爬虫入门三 scrapy
title: 爬虫入门三 scrapy
date: 2020-03-14 14:49:00
categories: python
tags: crawler
scrapy框架入门
1 scrapy简介
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
官方网站:https://scrapy.org/
Scrapy 0.24 文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Requests vs Scrapy
相同点:两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线两者可用性都好,文档丰富,入门简单两者都没有处理js、提交表单、应对验证码等功能(可扩展)
Requests
页面级爬虫功能库并发性考虑不足,性能较差重点在于页面下载定制灵活上手十分简单
Scrapy
网站级爬虫 框架 并发性好,性能较高 重点在于爬虫结构 一般定制灵活,深度定制困难 入门稍难
2 scrapy 框架,数据流,数据类型
2.1 scrapy框架(5+2)
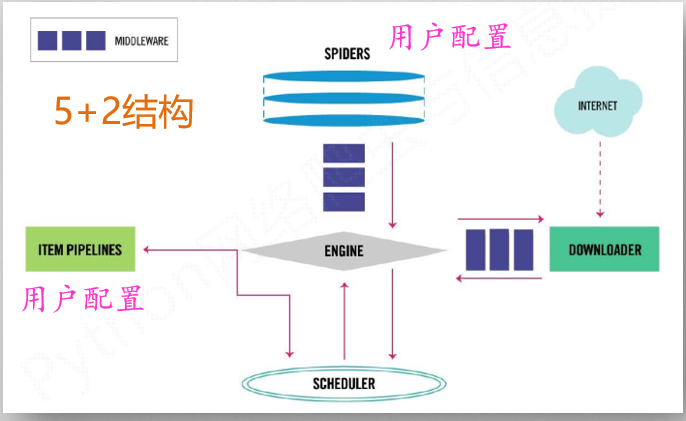
Spider
(1) 解析Downloader返回的响应(Response) (2) 产生爬取项(scraped item) (3) 产生额外的爬取请求(Request)
Engine
(1)控制所有模块之间的数据流(2)根据条件触发事件
Downloader
根据请求下载网页
Scheduler
对所有爬取请求进行调度管理
Item Pipelines
(1) 以流水线方式处理Spider产生的爬取项 (2) 由一组操作顺序组成,类似流水线 (3) 可能操作包括:清理、检验和查重爬取项中 的HTML数据、将数据存储到数据库
Downloader Middleware
目的:实施Engine、 Scheduler和Downloader 之间进行用户可配置的控制功能:修改、丢弃、新增请求或响应
Spider Middleware
目的:对请求和爬取项的再处理功能:修改、丢弃、新增请求或爬取项
2.2 scrapy数据流
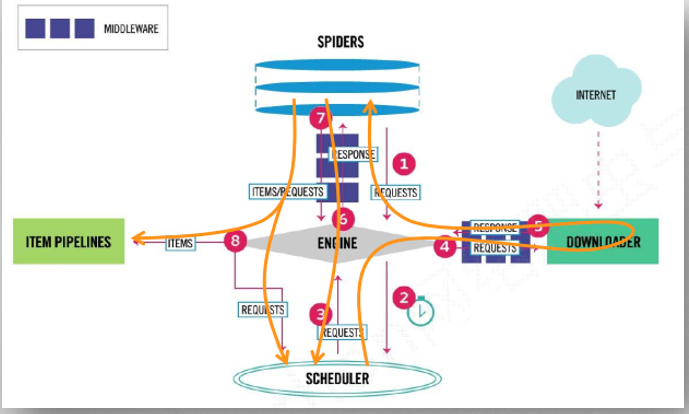
1.Engine从Spider处获得爬取请求(Request)
2.Engine将爬取请求转发给Scheduler,用于调度
3.Engine从Scheduler处获得下一个要爬取的请求
4.Engine将爬取请求通过中间件发送给Downloader
5.爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6.Engine将收到的响应通过中间件发送给Spider处理
7.Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8.Engine将爬取项发送给Item Pipeline(框架出口)
9.Engine将爬取请求发送给Scheduler
2.3 scrapy数据类型
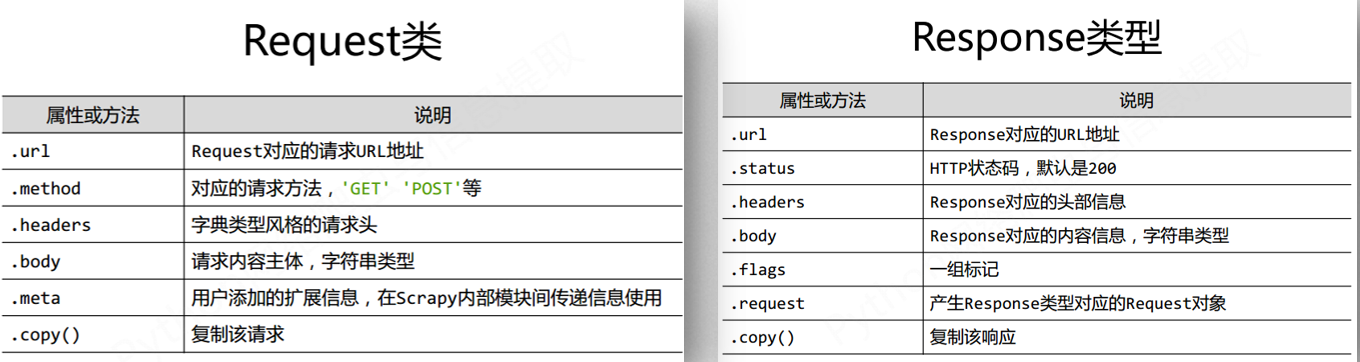
Request类
Request对象表示一个HTTP请求,
由Spider生成,由Downloader执行
Response类
Response对象表示一个HTTP响应,
由Downloader生成,由Spider处理
Item类
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
3 scrapy安装与使用
3.1 scrapy安装
3.1.1 anoconda安装
conda install scrapy
出现问题/慢,可以添加清华源
3.1.2 pip安装 不推荐
Python 3.5/3.6 下安装scrapy方法:
(1)安装lxml: pip install lxml
(2)下载对应版本的Twisted
http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install D:\Twisted-16.4.1-cp35-cp35m-win_amd64.whl
(下载好的twisted模块的whl文件路径)
(3)安装scrapy:pip install scrapy
(4)安装关联模块pypiwin32:pip install pypiwin32
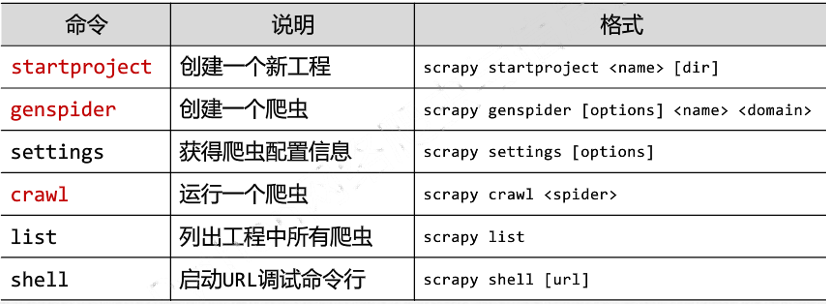
3.2 scrapy常用链接
3.3 示例
3.3.1 创建项目
命令行输入:
scrapy startproject tutorial
tutorial/
scrapy.cfg
tutorial/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
3.3.2 定义item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
编辑 tutorial 目录中的 items.py 文件:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
Field 对象仅仅是内置的 dict 类的一个别名,并没有提供额外的方法或者属性。换句话说, Field 对象完完全全就是Python字典(dict)。被用来基于类属性(class attribute)的方法来支持 item声明语法 。
3.2.3 编写spider
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
在项目中生成 spider 文件的两种方法:
命令行输入 Scrapy genspider domain domain.com
tutorial/spiders/目录下创建domain.py
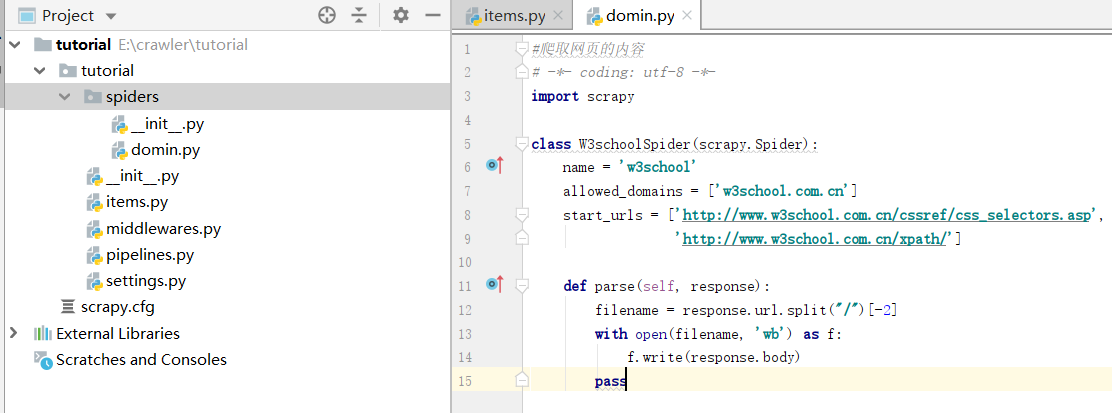
#爬取网页的内容
# -*- coding: utf-8 -*-
import scrapy
class W3schoolSpider(scrapy.Spider):
name = 'w3school'
allowed_domains = ['w3school.com.cn']
start_urls = ['http://www.w3school.com.cn/cssref/css_selectors.asp',
'http://www.w3school.com.cn/xpath/']
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
pass
3.2.4 执行spider
进入项目的根目录,执行下列命令启动spider:
scrapy crawl w3school
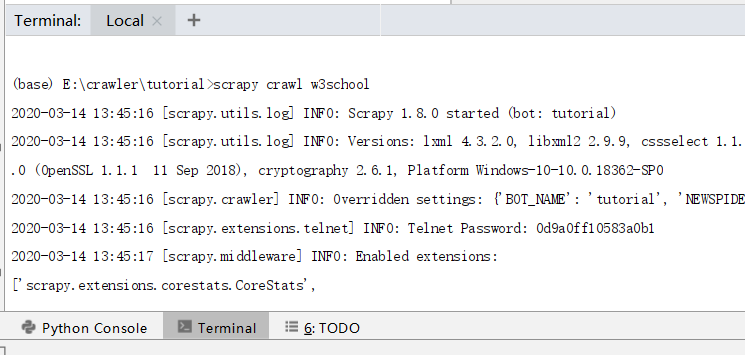
log包含定义在 start_urls 的初始URL,并且与spider中是一一对应的。在log中可以看到其没有指向其他页面( (referer:None) )。查看当前目录,两个包含url所对应的内容的文件被创建了: cssref, xpath, 正如我们的 parse 方法里做的一样。
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Request 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
3.2.5 提取item Xpath
Scrapy爬虫支持多种HTML信息提取方法:
Beautiful Soup
Lxml
Re
Xpath
CSS
3.2.6 Xpath selector
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
常见的路径表达式如下:
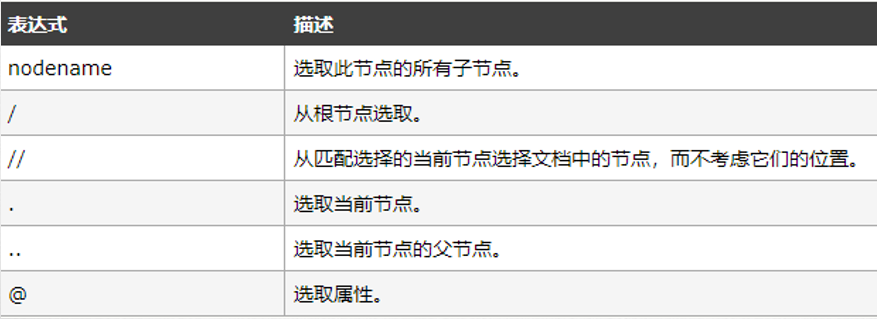

谓语(Predicates)用来查找某个特定的节点或者包含某个指定的值的节点,嵌在方括号[]中。
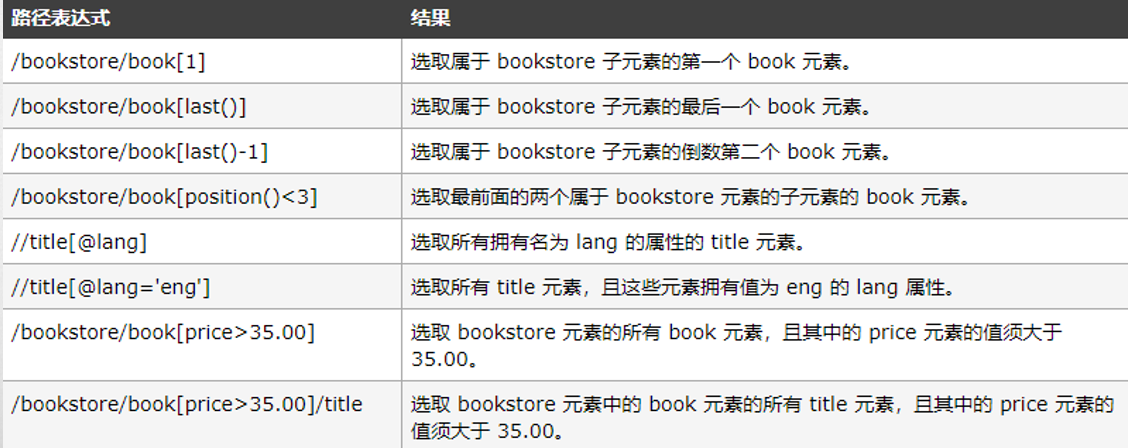
4 pycharm+anoconda+scrapy
在anaconda按照scrapy,然后打开pycharm,添加anaconda到interpreter。
然后在pycharm的命令行(下面的terminal)输入scrapy startproject xxx [mulu]
然后file,open刚刚创建好的目录,就可以使用模板了
5 建议
第3部分的示例内容比较简略,比如说spider中就没有讲parse的定义参数是因为downloader返回了reponse对象。
比如scrapy crwal w3school 中w3school是domin.py中的name。
详细内容见 https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
6 示例 豆瓣电影top250
项目:scrapy startproject douban250
6.1 item.py
import scrapy
class DoubanMovieItem(scrapy.Item):
# 排名
ranking = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 评分
score = scrapy.Field()
# 评论人数
score_num = scrapy.Field()
6.2 DoubanMovieTop250.py (spider)
from scrapy import Request
from scrapy.spiders import Spider
from douban250.items import DoubanMovieItem
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanMovieItem()
movies = response.xpath('//ol[@class="grid_view"]/li')
for movie in movies:
item['ranking'] = movie.xpath('.//div[@class="pic"]/em/text()').extract()[0]
item['movie_name'] = movie.xpath('.//div[@class="hd"]/a/span[1]/text()').extract()[0]
item['score'] = movie.xpath('.//div[@class="star"]/span[@class="rating_num"]/text()').extract()[0]
item['score_num'] = movie.xpath('.//div[@class="star"]/span/text()').re(r'(\d+)人评价')[0]
yield item
.xpath() 方法返回一个类 SelectorList 的实例, 它是一个新选择器的列表。
.re() 方法用来通过正则表达式来提取数据,返回unicode字符串的列表。
.extract() 方法串行化并将匹配到的节点返回一个unicode字符串列表。
运行后报错403,豆瓣对爬虫有限制,需要修改访问的user-agent。
将 start_urls = [‘https://movie.douban.com/top250’] 改为:
class DoubanMovieTop250Spider(Spider):
name = 'douban_movie_top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'https://movie.douban.com/top250'
yield Request(url, headers=self.headers)
start_urls URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。因此,第一个被获取到的页面的URL将是该列表之一。 后续的URL将会从获取到的数据中提取。
start_requests() 该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。当spider启动爬取并且未指定URL时,该方法被调用。当指定了URL时,make_requests_from_url() 将被调用来创建Request对象。该方法仅仅会被Scrapy调用一次,默认实现是使用 start_urls 的url生成Request。
parse(response) 当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
6.3 自动翻页 加到parse后
next_url = response.xpath('//span[@class="next"]/a/@href').extract()
if next_url:
next_url = 'https://movie.douban.com/top250' + next_url[0]
yield Request(next_url, headers=self.headers)
两种方法:
从当前页面中提取
根据URL的变化规律构造所有页面地址(适用于页面的下一页地址为JS加载)
6.4 运行
运行爬虫程序
scrapy crawl douban_movie_top250 -o douban.csv
在项目所在目录下运行爬虫,并将结果输出到.csv文件。同样支持其他序列化格式:JSON、JSON lines、XML,和多种存储方式:本地文件系统路径,ftp,Amazon S3等
报错
KeyError: 'Spider not found: douban_movie_top250'
原因是缩进问题。parse和start_requests都属于DoubanMovieTop250Spider类。
然后是settings.py出错,改为
BOT_NAME = 'douban250'
SPIDER_MODULES = ['douban250.spiders']
NEWSPIDER_MODULE = 'douban250.spiders'
然后就可以运行
6.5 输出的csv的编码问题
但是打开csv文件
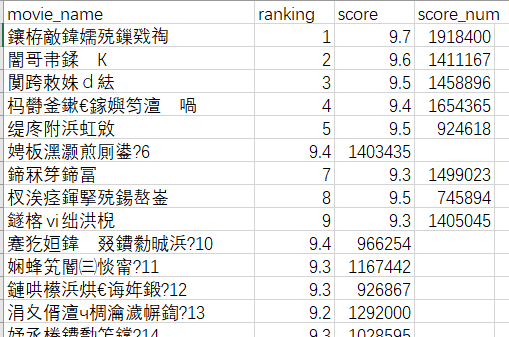
有很多问题。
参考 https://blog.csdn.net/dayun555/article/details/79416447
utf-8:全球通用编码
ascii:能存储字母/数字/符号,美国专用
gbk|gb2312|gb18030:能够存储汉字
要生成经编码后的csv类型文件
cmdline.execute(['scrapy', 'crawl', '爬虫文件名称', '-o', '文件名.csv', '-s', 'FEED_EXPORT_ENCODING="gb18030"'])
例如:cmdline.execute(['scrapy', 'crawl', 'ivsky', '-o', 'img.csv', '-s', 'FEED_EXPORT_ENCODING="gb18030"'])
要生成经编码后的json类型文件
cmdline.execute(['scrapy', 'crawl', '爬虫文件名称', '-o', '文件名.json', '-s', 'FEED_EXPORT_ENCODING=utf-8'])
例如:cmdline.execute(['scrapy', 'crawl', 'ivsky', '-o', 'img.json', '-s', 'FEED_EXPORT_ENCODING=utf-8'])
修改settings,添加
FEED_EXPORT_ENCODING = "gb18030" # gbk不行
然后再运行 scrapy crawl douban_movie_top250 -o douban.csv,内容就正常了
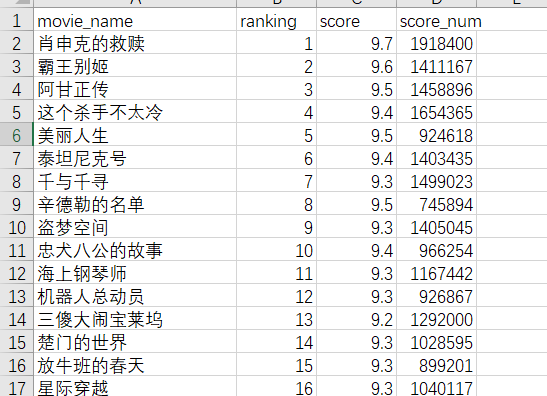
6.6 scrapy.cmdline.execute
有这个模块可以不用手动输入。
新建auto.py
# -*- coding:utf-8 -*-
from scrapy import cmdline
# 方式一:注意execute的参数类型为一个列表
cmdline.execute('scrapy crawl spidername'.split())
# 方式二:注意execute的参数类型为一个列表
cmdline.execute(['scrapy', 'crawl', 'spidername'])
cmdline.execute(['scrapy', 'crawl', '爬虫文件名称', '-o', '文件名.json', '-s', 'FEED_EXPORT_ENCODING=utf-8'])
然后运行该文件即可。
这里
from scrapy import cmdline
cmdline.execute(['scrapy', 'crawl', 'douban_movie_top250', '-o', 'doubanauto.csv'])
6.7 扩展。settings.py
可以选择性的添加。
ROBOTSTXT_OBEY = True 是否遵守robots.txt
CONCURRENT_REQUESTS = 16 开启线程数量,默认16
AUTOTHROTTLE_START_DELAY = 3 开始下载时限速并延迟时间
AUTOTHROTTLE_MAX_DELAY = 60 高并发请求时最大延迟时间
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = ‘httpcache’
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage’
以上几个参数对本地缓存进行配置,如果开启本地缓存会优先读取本地缓存,从而加快爬取速度
USER_AGENT = ‘projectname (+http://www.yourdomain.com)’
对requests的请求头进行配置,比如可以修改为‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36’同样可以避免服务器返回403
6.8 扩展。pipeline.py
可以选择性的添加。
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。如果仅仅想要保存item,则不需要实现的pipeline。
item pipeline的一些典型应用有:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
将爬取结果保存到数据库中
#去重过滤,丢弃那些已经被处理过的item。spider返回的多个item中包含有相同的id:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
爬虫入门三 scrapy的更多相关文章
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- 爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 爬虫入门之scrapy模拟登陆(十四)
注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 COOKIES_ENABLED = True或# COOKIES_ENABLE ...
- 爬虫入门之Scrapy框架实战(新浪百科豆瓣)(十二)
一 新浪新闻爬取 1 爬取新浪新闻(全站爬取) 项目搭建与开启 scrapy startproject sina cd sina scrapy genspider mysina http://roll ...
- 爬虫入门之Scrapy框架基础rule与LinkExtractors(十一)
1 parse()方法的工作机制: 1. 因为使用的yield,而不是return.parse函数将会被当做一个生成器使用.scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的 ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
随机推荐
- ftp设置二进制上传
一个不重要的数据库,备份是用expdp导出,然后上传到ftp服务器上面.上周这个主机宕机了,要在别的数据库恢复,发现报如下错误: ORA-39001: invalid argument value O ...
- 实现所有SAP设备打印机并行打印
SAP版本:ECC 6.0 701 1.如何实现所有SAP设备打印机并行打印? I.通过事务码:SPAD,进入假脱机管理初始屏幕.点击左上角的菜单中 配置(c)=>输出设备,进入SAP系统 输出 ...
- Py-上下文管理方法,描述符的应用,错误与异常
上下文管理方法: 可以在exit里面弄一些内存清理的功能 class Open: def __init__(self,name): self.name=name def __enter__(self) ...
- Java层面上下文切换
前言 在过去单CPU时代,单任务在一个时间点只能执行单一程序.之后发展到多任务阶段,计算机能在同一时间点并行执行多任务或多进程.虽然并不是真正意义上的"同一时间点",而是 多个任务 ...
- OAuth2.0是干什么的?
OAuth2.0是干什么的? 首先用户有一些数据: 将数据存储在服务器上: 这时候有一个应用要访问数据: 如果这个应用是一个恶意程序呢?所以需要一个检验来判断请求是不是安全的: 如何判断是不是安全的? ...
- the code has to work especially hard to keep things in the same thread
django/asgiref: ASGI specification and utilities https://github.com/django/asgiref/
- loj10007线段
题目描述 数轴上有 n 条线段,选取其中 k 条线段使得这 k 条线段两两没有重合部分,问 k 最大为多少. 输入格式 第一行为一个正整数 n: 在接下来的 n 行中,每行有 2 个数 a_i,b_i ...
- Language Guide (proto3) | proto3 语言指南(十)映射
Maps - 映射 如果要创建关联映射作为数据定义的一部分,协议缓冲区提供了一种方便的快捷语法: map<key_type, value_type> map_field = N; -其中k ...
- XCTF-基础Android
前期工作 查壳,无.打开看是普通的输入注册码然后验证. 逆向分析 这题太简单了,就不贴图了.看Manifest得知MainActivity是启动类,也就是点进去输入注册码那个类.密码不重要,验证成功后 ...
- Golang之如何(优雅的)比较两个未知结构的json
这是之前遇到的一道面试题,后来也确实在工作中实际遇到了.于是记录一下,如何(优雅的)比较两个未知结构的json. 假设,现在有两个简单的json文件. { "id":1, &quo ...