Scrapy研究探索(三)——Scrapy核心架构与代码执行分析
学习曲线总是这样,简单样例“浅尝”。在从理论+实践慢慢攻破。理论永远是基础,切记“勿在浮沙筑高台”。
一. 核心架构
关于核心架构。在官方文档中阐述的非常清晰,地址:http://doc.scrapy.org/en/latest/topics/architecture.html。
英文有障碍可查看中文翻译文档。笔者也參与了Scraoy部分文档的翻译。我的翻译GitHub地址:https://github.com/younghz/scrapy_doc_chs。源repo地址:https://github.com/marchtea/scrapy_doc_chs。
以下就直接转载部分文档(地址:http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/architecture.html):
概述
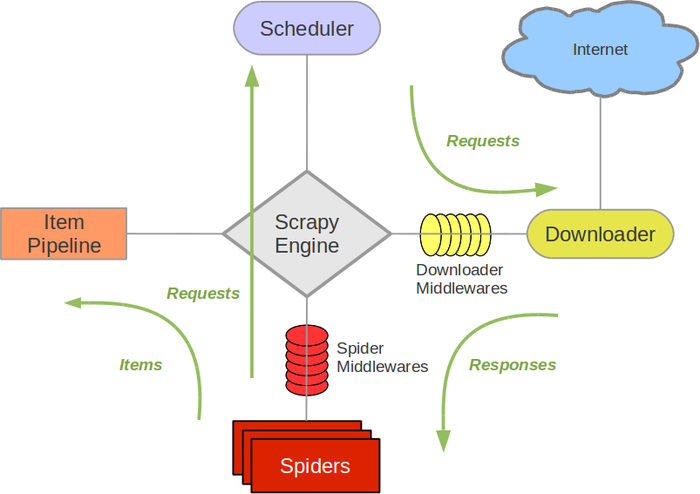
接下来的图表展现了Scrapy的架构,包含组件及在系统中发生的数据流的概览(绿色箭头所看到的)。
以下对每一个组件都做了简介,并给出了具体内容的链接。
数据流例如以下所描写叙述。
Scrapy architecture
组件
Scrapy Engine
引擎负责控制数据流在系统中全部组件中流动,并在相应动作发生时触发事件。 具体内容查看以下的数据流(Data Flow)部分。调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。每一个spider负责处理一个特定(或一些)站点。 很多其它内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(比如存取到数据库中)。 很多其它内容查看 Item Pipeline 。下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。其提供了一个简便的机制。通过插入自己定义代码来扩展Scrapy功能。很多其它内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook)。处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制。通过插入自己定义代码来扩展Scrapy功能。很多其它内容请看 Spider中间件(Middleware) 。数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其步骤例如以下:
1.引擎打开一个站点(open a domain),找到处理该站点的Spider并向该spider请求第一个要爬取的URL(s)。
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。3.引擎向调度器请求下一个要爬取的URL。
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5.一旦页面完成下载。下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6.引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9.(从第二步)反复直到调度器中没有很多其它地request,引擎关闭该站点。
二. 数据流与代码执行分析
这里主要分析数据流部分并与代码结合起来。与上面的流程1-9相应。
(1)找spider——在spider目录下查找相关定义爬虫文件
(2)引擎获取URL——自己定义spider中start_urls列表中获取
(3)...
(4)...
(5)通过(3)(4)(5)就在内部实现了依据URL生成request。下载器依据request生成response这个过程。即URL-》request-》reponse。
(6)...
(7)在自己定义spider中调用默认的parse()方法或是制定的parse_*()方法处理接收到的reponse,处理的结果非常重要:
第一个,抽取item值。
第二个,假设须要继续爬取。这里会返回request给引擎。(这是“自己主动”爬取多个网页的关键)。
(8)(9)引擎继续调度。直至无request。
进阶:
Scrapy架构呈现星型拓扑结构。“引擎”作为整个架构的核心协调、控制整个系统的执行。
原创,转载注明:http://blog.csdn.net/u012150179/article/details/34441655
Scrapy研究探索(三)——Scrapy核心架构与代码执行分析的更多相关文章
- Scrapy研究探索(六)——自己主动爬取网页之II(CrawlSpider)
原创,转载注明:http://blog.csdn.net/u012150179/article/details/34913315 一.目的. 在教程(二)(http://blog.csdn.net/u ...
- scrapy研究探索(二)——爬w3school.com.cn
下午被一个问题困扰了好一阵.终于使用还有一种方式解决. 開始教程二.关于Scrapy安装.介绍等请移步至教程(一)(http://blog.csdn.net/u012150179/article/de ...
- Scrapy研究和探索(五岁以下儿童)——爬行自己主动多页(抢别人博客所有文章)
首先.在教程(二)(http://blog.csdn.net/u012150179/article/details/32911511)中,研究的是爬取单个网页的方法.在教程(三)(http://blo ...
- Scrapy研究和探索(七)——如何防止被ban大集合策略
说来设置的尝试download_delay少于1,不管对方是什么,以防止ban策略后.我终于成功ban该. 大约scrapy利用能看到以前的文章: http://blog.csdn.net/u0121 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 大型网站技术架构(四)--核心架构要素 开启mac上印象笔记的代码块 大型网站技术架构(三)--架构模式 JDK8 stream toMap() java.lang.IllegalStateException: Duplicate key异常解决(key重复)
大型网站技术架构(四)--核心架构要素 作者:13GitHub:https://github.com/ZHENFENG13版权声明:本文为原创文章,未经允许不得转载.此篇已收录至<大型网站技 ...
- 爬虫入门三 scrapy
title: 爬虫入门三 scrapy date: 2020-03-14 14:49:00 categories: python tags: crawler scrapy框架入门 1 scrapy简介 ...
- 从零安装Scrapy心得 | Install Python Scrapy from scratch
1. 介绍 Scrapy,是基于python的网络爬虫框架,它能从网络上爬下来信息,是data获取的一个好方式.于是想安装下看看. 进到它的官网,安装的介绍页面 https://docs.scrapy ...
- scrapy基础知识之 Scrapy 和 scrapy-redis的区别:
Scrapy 和 scrapy-redis的区别 Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础 ...
随机推荐
- Unity GetComponentsInChildren<T>(true);
using System.Collections; using System.Collections.Generic; using UnityEngine; public class GetCompo ...
- Java入门系列-07-从控制台中接收输入
这篇文章帮你使用Scanner类从控制台接收输入 从控制台接收字符串 敲一敲: import java.util.Scanner; public class DemoScanner { public ...
- fabric 自动创建仓库并下载或更新代码
#!/usr/bin/python # -*- coding: utf-8 -* from fabric.api import * from fabric.contrib.files import * ...
- nginx安装及优化
1.pcre及nginx安装包下载 wget http://www.pcre.org/ pcre用yum安装即可 http://nginx.org/en/download.html 2.安装 -安 ...
- 深入理解JavaScript系列(10):JavaScript核心(晋级高手必读篇)
本篇是ECMA-262-3 in detail系列的一个概述(本人后续会翻译整理这些文章到本系列(第11-19章).每个章节都有一个更详细的内容链接,你可以继续读一下每个章节对应的详细内容链接进行更深 ...
- javascript数组与字符串之间转换
一.数组转字符串(将数组元素用某个字符连接成字符串) var a, b;a = new Array(0,1,2,3,4);b = a.join("-"); 二.字符串转数组(将字符 ...
- ASP.NET内置对象-网页转向的4中方法
ASP.NET页面跳转的方法 1.超链接 2.Response.Redirect(“Urlstring”) 3.Server.Transfer(“UrlString”) 4.PostBackUrl 1 ...
- PLC通信网络
PLC通信网络的分层 PLC通信网络大致可分为3层,管理层,单元层以及现场执行(AS-I)层.如下图所示. 在PLC通信网络的三层架构中,管理层,通信方式包括MPI,工业以太网(Profinet)以及 ...
- 【MSDN】 SqlServer DBCC解析
汇总学习下SqlServer的DBCC指令. DBCC:Transact-SQL 编程语言提供 DBCC 语句以作为 SQL Server 的数据库控制台命令. 数据库控制台命令语句可分为以下类别. ...
- oracle 常用操作记录--持续更新...
一.oracle grant 授权语句(转自:https://www.cnblogs.com/yt954437595/p/6488819.html) --select * from dba_users ...