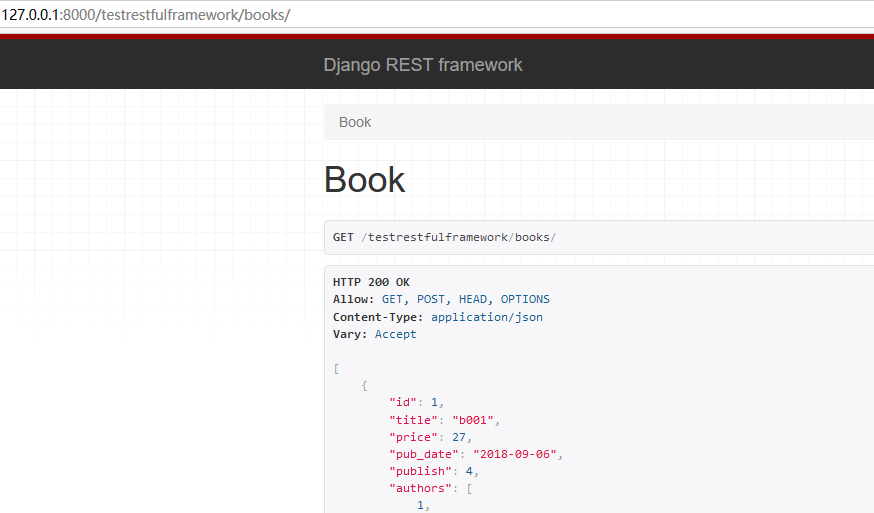
|
1
|
JSONRenderer类的就是只渲染数据,如下: |
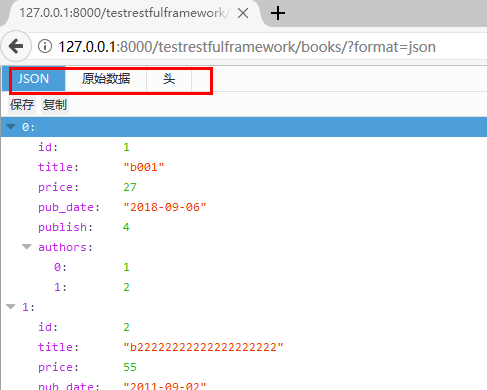
可以看到,只是简单的数据展示
全局配置渲染器
在setting.py文件中加入如下配置:
|
1
2
3
4
5
|
REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer','rest_framework.renderers.BrowsableAPIRenderer',],...} |
解析器
我们都知道,网络传输数据只能传输字符串格式的,如果是列表、字典等数据类型,需要转换之后才能使用
但是我们之前的rest_framework例子都没有转换就直接可以使用了,这是因为rest_framework有一套解析器,
默认他会帮我们转换3种类型的数据,分别是,JSONParser,FormParser,MultiPartParser
局部解析器
如果我们需要转换其他数据,需要在视图类里配置parser_classes参数,如下:
|
1
2
|
from rest_framework.parsers import JSONParser,FormParser,MultiPartParser,FileUploadParserparser_classes = [JSONParser,FormParser,FileUploadParser] |
全局解析器
REST_FRAMEWORK={
"DEFAULT_PARSER_CLASSES":['rest_framework.parsers.FormParser',]
}
路由控制
我们之前在写例子的时候,视图类已经封装到最精简版本了,但是url变的比之前复杂了,如下:
|
1
2
|
url(r'^publishes/$', views.PublishViewSet.as_view({'get':'list','post':'create'})),url(r'^publishes/(?P<pk>\d+)/$', views.PublishViewSet.as_view({'get':'retrieve','put':'update','delete':'destroy','patch':'partial_update'})), |
上面只是一个视图类对应的url,如果项目做的很大,那么url会变的非常臃肿,
而rest_framework给我们封装了一种自动注册url的功能,格式如下:
|
1
2
3
4
5
6
7
8
9
10
11
|
from django.conf.urls import urlfrom django.contrib import adminfrom app01 import viewsfrom django.conf.urls import includefrom rest_framework import routers# 实例化一个routers对象routers = routers.DefaultRouter()# 往对象里注册(添加)urlrouters.register('publishes',views.PublishViewSet) |
然后,在urlpatterns中添加已经注册的url(在routers.urls里),如下:
|
1
|
url(r'',include(routers.urls)) |
完整版的urlpatterns配置
|
1
2
3
4
5
6
7
8
9
10
11
|
urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^login/', views.Login.as_view()), url(r'^authors/$', views.AuthorsView.as_view()), url(r'^authors/(\d+)/$', views.AuthorsDetailView.as_view()), url(r'',include(routers.urls))] |
这个时候,rest_framework会帮我们自动添加了4个url,如下图:
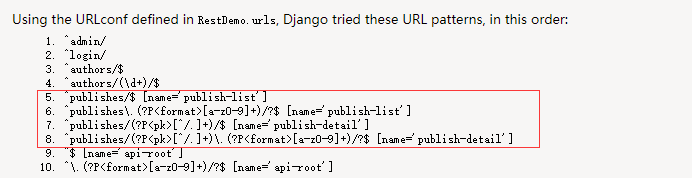
示例
from django.contrib import admin
from django.urls import path,re_path,include urlpatterns = [
re_path("testrestfulframework/",include("testrestfulframework.urls")),
] ####### testrestfulframework.urls.py ###########
from django.urls import path,re_path,include
from testrestfulframework import views
from rest_framework import routers # 实例化一个routers对象
routers = routers.DefaultRouter()
# 往对象里注册(添加)url
routers.register('books', views.BookViewSet)
routers.register('publish', views.PublishViewSet) urlpatterns = [
# re_path(r"login/$",views.LoginViewSet.as_view()),
# re_path(r"books/$",views.BookViewSet.as_view()),
# re_path(r"books/(?P<pk>\d+)$",views.BookDetailViewSet.as_view()),
re_path(r'',include(routers.urls)),
] urls.py
urls.py
from django.db import models class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish",on_delete=models.CASCADE)
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name class User(models.Model):
username = models.CharField(max_length=16)
password = models.CharField(max_length=64)
role = models.IntegerField(default=1) class Token(models.Model):
token = models.CharField(max_length=128)
user = models.ForeignKey(to=User,on_delete=models.CASCADE)
models.py
# -*- coding:utf-8 -*-
from rest_framework import serializers
from testrestfulframework import models class BookSerializers(serializers.ModelSerializer):
# publish = serializers.HyperlinkedIdentityField(
# view_name='publish_detail',
# lookup_field="publish_id",
# lookup_url_kwarg="pk") class Meta:
model = models.Book
fields = "__all__"
# depth=1 class PublshSerializers(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = "__all__"
# depth = 1 class AuthorSerializers(serializers.ModelSerializer): class Meta:
model = models.Author
fields = "__all__"
# depth = 1
serializers.py
from rest_framework import viewsets
from testrestfulframework import models
from testrestfulframework import serializers class BookViewSet(viewsets.ModelViewSet):
queryset = models.Book.objects.all()
serializer_class = serializers.BookSerializers class PublishViewSet(viewsets.ModelViewSet):
queryset = models.Publish.objects.all()
serializer_class = serializers.PublshSerializers
views.py

分页
分页种类
# service/pagination.py from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination class MyPageNumberPagination(PageNumberPagination):
# 定义一个PageNumberPagination的子类
# 如需改变参数,重写其属性即可
page_size = 2 #每页显示条数
page_query_param = 'page' # url中的参数的key
page_size_query_param="size" # 可以在url中使用size参数临时改变当页显示的数目
max_page_size=10 # 可以在url中使用size参数临时改变当页显示的数目,但是最大只能显示10条。格式:url?size=20 class MyLimitOffsetPagination(LimitOffsetPagination):
default_limit =10#一页默认几个
limit_query_param = 'limit' #关键字后面跟的是一页显示几个
offset_query_param = 'offset'#这个后面跟的是从哪里显示
max_limit = 50 #可以在url中使用limit参数临时改变当页显示的数目,但是最大只能显示50条。格式:url?limit=20 class MyCursorPagination(CursorPagination):
cursor_query_param = 'cursor'#关键字,c
page_size =5 #每页默认的数量
ordering = 'price'#按照id排列
page_size_query_param ='page_size'#每页显示的数量
继承APIView类的视图中添加分页
class AuthorsView(APIView):
def get(self,request):
'''分页展示作者列表'''
author_list = models.Author.objects.all()
# 分页
# 实例化一个自己定义的MyPageNumberPagination对象
pnp = MyPageNumberPagination()
# 调用paginate_queryset方法来生成新的author_list
# 参数分别为,author_list,request以及当前的视图
page_author_list = pnp.paginate_queryset(author_list,request,self)
# 在将新生成的page_author_list序列化
auts = serializer.AuthorModelSerializers(page_author_list,many=True)
return Response(auts.data)
class BaseResponse(object):
def __init__(self,code=1000,data=None,error=None):
self.code=code
self.data=data
self.error=error class IndexView(APIView):
def get(self,request,*args,**kwargs):
ret=BaseResponse()
try:
user_list=models.UserInfo.objects.all()#找到所有的数据项
p1 = P1()#实例化分页器,
page_user_list=p1.paginate_queryset(queryset=user_list,request=request,view=self)#把数据放在分页器上面
ser=IndexSerializer(instance=page_user_list,many=True)#序列化数据
ret.data=ser.data
ret.next=p1.get_next_link()
except Exception as e:
ret.code=1001
ret.error='xxxx错误'
另一个例子
继承ModelViewSet类的视图中添加分页
如果我们的视图继承了ModelViewSet类,那么如需分页的时候,只需要在视图类中加入配置参数即可,如下:
|
1
|
pagination_class = MyPageNumberPagination |
注意:
1、MyPageNumberPagination类是我们自己定义的类,见上面一个示例。
2、pagination_class后面直接跟上类名即可,无需加列表(因为分页不想其他组件,分页只可能有一个)
全局配置分页属性
只需要在REST_FRAMEWORK配置中加入 配置属性的键值对即可,如下:
|
1
2
3
4
|
REST_FRAMEWORK = { ..... "PAGE_SIZE":1} |
示例
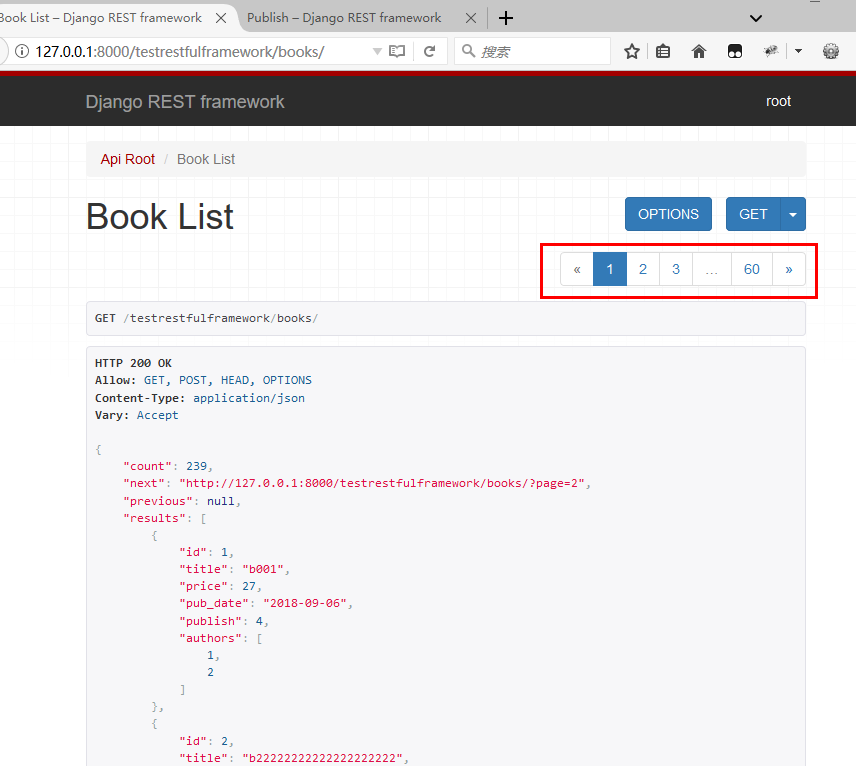
以上多种方式均实现了3中分页方式PageNumberPagination,LimitOffsetPagination,CursorPagination,过程略。
参考or转发
https://www.cnblogs.com/fu-yong/p/9104400.html
http://www.cnblogs.com/fu-yong/p/9067690.html
Django_rest_framework_渲染器/解析器/路由控制/分页的更多相关文章
- 5 解析器、url路由控制、分页、渲染器和版本
1 数据解析器 1 什么是解析器 相当于request 中content-type 对方传什么类型的数据,我接受什么样的数据:怎样解析 无论前面传的是什么数据,都可以解开 例如:django不能解析j ...
- Django REST Framework - 分页 - 渲染器 - 解析器
为什么要使用分页? 我们数据表中可能会有成千上万条数据,当我们访问某张表的所有数据时,我们不太可能需要一次把所有的数据都展示出来,因为数据量很大,对服务端的内存压力比较大还有就是网络传输过程中耗时也会 ...
- SpringMVC源码情操陶冶-InterceptorsBeanDefinitionParser拦截器解析器
解析mvc:interceptors节点 观察下InterceptorsBeanDefinitionParser的源码备注 /** * {@link org.springframework.beans ...
- Django-restframework之路由控制、解析器及响应器
django-restframework之路由控制.解析器及响应器 一 前言 本篇博客介绍 restframework 框架的剩下几个组件,路由控制有三种:传统路由.半自动路由及全自动路由:解析器是用 ...
- DRF频率、分页、解析器、渲染器
DRF的频率 频率限制是做什么的 开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用. 频率组件原理 DRF中的频率控制基本原理是基于访问次数和时间的,当然我们可以通过自己定 ...
- drf 解析器,响应器,路由控制
解析器 作用: 根据请求头 content-type 选择对应的解析器对请求体内容进行处理. 有application/json,x-www-form-urlencoded,form-data等格式 ...
- restframework 解析器、渲染器、url控制组件
一.解析器 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 1.分类 from rest_framework.parsers impo ...
- Django REST framework解析器和渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
- Django REST framework基础:解析器和渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
随机推荐
- 最简单的ASP.Net连接查询Oracle,输出查询数据到表格中
VS2012中新建Windows窗体应用程序.Oracle中建测试数据表Test.(此处需要环境已配好情况下进行操作) 用到的数据表 向Windows窗体应用程序,设计界面托一个按钮和一个数据表格视图 ...
- Lambda 表达式语法
本主题介绍 lambda 表达式的语法. 它演示提供 lambda 表达式的结构元素的示例,这些元素与示例. Lambda 表达式语法 下面用于定义显示语法,ISO C++11 从标准,lambda ...
- 学习JavaSE TCP/IP协议与搭建简易聊天室
一.TCP/IP协议 1.TCP/IP协议包括TCP.IP和UDP等 2.域名通过dns服务器转换为IP地址 3.局域网可以通过IP或者主机地址寻找到相应的主机 4.TCP是可靠的连接,效率低,且连接 ...
- dataTable配置项说明
Datatables是一款jquery表格插件.它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能. 官网地址:https://datatables.net/ 中文说明地址:http:/ ...
- 【PHP开发规范】继承与扩展:PSR-2 编码风格规范
之前的一篇文章是对PSR-1的基本介绍 接下来是PSR-2 编码风格规范,它是 PSR-1 基本代码规范的继承与扩展. PSR-1 和PSR-2是PHP开发中基本的编码规范,大家其实都可以参考学习下, ...
- hadoop体系架构
1.1 Hadoop 概念:hadoop是一个由Apache基金会所开发的分布式系统基础架构.是根据google发表的GFS(Google File System)论文产生过来的. ...
- Web安全0001 - MySQL SQL注入 - 如何寻找注入点
注:本文是学习网易Web安全进阶课的笔记,特此声明. 其他数据库也可以参考寻找注入点. A: 一.信息搜集(百度) 1.无特定目标 inurl:.php?id= 2.有特定目标 inurl:.php? ...
- linux 监控文件变化
介绍 有时候我们常需要当文件变化的时候便触发某些脚本操作,比如说有文件更新了就同步文件到远程机器.在实现这个操作上,主要用到两个工具,一个是rsync,一个是inotifywait .inotifyw ...
- JavaEE笔记(八)
第一个Spring Student(学生) bean package com.my.bean; import java.io.Serializable; public class Student im ...
- Noip前的大抱佛脚----数论
目录 数论 知识点 Exgcd 逆元 gcd 欧拉函数\(\varphi(x)\) CRT&EXCRT BSGS&EXBSGS FFT/NTT/MTT/FWT 组合公式 斯特林数 卡塔 ...