hadoop分布式搭建
1、新建三台机器,分别为:
hadoop分布式搭建至少需要三台机器:
- master
- extension1
- extension2
本文利用在VMware Workstation下安装Linux centOS,安装教程请看:
2、编辑ip
用ifconfig查看本机ip:
[root@master ~]# ifconfig
eno16777736: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.204.128 netmask 255.255.255.0 broadcast 192.168.204.255
inet6 fe80::20c:29ff:fe43:53ea prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:43:53:ea txqueuelen 1000 (Ethernet)
RX packets 86219 bytes 123262936 (117.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 22010 bytes 1501252 (1.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 0 (Local Loopback)
RX packets 188 bytes 33400 (32.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 188 bytes 33400 (32.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 00:00:00:00:00:00 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
extension1 和 extension2 同样如此,可以得到三台机器的ip分别为:
master:192.168.204.128
extension1:192.168.204.129
extension2:192.168.204.130
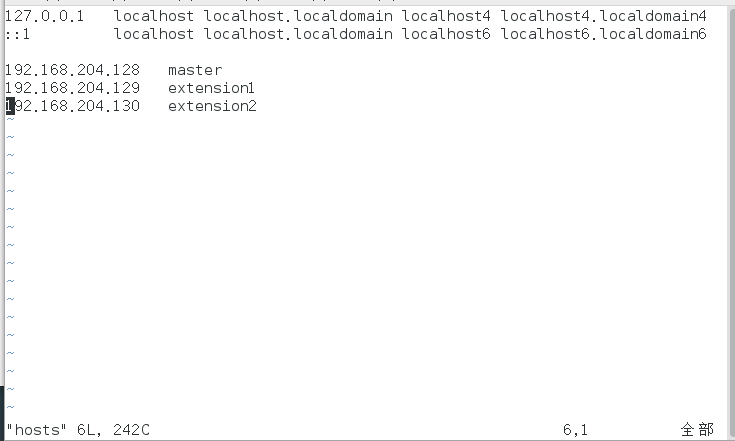
切换到/etc/hosts修改配置,隔一行在后面加上:
192.168.204.128 master
192.168.204.129 extension1
192.168.204.130 extension2
3、创建SSH密匙
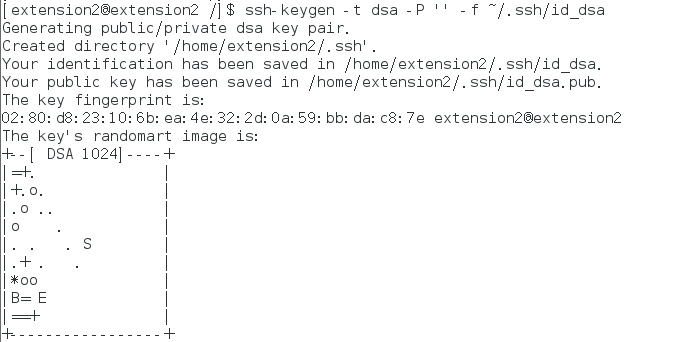
创建密匙命令:
[master@master root]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
得到样式如下:
extension1 和 extension2 同样操作
切换到密匙文件夹:/home/master/.ssh/
4、复制密匙成新文件
输入命令:
[master@master .ssh]$ cat id_dsa.pub >> authorized_keys
会在当前生成新的文件:
authorized_keys
extension1 和 extension2 同样操作
5、测试密匙
测试密匙能否使用:
- ssh localhost
- yes
- 输入密码
- exit
extension1 和 extension2 同样操作

6、extension复制master密匙
extension复制master密匙达到免密码登陆,在三台机器里面都输入下面命令:
[extension1@extension1 .ssh]$ scp master@master:~/.ssh/id_dsa.pub ./master_dsa.pub
cat master_dsa.pub >> authorized_keys
chmod 600 authorized_keys
extension1 和 extension2 同样操作
7、实现免密匙登陆
master能对master、extension1、extension2免密匙登陆:
ssh master@master
ssh extension1@extension1
ssh extension2@extension2
extension1 和 extension2 同样操作

8、下载解压安装包
查看电脑位数: getconf LONG_BIT
java地址(jdk1.7.0_09x64.tar.gz):
http://pan.baidu.com/s/1hs2uX1q
hadoop地址(hadoop-0.20.2.tar.gz):
http://vdisk.weibo.com/s/zNZl3
新建文件夹:
- 切换到 root
- 新建文件夹: mkdir /usr/program
- 放入安装包
- 解压
解压命令:
tar -zxvf hadoop-0.20.2.tar.gz
tar xvf jdk1.7.0_09x64.tar.gz
extension1 和 extension2 同样操作
9、java环境配置
打开 /etc/profile 配置文件,在最末尾加入:
# set java environment
exportJAVA_HOME=/usr/program/jdk1.7.0_09x64
exportJRE_HOME=/usr/program/jdk1.7.0_09x64/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export PATH=/usr/program/jdk1.7.0_09x64/bin
保存退出后,跟新配置文件,让配置文件生效:
source /etc/profile
查看环境是否配置成功:
java -version
extension1 和 extension2 同样操作

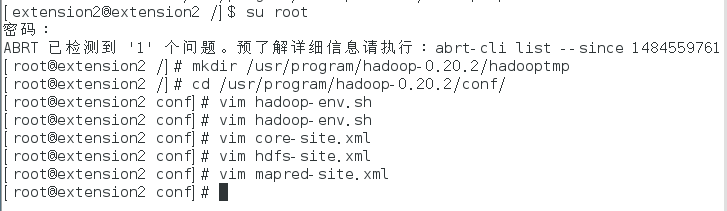
10、hadoop环境配置
创建一个文件夹:
mkdir /usr/program/hadoop-0.20.2/hadooptmp
进入文件夹:
/usr/program/hadoop-0.20.2/conf/
hadoop-env.sh:
export JAVA_HOME=/usr/program/jdk1.7.0_09x64

core-site.xml:
打开文件:
vim core-site.xml
里面的代码改成:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/program/hadoop-0.20.2/hadooptmp</value>
</property>
</configuration>

hdfs-site.xml:
打开文件:
vim hdfs-site.xml
写入以下代码:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>

mapred-site.xml:
打开文件:
vim mapred-site.xml
写入以下代码:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
</configuration>

extension1 和 extension2 同样操作
11、环境配置
打开文件:
/etc/profile
在最后面加入:
#set hadoop
export HADOOP_HOME=/usr/program/hadoop-0.20.2
export PATH=$HADOOP_HOME/bin:$PATH
使配置文件生效:
source /etc/profile
12、启动hadoop
进入文件夹:
/usr/program/hadoop-0.20.2/bin
格式化namenode:
hadoop namenode -format
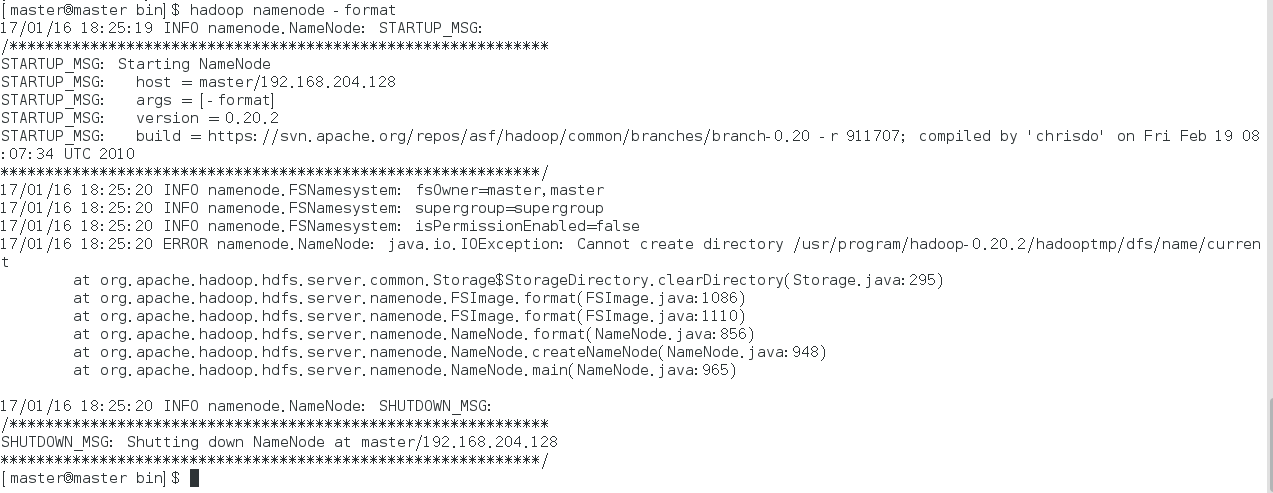
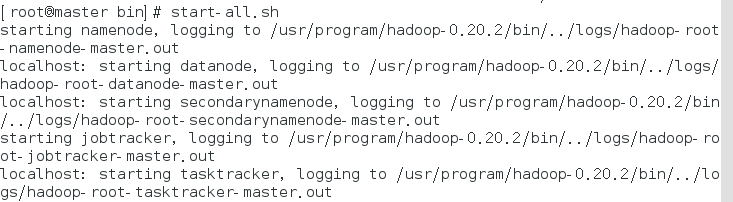
打开hadoop:
start-all.sh
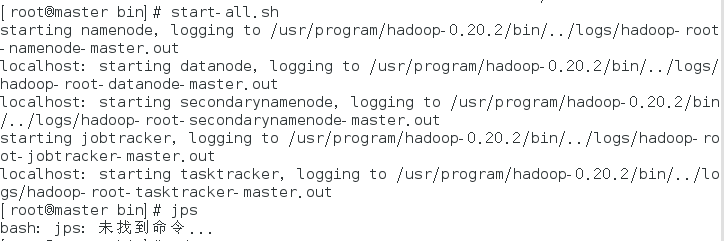
输入 jps :

但是,如果输入口输入 jps 出现:
bash: jps: 未找到命令...
方法一:
查看java目录:
which java
删除这个指引:
rm /bin/java
建立新的指引:
ln -s /usr/program/jdk1.7.0_25/bin/java /bin/java
方法二:
经过排查发现是:
jps 命令是在java解压包中的 /bin/ 文件夹里面,是一个可执行文件,但是可以用另一个方法来看是否完成启动:
stop-all.sh

但是用另一个方法查看也行,浏览器输入:
192.168.204.128:50030

浏览器输入:
192.168.204.128:50070

该完成的时候还是会完成的,切记java下载的版本下载为:
- jdk1.8.0_101
- jdk1.7.0_09
- jdk1.6.0_13
- jdk1.7.0_21
oracle地址:
http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
检查安装的JAVA包:
rpm -qa | grep jdk
卸载相应的包:
yum -y remove java-1.8.0-openjdk-headless.x86_64

hadoop分布式搭建的更多相关文章
- 攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- 暑假第二弹:基于docker的hadoop分布式集群系统的搭建和测试
早在四月份的时候,就已经开了这篇文章.当时是参加数据挖掘的比赛,在计科院大佬的建议下用TensorFlow搞深度学习,而且要在自己的hadoop分布式集群系统下搞. 当时可把我们牛逼坏了,在没有基础的 ...
- hadoop集群完全分布式搭建
Hadoop环境搭建:完全分布式 集群规划: ip hostname 192.168.204.154 master namenode resour ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
随机推荐
- docker容器访问宿主机IP
宿主机执行ifconfig 会看到docker0那个ip,可以使用来访问宿主机
- MySQL 如何使用左链接代替 NOT IN
核心思想 通过左链接 查询出要排除的数据 然后和主表进行匹配 拿去未匹配到的数据 可以使用 IS NULL 来过滤掉 案例稍后 更新 select * from a left join on a.id ...
- SSL/TLS抓包出现提示Ignored Unknown Record
SSL/TLS抓包出现提示Ignored Unknown Record 出现这种提示有两种情况.第一种,抓包迟了,部分SSL/TLS的协商数据没有获取,Wireshark无法识别和解析.第二种,数据包 ...
- AI零基础入门之人工智能开启新时代—上篇
人工智能的发展史及应用 开篇:人工智能无处不在 人工智能的发展历程 · 1945艾伦图灵在论文<计算机器不智能>中提出了著名的图灵测试,给人工智能的収展产生了深远的影响. · 1951年, ...
- UI分层中使用PageFactory
基于原PO设计模式,需要改变原有的从文件中读取文件,更改为PageFactory模式.做出如下改动: 1 2 public MsysPage(DriverBase driver) { super(dr ...
- U-Boot内存管理
如<Linux内核内存管理架构>一文中提到,linux内核中的内存管理支持内存地址映射.内存分配.内存回收.内存碎片管理.页面缓存等众多功能.但U-Boot做为启动引导程序,其核心功能就是 ...
- NOIP2006普及组 Jam的计数法
普及组重要的模拟题.附上题目链接 https://www.luogu.org/problem/show?pid=1061 (写水题题解算是巩固提醒自己细心吧qwq) 样例输入: bdfij 样例输出: ...
- jquery ajax中success与complete的执行顺序
jquery ajax中success与complete的执行顺序 jquery中各个事件执行顺序如下: 1.ajaxStart(全局事件) 2.beforeSend 3.ajaxSend(全局事件) ...
- PHP中使用CURL之php curl详细解析
在正式讲怎么用之前啊,先提一句,你得先在你的PHP环境中安装和启用curl模块,具体方式我就不讲了,不同系统不同安装方式,可以google查一下,或者查阅PHP官方的文档,还挺简单的. 1. 拿来先试 ...
- [LeetCode] Lemonade Change 买柠檬找零
At a lemonade stand, each lemonade costs $5. Customers are standing in a queue to buy from you, and ...