HashMap+双向链表手写LRU缓存算法/页面置换算法
import java.util.Hashtable;
class DLinkedList {
String key; //键
int value; //值
DLinkedList pre; //双向链表前驱
DLinkedList next; //双向链表后继
}
public class LRUCache {
private Hashtable<String,DLinkedList> cache = new Hashtable<String,DLinkedList>();
private int count;
private int capacity;
private DLinkedList head, tail;
public LRUCache(int capacity) {
this.count = 0;
this.capacity = capacity;
head = new DLinkedList();
head.pre = null;
tail = new DLinkedList();
tail.next = null;
head.next = tail;
tail.pre = head;
}
public int get(String key) {
DLinkedList node = cache.get(key);
if(node == null) return -1;
this.moveToHead(node);
return node.value;
}
public void set(String key,int value) {
DLinkedList node = cache.get(key);
if(node == null) {
DLinkedList newNode = new DLinkedList();
newNode.key = key;
newNode.value = value;
this.cache.put(key, newNode);
this.addNode(newNode);
++count;
if(count>capacity) {
DLinkedList tail = this.popTail();
this.cache.remove(tail.key);
--count;
}
}
else {
node.value = value;
this.moveToHead(node);
}
}
private void addNode(DLinkedList node) {
node.pre = head;
node.next = head.next;
head.next.pre = node;
head.next = node;
}
private void removeNode(DLinkedList node) {
DLinkedList pre = node.pre;
DLinkedList next = node.next;
pre.next = next;
next.pre = pre;
}
private void moveToHead(DLinkedList node) {
this.removeNode(node);
this.addNode(node);
}
private DLinkedList popTail() {
DLinkedList res = tail.pre;
this.removeNode(res);
return res;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
DLinkedList node = head;
while(node != null){
sb.append(String.format("%s:%s ", node.key,node.value));
node = node.next;
}
return sb.toString();
}
public static void main(String[] args) {
LRUCache lru = new LRUCache(3);
lru.set("1", 7);
System.out.println(lru.toString());
lru.set("2", 0);
System.out.println(lru.toString());
lru.set("3", 1);
System.out.println(lru.toString());
lru.set("4", 2);
System.out.println(lru.toString());
lru.get("2");
System.out.println(lru.toString());
lru.set("5", 3);
System.out.println(lru.toString());
lru.get("2");
System.out.println(lru.toString());
lru.set("6", 4);
System.out.println(lru.toString());
/*
0ull:0 1:7 null:0
null:0 2:0 1:7 null:0
null:0 3:1 2:0 1:7 null:0
null:0 4:2 3:1 2:0 null:0
null:0 2:0 4:2 3:1 null:0
null:0 5:3 2:0 4:2 null:0
null:0 2:0 5:3 4:2 null:0
null:0 6:4 2:0 5:3 null:0
*/
}
}
那么如何设计一个LRU缓存,使得放入和移除都是 O(1) 的,我们需要把访问次序维护起来,但是不能通过内存中的真实排序来反应,有一种方案就是使用双向链表。
整体的设计思路是,可以使用 HashMap 存储 key,这样可以做到 save 和 get key的时间都是 O(1),而 HashMap 的 Value 指向双向链表实现的 LRU 的 Node 节点,如图所示。
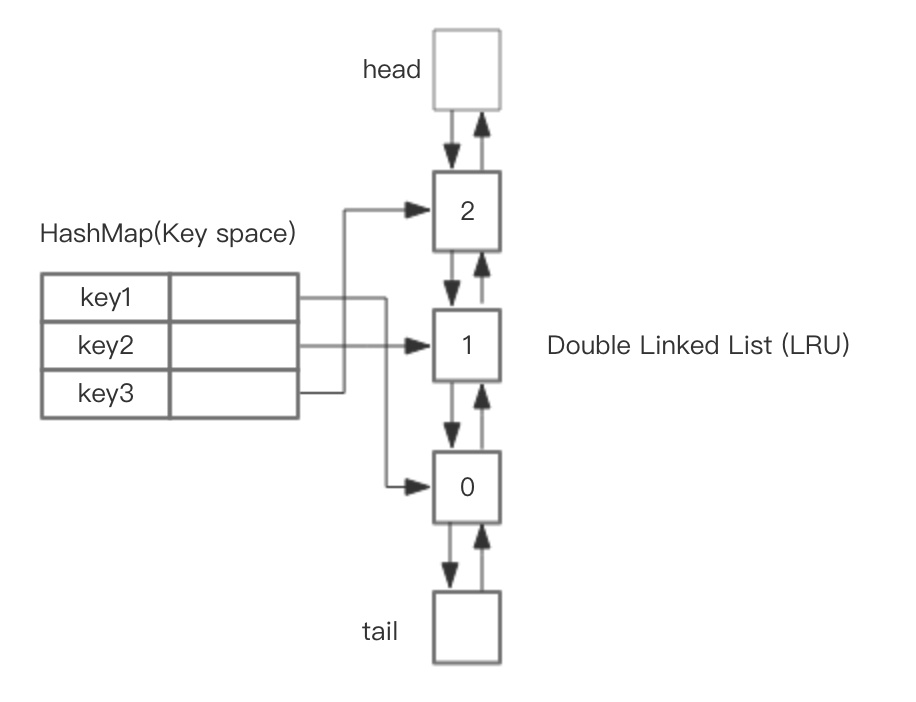
LRU 存储是基于双向链表实现的,下面的图演示了它的原理。其中 head 代表双向链表的表头,tail 代表尾部。首先预先设置 LRU 的容量,如果存储满了,可以通过 O(1) 的时间淘汰掉双向链表的尾部,每次新增和访问数据,都可以通过 O(1)的效率把新的节点增加到对头,或者把已经存在的节点移动到队头。
下面展示了,预设大小是 3 的,LRU存储的在存储和访问过程中的变化。为了简化图复杂度,图中没有展示 HashMap部分的变化,仅仅演示了上图 LRU 双向链表的变化。我们对这个LRU缓存的操作序列如下:
save("key1", 7)
save("key2", 0)
save("key3", 1)
save("key4", 2)
get("key2")
save("key5", 3)
get("key2")
save("key6", 4)
相应的 LRU 双向链表部分变化如下:
 s = save, g = get
s = save, g = get
总结一下核心操作的步骤:
- save(key, value),首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。如果不存在,需要构造新的节点,并且尝试把节点塞到队头,如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
- get(key),通过 HashMap 找到 LRU 链表节点,因为根据LRU 原理,这个节点是最新访问的,所以要把节点插入到队头,然后返回缓存的值。
【https://zhuanlan.zhihu.com/p/34133067】
HashMap+双向链表手写LRU缓存算法/页面置换算法的更多相关文章
- 页面置换算法 - FIFO、LFU、LRU
缓存算法(页面置换算法)-FIFO. LFU. LRU 在前一篇文章中通过leetcode的一道题目了解了LRU算法的具体设计思路,下面继续来探讨一下另外两种常见的Cache算法:FIFO. LFU ...
- 操作系统-2-存储管理之LRU页面置换算法(LeetCode146)
LRU缓存机制 题目:运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制. 它应该支持以下操作: 获取数据 get 和 写入数据 put . 获取数据 get(key) - ...
- 操作系统笔记(六)页面置换算法 FIFO法 LRU最近最久未使用法 CLOCK法 二次机会法
前篇在此: 操作系统笔记(五) 虚拟内存,覆盖和交换技术 操作系统 笔记(三)计算机体系结构,地址空间.连续内存分配(四)非连续内存分配:分段,分页 内容不多,就不做index了. 功能:当缺页中断发 ...
- 操作系统页面置换算法(opt,lru,fifo,clock)实现
选择调出页面的算法就称为页面置换算法.好的页面置换算法应有较低的页面更换频率,也就是说,应将以后不会再访问或者以后较长时间内不会再访问的页面先调出. 常见的置换算法有以下四种(以下来自操作系统课本). ...
- 操作系统 页面置换算法LRU和FIFO
LRU(Least Recently Used)最少使用页面置换算法,顾名思义,就是替换掉最少使用的页面. FIFO(first in first out,先进先出)页面置换算法,这是的最早出现的置换 ...
- (待续)C#语言中的动态数组(ArrayList)模拟常用页面置换算法(FIFO、LRU、Optimal)
目录 00 简介 01 算法概述 02 公用方法与变量解释 03 先进先出置换算法(FIFO) 04 最近最久未使用(LRU)算法 05 最佳置换算法(OPT) 00 简介 页面置换算法主要是记录内存 ...
- 页面置换算法(最佳置换算法、FIFO置换算法、LRU置换算法、LFU置换算法)
页面置换产生的原因是:分页请求式存储管理(它是实现虚拟存储管理的方法之一,其中一个特性是多次性-->多次将页面换入或换出内存) 效果最好的页面置换算法:最佳置换算法 比较常用的页面置换算法有:F ...
- 页面置换算法-LRU(Least Recently Used)c++实现
最近最久未使用(LRU)置换算法 #include <iostream> #include <cstdio> #include <cstring> #include ...
- 页面置换算法之Clock算法
1.前言 缓冲池是数据库最终的概念,数据库可以将一部分数据页放在内存中形成缓冲池,当需要一个数据页时,首先检查内存中的缓冲池是否有这个页面,如果有则直接命中返回,没有则从磁盘中读取这一页,然后缓存到内 ...
随机推荐
- SQL on Hadoop中用到的主要技术——MPP vs Runtime Framework
转载声明 本文转载自盘点SQL on Hadoop中用到的主要技术,个人觉得该文章对于诸如Impala这样的MPP架构的SQL引擎和Runtime Framework架构的Hive/Spark SQL ...
- JAVA多线程提高十四: 面试题
前面针对多线程相关知识点进行了学习,那么我们来来看看常见的面试题: 1. 空中网面试题1 package com.kongzhongwang.interview; import java.util.c ...
- HDU 1846 Brave Game 巴什博奕
解题报告:Alice和Bob在做一个取石子游戏,有一堆n个石子,然后规定每个人每次最少要去1个石子,最多可以取m个石子,最后一次取完石子的人为胜. 巴什博奕,关键是找到必胜点和必败点,我们可以先列举出 ...
- Fetch API 了解 及对比ajax、axois
Fetch是什么 Fetch 是一个现代的概念, 等同于 XMLHttpRequest.它提供了许多与XMLHttpRequest相同的功能,但被设计成更具可扩展性和高效性.Fetch被很多浏览器所支 ...
- UNIX网络编程 第1章:简介和TCP/IP
1.1 按1.9节未尾的步骤找出你自己的网络拓扑的信息. 1.2 获取本书示例的源代码(见前言),编译并测试图1-5所示的TCP时间获取客户程序.运行这个程序若干次,每次以不同IP地址作为命令行参数. ...
- CSS 实现单边阴影
box-shadow: 0px -15px 10px -15px #111; 五个值分别为:x y blur spread color 将 spread 设置成 blur 的负值即可 这种只适用于 o ...
- qt中int与string的相互转换
我经常搞错这个问题,一直以为整形int b可以直接使用函数toString呢! 但是在qtCreator中在整形后面不管怎么按点(可以自动提示)他就是不给我提示,我就纳闷了这样居然不行 百度了之后才知 ...
- linux下使用indent整理代码(代码格式化)【转】
转自:https://blog.csdn.net/jiangjingui2011/article/details/7197069 常用的设置: indent -npro -kr -i8 -ts8 -s ...
- 关于app的cpu占用率想到的几个问题
1.top 命令获取的cpu是手机瞬间的cpu 2.dumpsys获取的是一段时间cpu的平均值?那么这段时间是指哪段,从哪开始到什么时候结束? 3.如果想测试app某操作下的cpu占用情况时候.应该 ...
- MySQL 5.7.17 Group Relication(组复制)搭建手册【转】
本博文介绍了Group Replication的两种工作模式的架构.并详细介绍了Single-Master Mode的部署过程,以及如何切换到Multi-Master Mode.当然,文末给出了Gro ...