Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统。 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
注意:Kafka并没有遵循JMS规范,它只提供了发布和订阅通讯方式!!!!!
kafka中文官网:http://kafka.apachecn.org/quickstart.html
Kafka用在日志里面比较多 大数据里面的
MQ的思想: 解耦合 流量削峰 异步通信
kafka优点:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作,我之前在课题里用到Spark Streaming 作为消费者过滤数据。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka依赖Zookeeper,kafka把集群的节点信息 全部存放在Zookeeper节点!!!!!
应用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr或者Spark Streaming等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
关键名词解释:
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。 broker就是节点,单机的kafka服务器
Topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发,kafka服务器存放 主题。kafka集群,相当于把topic进行拆分,拆分到不同的分区进行存放。类似于数据库存放数据量比较大的情况下,表进行拆分。查询时候进行分表查询。
massage: Kafka中最基本的传递对象。
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列,就是分区的概念,相当于把topic存放到不同的物理机器上存储起来。topic消息进行拆分,均摊存放到不同的
集群中的kafka服务器上。 每个partition其实是有顺序的。
Segment:partition物理上由多个segment组成,每个Segment存着message信息
Producer : 生产者,生产message发送到topic
Consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费
Consumer Group:消费者组,一个Consumer Group包含多个consumer。在同一个组可以收到消息
Offset:偏移量,理解为消息partition中的索引即可。 消息在partition的索引的位置
需要理解存储策略:
1)kafka以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,有多个segment组成。
2)每个segment中存储多条消息(见下图),消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3)每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4)发布者发到某个topic的消息会被均匀的分布到多个partition上(或根据用户指定的路由规则进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
生产者发送消息原理:

Kafka高可用集群原理:
kafka 是topic为主的,kafka必须集群,核心就是集群,才能体现分区的优势!
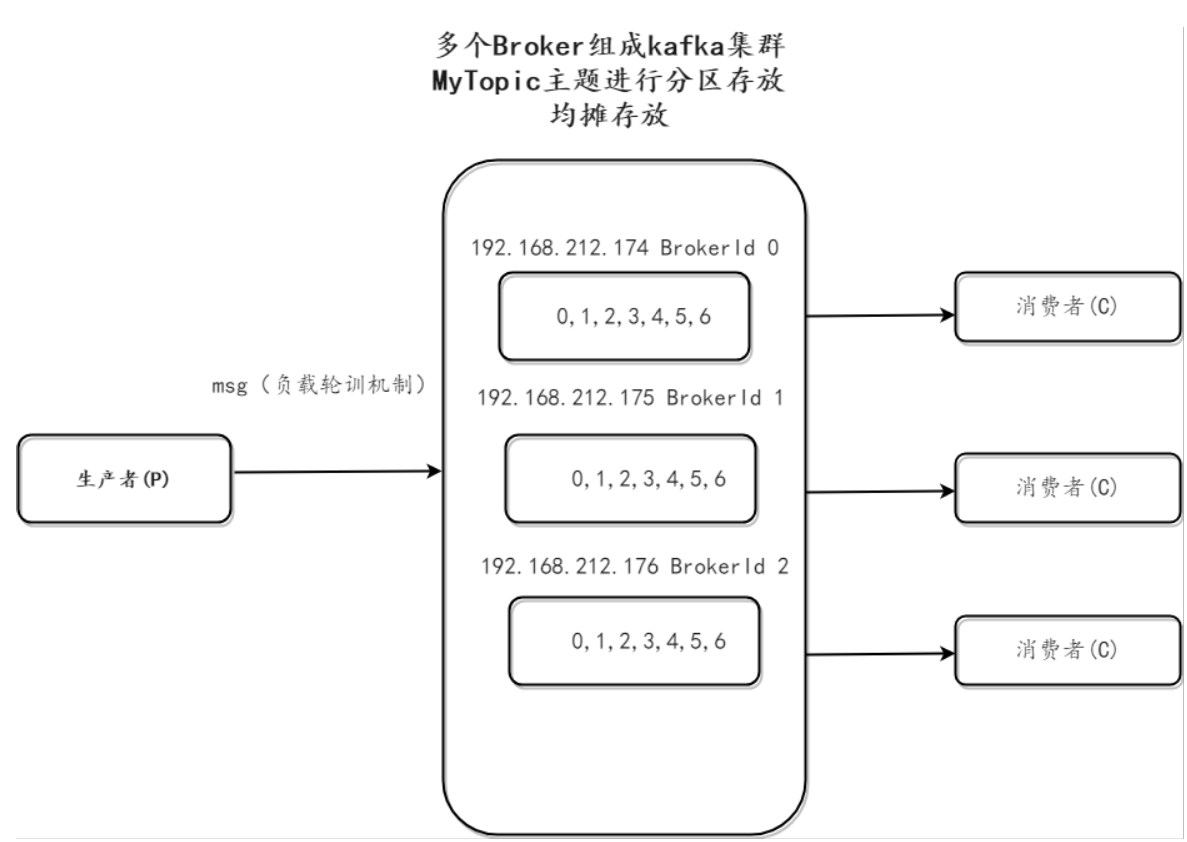
集群环境下 生产者投递消息 到哪个Broker?
(Tomcat 通过Nginx 集合起来的思想深入人心)
集群的目的就是分担单台的压力,kafaka采用了 负载轮训的机制
数据库里面 单表 有1亿条数据 查询很慢的 。所以分表,比如按照月份进行分,或者根据其他的业务来进行分。
下图三个Broke topic进行分区存放,在创建topic时候,轮训去指定分区。BrokerId区分之
0,1,2,34,5,6为offset 每个分区中的offset是独立的,互不影响的
三个broker,有三个消费者是比较合理的~
Zookeeper 节点专门存放topic 信息。 kafka 的broker的信息存放在zk节点
Kafka高可用环境搭建的更多相关文章
- haproxy + rabbitmq + keepalived的高可用环境搭建
一.rabbitmq的搭建:参考rabbimq的安装及集群设置 二.安装和配置haproxy 1.安装haproxyyum install haproxy 2.安装rsysloga. 检查rsyslo ...
- hadoop学习笔记(八):hadoop2.x的高可用环境搭建
本文原创,转载请注明作者及原文链接 高可用集群的搭建: 几个集群的启动顺序问题: 1.先启动zookeeper --->zkServer.sh start 2.启动journalNodes集群 ...
- 大数据学习(07)——Hadoop3.3高可用环境搭建
前面用了五篇文章来介绍Hadoop的相关模块,理论学完还得操作一把才能加深理解.这一篇我会花相当长的时间从环境搭建开始,到怎么在使用Hadoop,逐步介绍Hadoop的使用. 本篇分这么几段内容: 规 ...
- hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者 所用到的命令的总结: yarn:启动start-yarn.sh 停止stop-yarn.sh zk :zkServer.start ;:zkServer. ...
- Eureka高可用环境搭建
1.创建govern-center 子工程 包结构:com.dehigher.govern.center 2.pom文件 (1)父工程pom,用于依赖版本管理 <dependencyManage ...
- Redis Cluster 集群三主三从高可用环境搭建
前言 Redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用. Window环境下载地址:https://github.com/tporadowski/redis ...
- KEEPALIVED+LVS+MYCAT实现MYSQL高可用环境搭建
一.安装keepalived和ipvsadm 注意:ipvsadm并不是lvs,它只是lvs的配置工具. 为了方便起见,在这里我们使用yum的安装方式 分别在10.18.1.140和10.18.1.1 ...
- 阶段5 3.微服务项目【学成在线】_day09 课程预览 Eureka Feign_03-Eureka注册中心-搭建Eureka高可用环境
1.3.2.2 高可用环境搭建 Eureka Server 高可用环境需要部署两个Eureka server,它们互相向对方注册.如果在本机启动两个Eureka需要 注意两个Eureka Server ...
- 使用KeepAlived搭建MySQL高可用环境
使用KeepAlived搭建MySQL的高可用环境.首先搭建MySQL的主从复制在Master开启binlog,创建复制帐号,然后在Slave输入命令 2016年7月25日 配置安装技巧: ...
随机推荐
- day15数据类型
一.浮点数 之前讲过的,有序 : 列表 元组 字符串 数字类 :int flost complex bool 散列累 :集合和字典 浮点数:--包含所有小数 和复数 复数:a +bj 实部和虚部 ...
- 一套一般般的前端框架 layui
http://www.layui.com/doc/
- android Service 保持不被杀死
Android开发的过程中,每次调用startService(Intent)的时候,都会调用该Service对象的onStartCommand(Intent,int,int)方法,然后在onStart ...
- nginx 在浏览器端保持cookie 一致
一般来说,我们在java中都通过如下代码进行用户登录后的服务端注册,并且在用户下次请求时无需再登陆一遍,这就是Servlet的Session.使用了这种Session策略,那么Web容器比如tomca ...
- centos6.4下安装mysql5.7.18
1.安装前工作 在安装前需要确定现在这个系统有没有 mysql,如果有那么必须卸载(在 centos7 自带的是 mariaDb 数据库,所以第一步是卸载数据库). 卸载系统自带的Mariadb: 查 ...
- hoj 2715 (费用流 拆点)
http://acm.hit.edu.cn/hoj/problem/view?id=2715 将每个格子 i 拆成两个点 i’, i’’并加边(i’, i’’, 1, -Vi), (i’, i’’, ...
- Strange Optimization(扩展欧几里得)
Strange Optimization Accepted : 67 Submit : 289 Time Limit : 1000 MS Memory Limit : 65536 KB Str ...
- EasyNVR摄像机无插件直播安装使用错误原因解析
背景需求 EasyNVR(www.easynvr.com)摄像机无插件直播流媒体服务器对于互联网的视频直播还是有着一定的贡献的.为了方便用户的体验使用,我们也在互联网上放置了对应的试用版本,并且也会随 ...
- ActiveMQ5.10.2版本配置JMX
ActiveMQ的特性之一是很好的支持JMX.通过JMX MBeans可以很方便的监听和控制ActiveMQ的broker. 鉴于官方网站提供的JMX特性说明对于远程访问的配置流程不是很完整,笔者在实 ...
- vue禁止复制的方式
普通网页禁止复制的功能这里不再叙述,自行学习 https://blog.csdn.net/qq_32963841/article/details/84656752 这里简单写一下vue中怎么禁止使用复 ...