通过spark-sql快速读取hive中的数据
1 配置并启动
1.1 创建并配置hive-site.xml
在运行Spark SQL CLI中需要使用到Hive Metastore,故需要在Spark中添加其uris。具体方法是将HIVE_CONF/hive-site.xml复制到SPARK_CONF目录下,然后在该配置文件中,添加hive.metastore.uris属性,具体如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop1:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
</configuration>

将mysql的jdbc驱动包拷贝给spark
将 $HIVE_HOME/lib/mysql-connector-java-5.1.12.jar copy或者软链到$SPARK_HOME/lib/
1.2 启动Hive Metastore
在使用Spark SQL CLI之前需要启动Hive Metastore(如果数据存放在HDFS文件系统,还需要启动Hadoop的HDFS),使用如下命令可以使Hive Metastore启动后运行在后台,可以通过jobs查询:
$nohup hive --service metastore > metastore.log 2>&1 &

1.3 启动Spark集群和Spark SQL CLI
通过如下命令启动Spark集群和Spark SQL CLI:
$cd /app/hadoop/spark-1.1.0 $sbin/start-all.sh $bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g
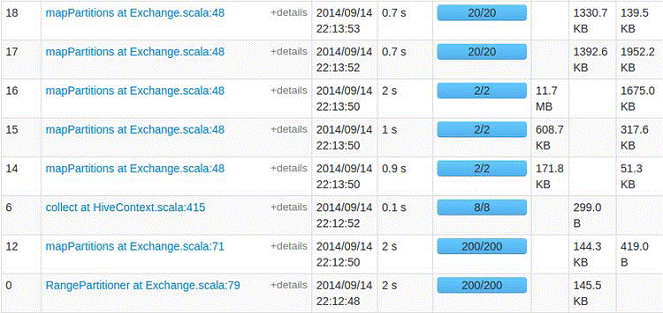
在集群监控页面可以看到启动了SparkSQL应用程序:

这时就可以使用HQL语句对Hive数据进行查询,另外可以使用COMMAND,如使用set进行设置参数:默认情况下,SparkSQL Shuffle的时候是200个partition,可以使用如下命令修改该参数:
SET spark.sql.shuffle.partitions=20;
运行同一个查询语句,参数改变后,Task(partition)的数量就由200变成了20。
通过spark-sql快速读取hive中的数据的更多相关文章
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- SQL Server 读取CSV中的数据
测试: Script: create table #Test ( Name ), Age int, T ) ) BULK INSERT #Test From 'I:\AAA.csv' with( fi ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- 使用Hive读取ElasticSearch中的数据
本文将介绍如何通过Hive来读取ElasticSearch中的数据,然后我们可以像操作其他正常Hive表一样,使用Hive来直接操作ElasticSearch中的数据,将极大的方便开发人员.本文使用的 ...
- Spark读取Hbase中的数据
大家可能都知道很熟悉Spark的两种常见的数据读取方式(存放到RDD中):(1).调用parallelize函数直接从集合中获取数据,并存入RDD中:Java版本如下: JavaRDD<Inte ...
- sql 读取excel中的数据
select 列名 as 字段名 from openBowSet('MSDASQL.1','driver=Microsoft Excel Driver(*.xls);dbq=文件存放地址','sele ...
- Spark SQL - 对大规模的结构化数据进行批处理和流式处理
Spark SQL - 对大规模的结构化数据进行批处理和流式处理 大体翻译自:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/con ...
- Hive中的数据倾斜
Hive中的数据倾斜 hive 1. 什么是数据倾斜 mapreduce中,相同key的value都给一个reduce,如果个别key的数据过多,而其他key的较少,就会出现数据倾斜.通俗的说,就是我 ...
- 编写SqlHelper使用,在将ExecuteReader方法封装进而读取数据库中的数据时会产生Additional information: 阅读器关闭时尝试调用 Read 无效问题,解决方法与解释
在自学杨中科老师的视频教学时,拓展编写SqlHelper使用,在将ExecuteReader方法封装进而读取数据库中的数据时 会产生Additional information: 阅读器关闭时尝试调用 ...
随机推荐
- ABP 基础设施层——集成 NHibernate
本文翻译自ABP的官方教程<NHibernate Integration>,地址为:http://aspnetboilerplate.com/Pages/Documents/NHibern ...
- spring的事务传播属性
一.Propagation (事务的传播属性) Propagation : key属性确定代理应该给哪个方法增加事务行为.这样的属性最重要的部份是传播行为.有以下选项可供使用:PROPAGATION_ ...
- 安装webpack常见错误之一
我安装webpack时,出现如下错误: C:\Users\admin> npm install webpack -gnpm WARN checkPermissions Missing write ...
- easyui-layout系列之布局(1)
1.Layout布局 通过 $.fn.layout.defaults 重写默认的 defaults. 布局(layout)是有五个区域(北区 north.南区 south.东区 east.西区 wes ...
- 在QT中用git做版本管理时遇到的一些问题
1. 安装git sudo apt-get install git 2. 安装gitk sudo apt-get install gitk 要提交代码,点击 工具->git->local ...
- tomcat JNDI Resource 配置
最近公司的项目慢慢开始向Maven项目迁移, 部分配置文件公共组也帮我们做了些改动,其中在spring的applicationContext.xml中看到了数据连接bean存在两个,一个是jndi 一 ...
- Struts2中使用OGNL表达式语言访问静态方法和静态属性
1.一定要在struts.xml配置文件中配置允许使用OGNL访问静态方法,否则不能使用OGNL访问静态方法 2.<s:property value="@com.gk.StaticTe ...
- 使用.net core读取Json文件配置
1.使用vs2017创建一个应用台程序 2.使用程序包管理器控制台执行命令 Install-Package Microsoft.AspNetCore -Version 2.0.1 3.创建一个json ...
- Android启动过程介绍
开机过程大致可以分为以下三个阶段 OS级别 由bootloader载入linux kernel后,kernel开始初始化, 并载入built-in的驱动程序.Kernel完成开机后,载入init pr ...
- nodeJS搭建一个简单的(代理)web服务器
前端获取数据时经常遇见跨域问题,以前一直用nginx做反向代理.最近在用vuejs,发现webpack-dev-server的代理简单好用.于是仿照写了一个简单的web服务器,用于非webpack的项 ...