scrapy详细数据流走向(个人总结)
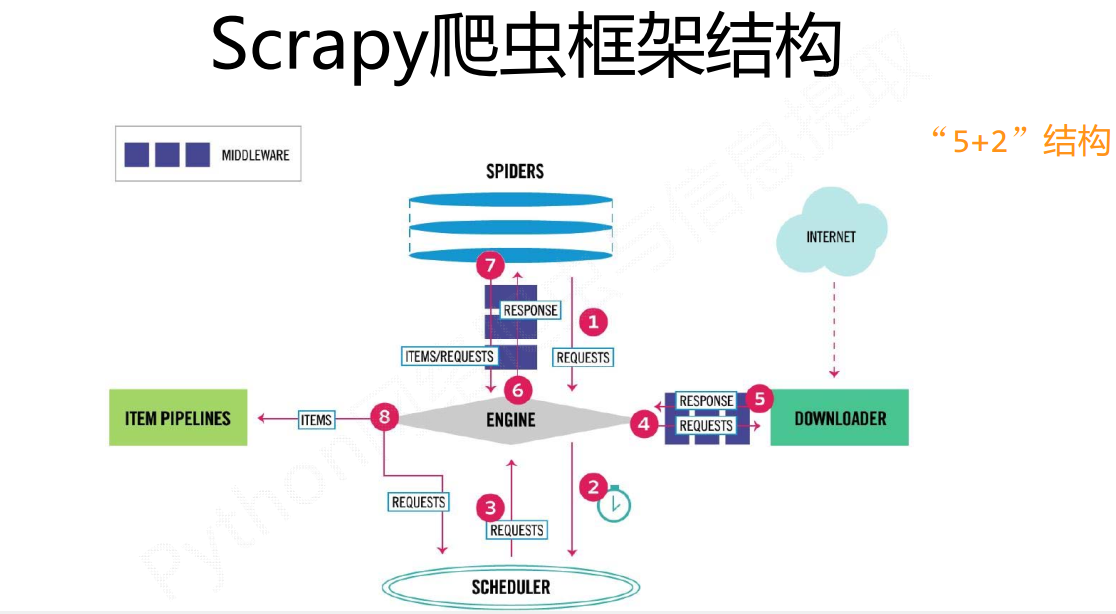
直接从数据流的角度来说比较容易理解:
·1、Spider创建一个初识url请求,把这个请求通过Engine转给Scheduler调度模块。然后Scheduler向Engine提供一个请求(这个请求是一个真实的url请求)
疑问点一:为什么Engine把请求发给Scheduler模块,然后又从Scheduler模块里面取出来,这不是多此一举么,这个Scheduler模块有作用么?
按照我的理解,scrapy把各个组件模块化,就是为了更加方便的配置,当然你把所有模块都写在一起,功能同样可以实现,只不过这就失去了这个框架的价值了,Scheduler就是为了存取请求,而Spider就是解析出新的请求和数据item。
疑问点二:为什么说Scheduler存的是真实的url请求
Spider里面的url不一定是我们需要的url,需要经过解析,生成我们所需要的真实url,然后通过Engine发送给Scheduler
2、第一步Engine已经得到了真实的url地址,然后Engine把这个请求request发送给Downloader模块
tips:我们主要到Engine发送请求给Downloader模块前,需要进过DownloaderMiddleware中间件,实际上这里可以对请求做一些修改,也就是添加User-Agent之类的参数,如果用过requests第三方包应该容易理解
3、Downloader模块把网页下载完成后会把结果返回给Engine
tips:这个过程同样会经过DownloaderMiddleware,所以很容易理解,我们可以在这里修改response相关信息
4、Engine得到数据之后,它会把数据发送给Spider进行解析得到item(数据)或者是request(新的请求)
tips:比如我们本来要获取的是图片信息,在得到的response中发现不止有图片信息(item),还有其他的连接(新的request)
5、Spider解析得到的item和request会有两种走向
a:如果是item,也就是已经得到了数据,那么就通过Engine把item发送到Itempipeline进行处理,这里主要是进行数据的清洗、查重、保存等操作。
b:如果生成的是request,照着之前的,通过Engine把真实请求request发送给Scheduler,然后Engine从Scheduler拿request,发给给Downloader下载,Downloader下载完通过Engine发送给Spider。。如此往复,直到没有新的request请求
有时候看到网上的教程那么长会觉得难,不想去学,真正去学的时候会发现,其实也就那样。好了,关于scrapy的数据流就到这。
scrapy详细数据流走向(个人总结)的更多相关文章
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- 97、爬虫框架scrapy
本篇导航: 介绍与安装 命令行工具 项目结构以及爬虫应用简介 Spiders 其它介绍 爬取亚马逊商品信息 一.介绍与安装 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, ...
- 爬虫框架之Scrapy
一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowloader Middeware ...
- Scrapy学习篇(一)之框架
概览 在具体的学习scrapy之前,我们先对scrapy的架构做一个简单的了解,之后所有的内容都是基于此架构实现的,在初学阶段只需要简单的了解即可,之后的学习中,你会对此架构有更深的理解.下面是scr ...
- 爬虫 之 scrapy框架
浏览目录 介绍 安装 项目结构及爬虫应用简介 常用命令行工具 Spiders爬虫 Selectors选择器 Item Pipeline 项目管道 Downloader Middleware下载中间件 ...
- 爬虫框架scrapy的基本内容
Scrapy介绍 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以帮助用户简单快速的部署一个专业的网络爬虫.如果说前面我们写的定制bs4爬虫是”手动挡“,那Scrapy就相当 ...
- 爬虫之scrapy工作流程
Scrapy是什么? scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容.Scrapy 使用了 Twisted['twɪstɪd] ...
- 九、爬虫框架之Scrapy
爬虫框架之Scrapy 一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowload ...
- 第六篇:Scrapy框架
爬虫框架之Scrapy 一.介绍 二.安装 三.命令行工具 四.项目结构以及爬虫应用简介 五.Spiders 六.Selectors 七.Items 八.Item Pipelin 九. Dowload ...
随机推荐
- something about Parameter Estimation (参数估计)
点估计 Point Estimation 最大似然估计(Maximum Likelihood Estimate —— MLE):视θ为固定的参数,假设存在一个最佳的参数(或参数的真实值是存在的),目的 ...
- 2017 Multi-University Training Contest - Team 2 Puzzle
题目大意: 给定n, m, p.然后按照一个规则往n*m的方格里填数,最后一个方格是空格,然后玩拼图游戏,问能否复原 规则是:把1~n*m-1的排列中的第1,p+1,2*p+1.....个数依次取出来 ...
- [Leetcode] Balanced binary tree平衡二叉树
Given a binary tree, determine if it is height-balanced. For this problem, a height-balanced binary ...
- BZOJ3533 [Sdoi2014]向量集 【线段树 + 凸包 + 三分】
题目链接 BZOJ3533 题解 我们设询问的向量为\((x_0,y_0)\),参与乘积的向量为\((x,y)\) 则有 \[ \begin{aligned} ans &= x_0x + y_ ...
- 【NOIP 模拟赛】区间第K大(kth) 乱搞
biubiu~~~ 这道题就是预处理,我们就是枚举每一个数,找到左边比他大的数的个数以及其对应的区间,右边也如此,我们把左边的和右边的相乘就得到了我们的答案,我们发现这是O(n^3)的,但是实际证明他 ...
- Linux产生背景
By francis_hao Oct 26,2016 很久很久以前,大概在1965年左右,由贝尔实验室(Bell).麻省理工学院(MIT)及通用电气公司(GE)共同发起了一个叫做Multics的项目, ...
- 解决IIS设置多个工作进程中Session失效的问题
利用StateServer实现Session共享 session保存在专门的StateServer中,该种方式,性能损失比sql略好.比inproc据说有10%-15%的性能损失.怎么使用StateS ...
- codeforces 1060 D
https://codeforces.com/contest/1060/problem/D 题意:你可以用1个及以上的圆桌,给n个人排座位,每个人左边需要有Li个空凳子,右边需要有Ri个空凳子,问你最 ...
- 移动端list布局,左边固定,右边自适应
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- Java中中英文对齐输出问题,以及Java中的格式化输出
一 中英文对齐输出问题 问题,要求控制台输出如下: abcefg def 森林 阿狗 其实就是要求对齐输出,各种查找java的格式化输出,然后发现只要一个简单的“\t”就可以实现. 代码如下: Sy ...