hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者
所用到的命令的总结:
yarn:启动start-yarn.sh 停止stop-yarn.sh
zk :zkServer.start ;:zkServer.stop;
启动hdfs : start-dfs.sh 停止:stop-dfs.sh
当然可以需要在zk集群已经跑起来的情况下在头结点上用start-all.sh命令去启动整个集群,
这个命令会启动的进程如下所示
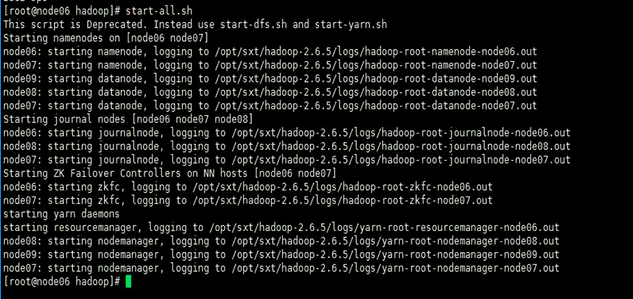
之后还需要两个命令去启动两个yarn的resource manager进程 :yarn-daemon.sh start resourcemanager

1、基本配置
现结点的配置情况

1、单节点的yarn管理的配置
需要配置mapread-site.xml
Configure parameters as follows:
etc/hadoop/mapred-site.xml:
#mapread-site.xml <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml:
#和yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2、配置HA高可用中的yarn管理
需要配置的是yarn-site.xml文件
Here is the sample of minimal setup for RM failover.
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:,node03:,node04:</value>
</property>
3、具体的自己在搭建的过程中将那几个结点当做resourcemanager所在的结点,则需要将这两个结点互相的分发秘钥,实现互相的免秘钥登录
node03
[root@node03 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
自己实现对自己的免秘钥登录
[root@node03 ~]# cd .ssh/
[root@node03 .ssh]# ll
总用量
-rw-r--r-- root root 9月 : authorized_keys
-rw------- root root 10月 : id_dsa
-rw-r--r-- root root 10月 : id_dsa.pub
-rw-r--r-- root root 9月 : known_hosts
-rw-r--r-- root root 9月 : node01.pub
[root@node03 .ssh]# cat id_dsa.pub >> authorized_keys
在node03将秘钥发给node04结点并改名
[root@node03 .ssh]# scp id_dsa.pub node04:`pwd`/node03.pub
之后在node中执行追加命令
[root@node04 .ssh]# cat node03.pub >> authorized_keys
node04进行同样的和node03一样的命令且将自己的秘钥文件发给Node03并在03上将node04的秘钥文件追加到自己的验证文件中
4、启动集群步骤
概括:
启动:node01: zookeeper
hdfs (注意,有一个脚本不要用,start-all)start-dfs.sh
如果nn 和 nn2没有启动,需要在node06,node07分别手动启动:
hadoop-daemon.sh start namenode
start-yarn.sh (启动nodemanager)
在03,04节点分别执行脚本: yarn-daemon.sh start resourcemanager UI访问: ip: 停止:
node01: stop-dfs.sh
node01: stop-yarn.sh (停止nodemanager)
node03,node04: yarn-daemon.sh stop resourcemanager (停止resourcemanager)

先启动zk集群;command: zkServer.sh start
因为mr是在hdfs的基础是哪个的,所以在主结点上先启动hdfs 命令:start-dfs.sh
hdfs集群启动:

在主结点上启动Node Manager,这个进程会分别的在DataNode的结点上启动
[root@node01 hadoop]# start-yarn.sh

注意到这里并没有启动,需要到两个配置resourcemanager的结点去分别的去启动它
[root@node03 .ssh]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/sxt/hadoop-2.6./logs/yarn-root-resourcemanager-node03.out
[root@node04 .ssh]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/sxt/hadoop-2.6./logs/yarn-root-resourcemanager-node04.out
之后可以通过ss -nal命令查看端口 8088是yarn和浏览器的默认通信端口,
而3888是zk集群选举机制所用的端口,2888是zk集群内部通信所用的端口,2181是服务器和客户单通信的端口
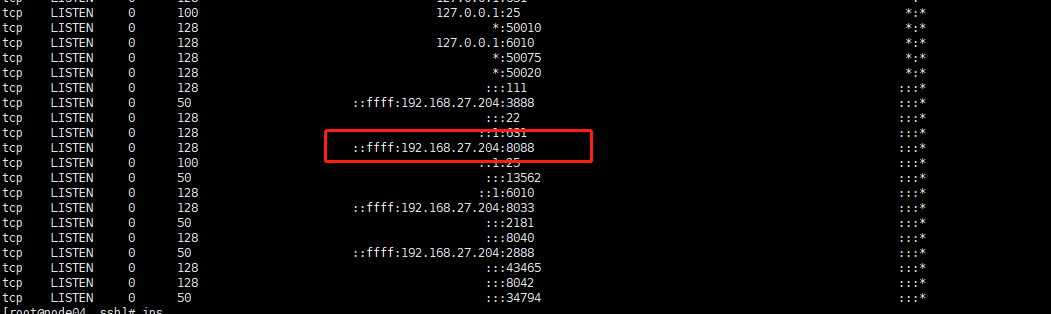
浏览器访问yarn
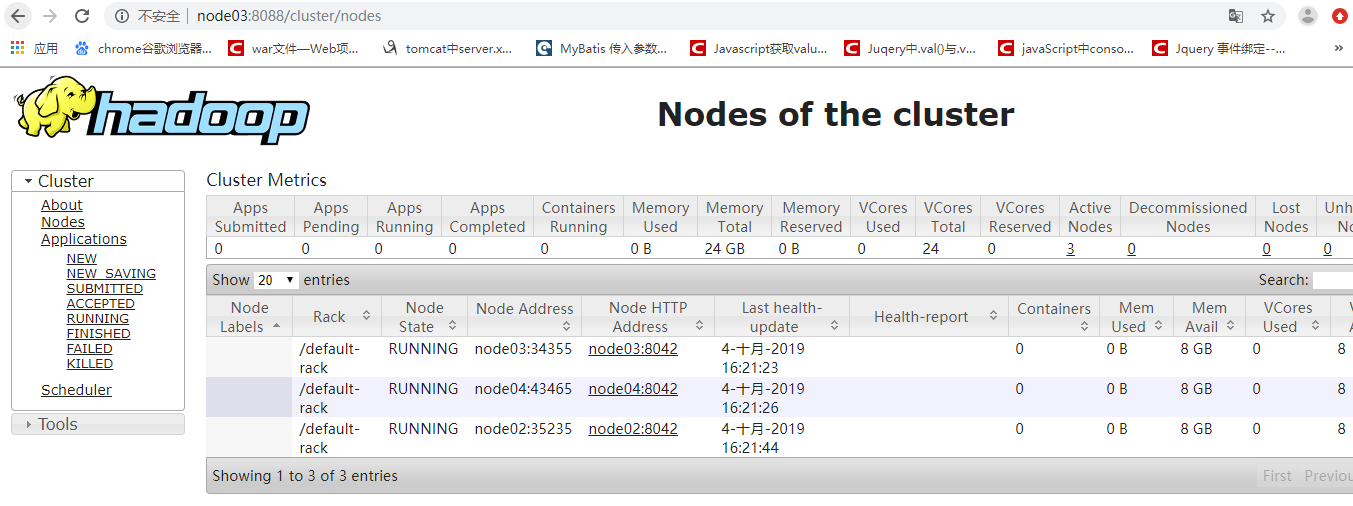
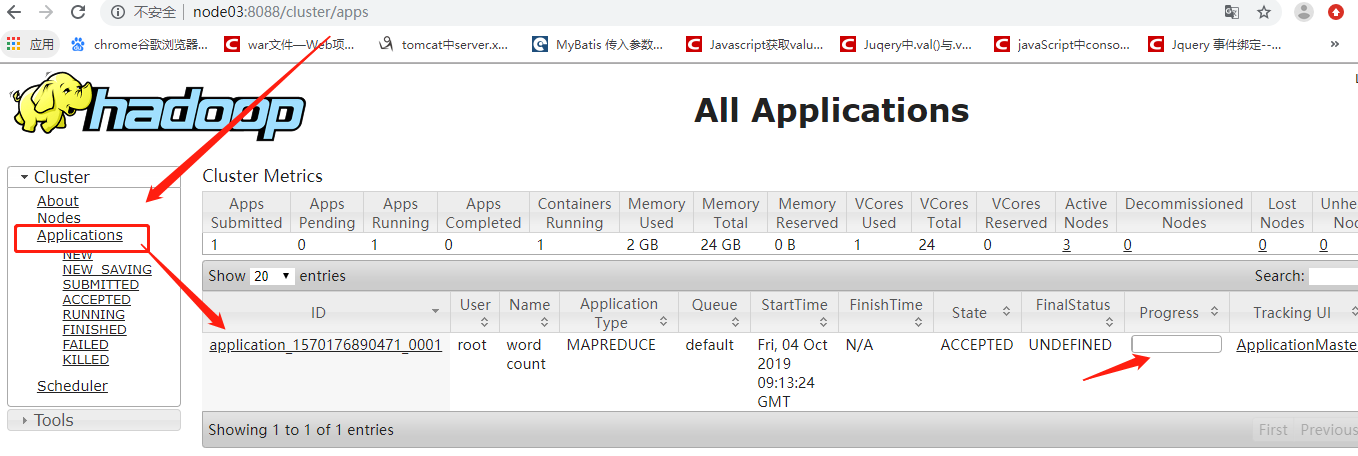
2、 运用它的计算功能:
先自己创建以及上传一个文件
[root@node01 hadoop-2.6.]# for i in `seq `;do echo "hello sxt $i" >> test.txt;done
[root@node01 software]# hdfs dfs -D dfs.blocksize= -put test.txt
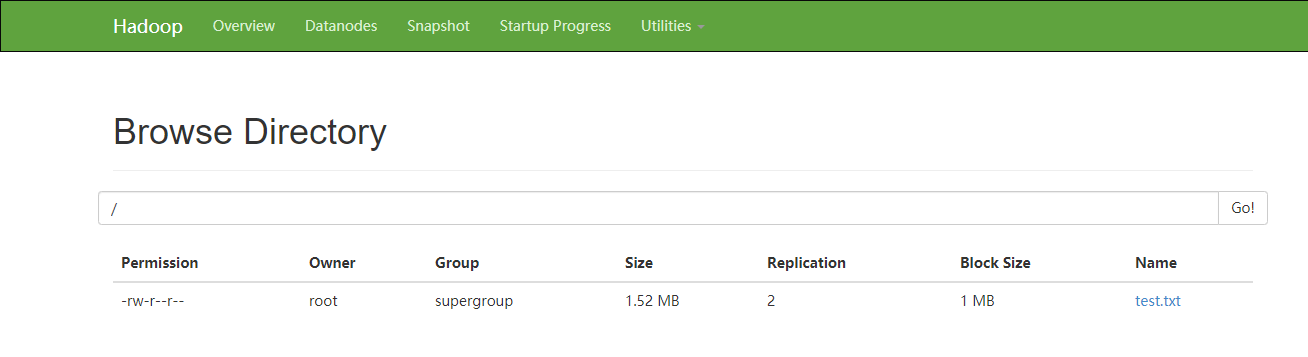
具体的运用计算功能的过程
找到自己的hadoop安装路径
cd /opt/sxt/hadoop-2.6./share/hadoop/mapreduce
对test.txt进行单词统计
[root@node01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6..jar wordcount /test.txt /wordcount
可以看滚动条的计算进度过程
后台的linux命令行中的执行过程
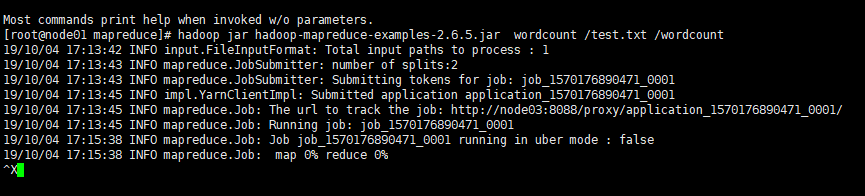
先执行map 作业在执行 reduce作业
浏览器端观察计算已经完成
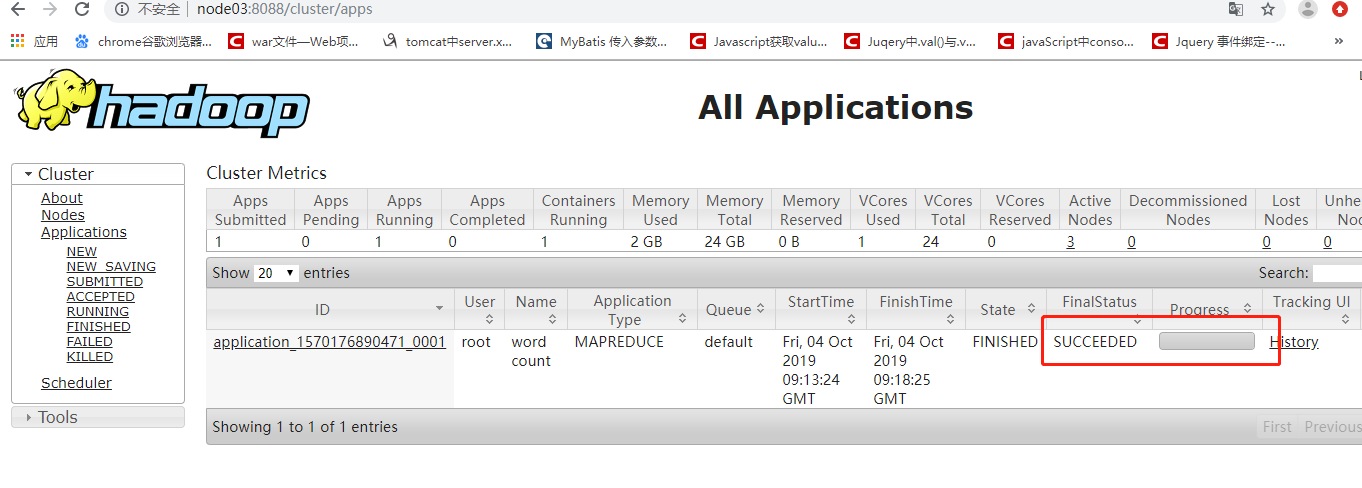
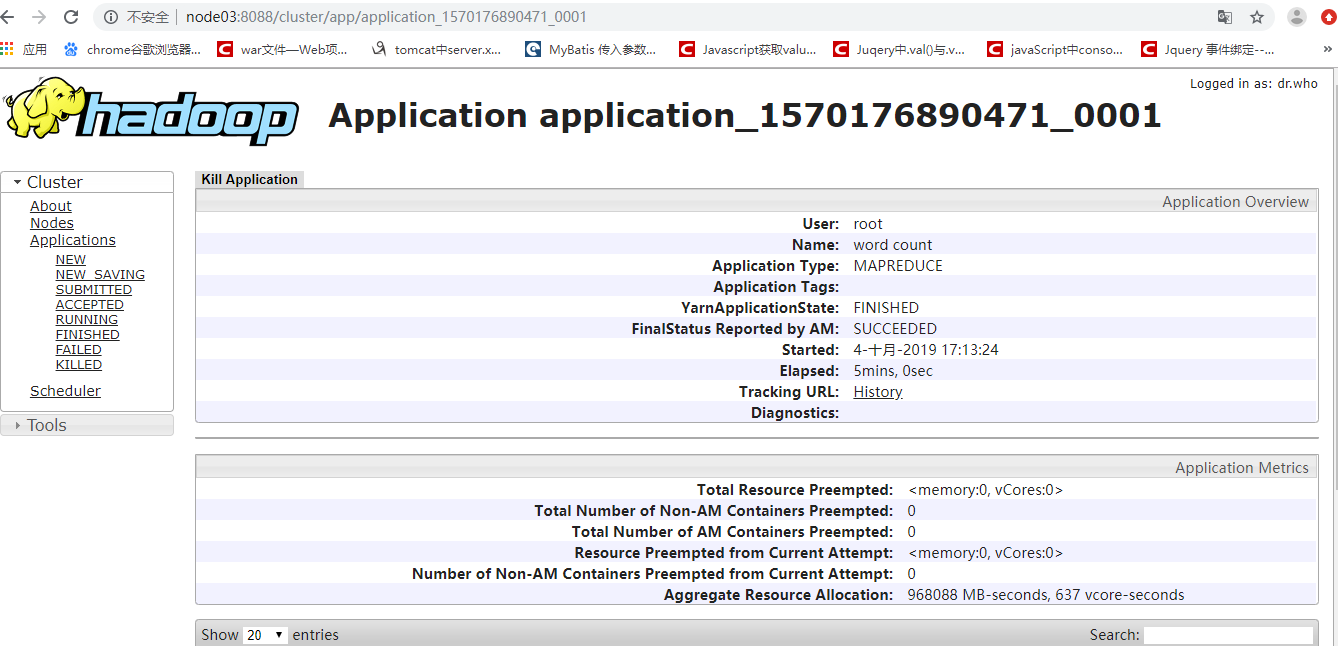
通过命令行看完成的现象
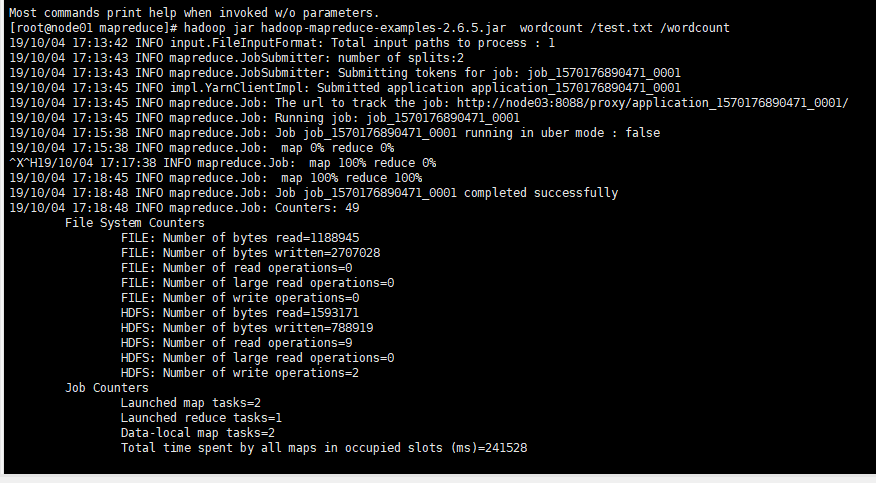
这种状态代表正常的执行完毕了计算,没有出现语法问题,但是这并不代表计算的结果是正确的
等待之心完毕之后,可以在命令行下通过命令
查看hdfs中的文件
hdfs dfs -cat /文件 查看统计的结果
hdfs dfs -cat /wordcount/part-r-
结果

完成最基本的mr的计算的功能!!
hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用的更多相关文章
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- Java web与web gis学习笔记(一)——Tomcat环境搭建
系列链接: Java web与web gis学习笔记(一)--Tomcat环境搭建 Java web与web gis学习笔记(二)--百度地图API调用 JavaWeb和WebGIS学习笔记(三)-- ...
- hadoop学习(三)----hadoop2.x完全分布式环境搭建
今天我们来完成hadoop2.x的完全分布式环境搭建,话说学习本来是一件很快乐的事情,可是一到了搭环境就怎么都让人快乐不起来啊,搭环境的时间比学习的时间还多.都是泪.话不多说,走起. 1 准备工作 开 ...
- hadoop学习笔记(八):hadoop2.x的高可用环境搭建
本文原创,转载请注明作者及原文链接 高可用集群的搭建: 几个集群的启动顺序问题: 1.先启动zookeeper --->zkServer.sh start 2.启动journalNodes集群 ...
- Kafka学习笔记-如何保证高可用
一.术语 1.1 Broker Kafka 集群包含一个或多个服务器,服务器节点称为broker. broker存储topic的数据. 如果某topic有N个partition,集群有N个broker ...
- 大数据学习(07)——Hadoop3.3高可用环境搭建
前面用了五篇文章来介绍Hadoop的相关模块,理论学完还得操作一把才能加深理解.这一篇我会花相当长的时间从环境搭建开始,到怎么在使用Hadoop,逐步介绍Hadoop的使用. 本篇分这么几段内容: 规 ...
- Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于2010年贡献给 ...
- haproxy + rabbitmq + keepalived的高可用环境搭建
一.rabbitmq的搭建:参考rabbimq的安装及集群设置 二.安装和配置haproxy 1.安装haproxyyum install haproxy 2.安装rsysloga. 检查rsyslo ...
- Eureka高可用环境搭建
1.创建govern-center 子工程 包结构:com.dehigher.govern.center 2.pom文件 (1)父工程pom,用于依赖版本管理 <dependencyManage ...
随机推荐
- 支付宝网站支付接口配置 RSA 公钥 私钥
个人博客 地址:http://www.wenhaofan.com/article/20190419143333 下载签名工具 访问:https://docs.open.alipay.com/291/1 ...
- BZOJ3172&&lg3966 TJOI单词(广义后缀自动机)
BZOJ3172&&lg3966 TJOI单词(广义后缀自动机) 题面 自己找去 HINT 给出多个文本串,让你查找每个文本串一共出现了多少次,广义后缀自动机建出parent tree ...
- 基于Python接口自动化测试框架+数据与代码分离(进阶篇)附源码
引言 在上一篇<基于Python接口自动化测试框架(初级篇)附源码>讲过了接口自动化测试框架的搭建,最核心的模块功能就是测试数据库初始化,再来看看之前的框架结构: 可以看出testcase ...
- NumPy迭代数组
numpy.nditer是NumPy的一个迭代器对象,提供能够灵活的访问一个或者多个属猪元素的方式. # 迭代 z=np.arange(6).reshape(3,2) for x in np.ndit ...
- Log4net实用说明
Log4net实用说明 Appender Filter Layout Logger ObjectRender Repository PatterLayout格式化字符表 配置文件说明 Appender ...
- 最大流算法之Ford-Fulkerson算法与Edmonds–Karp算法
引子 曾经很多次看过最大流的模板,基础概念什么的也看了很多遍.也曾经用过强者同学的板子,然而却一直不会网络流.虽然曾经尝试过写,然而即使最简单的一种算法也没有写成功过,然后对着强者大神的代码一点一点的 ...
- 获取properties文件的内容
获取properties文件的内容 public void test() throws Exception{ String resource = "application.propertie ...
- unicode 地址
unicode 地址
- 2020牛客寒假算法基础集训营1 F-maki和tree
链接:https://ac.nowcoder.com/acm/contest/3002/F来源:牛客网 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 262144K,其他语言5242 ...
- eclipse中配置maven环境
一.配置setting.xml文件 1.首先将下载好的maven打开,打开文件夹,首先就需要对maven安装目录下有个config文件夹,在文件夹下有settings.xml文件.settings里面 ...