爬虫之scrapy工作流程
Scrapy是什么?
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
异步与非阻塞的区别:异步:调用在发出之后,这个调用就直接返回,不管有无结果。
非阻塞:关注的是程序在等待调用结果(消息,返回值)时的状态,指在不能立刻得到结果之前,该调用不会阻塞当前线程。

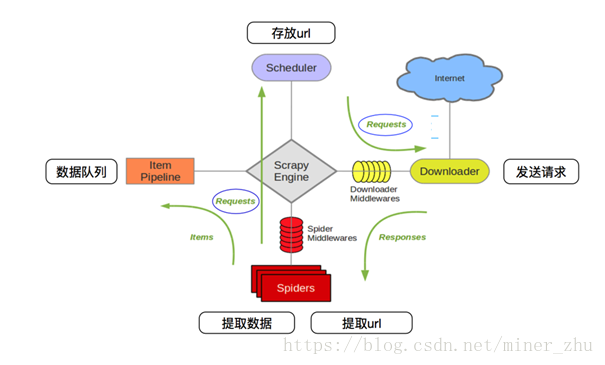
scrapy详细工作流程:
1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
5.提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
Scrapy主要包括了以下组件:
- 引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
爬虫之scrapy工作流程的更多相关文章
- scrapy 工作流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为: 引擎打开一个域名,蜘蛛处理这个域名,然后获取第一个待爬取的URL. 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求 ...
- scrapy工作流程
整个scrapy流程,我们可以用去超市取货的过程来比喻一下 两个采购员小王和小李开着采购车,来到一个大型商场采购公司月饼.到了商场之后,小李(spider)来到商场前台,找到服务台小花(引擎)并对她说 ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- Linux企业级项目实践之网络爬虫(2)——网络爬虫的结构与工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分.爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份. 一个通用的网络爬虫的框架如图所示:
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
随机推荐
- php:封装了个时间函数,返回类似“1分钟前发布”,“5小时前发布”,“3年前发布”
处理和时间有关的时候,像发布问题等通常不会用date格式的时间,而是用类似"3分钟前发布"等格式,下面封装的php函数就可以使用: 注意:当有用到strtotime()函数的记得加 ...
- jquery扩展方法详解
http://www.jb51.net/article/51079.htm https://www.cnblogs.com/xuxiuyu/p/5989743.html ---更详细
- (转)通过MySQL复制线程SQL_Thread加快增量恢复binlog
数据回档常常是使用全量备份+binlog增量实现的.而数据量很大的情况下,增量恢复binlog一直是一个苦恼的问题,因为恢复binlog速度十分慢,并且容易出错. 恢复binlog文件一般有两种方法: ...
- 详解Java构造方法为什么不能覆盖,我的钻牛角尖病又犯了....
一 看Think in Java,遇到个程序 class Egg2 { protected class Yolk { public Yolk() { System.out.println(" ...
- Oracle中文乱码,字符集问题处理
1. 右键计算机,选择属性,增加环境变量 NLS_LANG:SIMPLIFIED CHINESE_CHINA.ZHS16GBK 2.进入注册表,依次单击HKEY_LOCAL_MACHINE --> ...
- ECharts3.0介绍、入门
ECharts 特性介绍 ECharts,一个纯 Javascript 的图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,S ...
- /pentest/enumeration/irpas/itrace
/pentest/enumeration/irpas/itrace 追踪防火墙内部路由
- freebsd新添加磁盘
1.添加硬盘 2.查看现在的硬盘 3.执行sysinstall命令 4. 5. 6.按下enter键 7.A,C,Q 8. 9. 10.C,Q 11.newfs /dev/ad0 12.cd / &a ...
- 修复使用<code>XmlDocument</code>加载含有DOCTYPE的Xml时,加载后增加“[]”字符的错误
C# LINQ TO XML - Remove “[]” characters from the DTD header http://stackoverflow.com/questions/12358 ...
- 64位Windows系统下32位应用程序连接MySql
1.首先得安装“Connector/ODBC”,就是Mysql的ODBC驱动,这个是与应用程序相关的,而不是与操作系统相关的,也就是说,不管你的系统是x64还是x86,只要你的应用程序是x86的那么, ...