Hive:ORC File Format存储格式详解
一、定义
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化。
据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。
运用ORC File可以提高Hive的读、写以及处理数据的性能。
和RCFile格式相比,ORC File格式有以下优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载;
(2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
(3)、在文件中存储了一些轻量级的索引数据;
(4)、基于数据类型的块模式压缩:a、integer类型的列用行程长度编码(run-length encoding);b、String类型的列用字典编码(dictionary encoding);
(5)、用多个互相独立的RecordReaders并行读相同的文件;
(6)、无需扫描markers就可以分割文件;
(7)、绑定读写所需要的内存;
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
二、ORC File文件结构
ORC File包含一组组的行数据,称为stripes,除此之外,ORC File的file footer还包含一些额外的辅助信息。
在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
在默认情况下,一个stripe的大小为250MB。大尺寸的stripes使得从HDFS读数据更高效。
在file footer里面包含了该ORC File文件中stripes的信息,每个stripe中有多少行,以及每列的数据类型。
当然,它里面还包含了列级别的一些聚合的结果,比如:count, min, max, and sum。
下图显示出可ORC File文件结构:
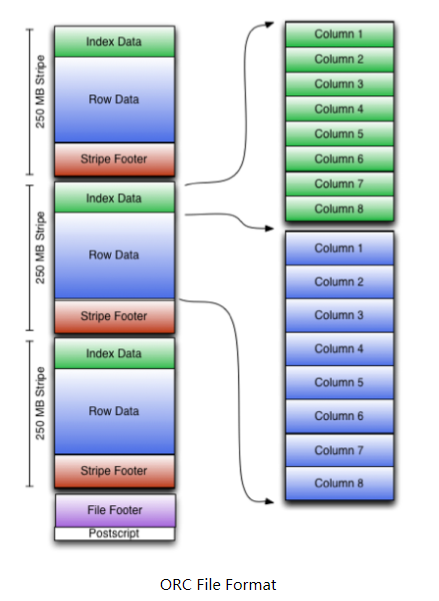
三、Stripe结构
从上图我们可以看出,每个Stripe都包含index data、row data以及stripe footer。Stripe footer包含流位置的目录;Row data在表扫描的时候会用到。
Index data包含每列的最大和最小值以及每列所在的行。
行索引里面提供了偏移量,它可以跳到正确的压缩块位置。具有相对频繁的行索引,使得在stripe中快速读取的过程中可以跳过很多行,尽管这个stripe的大小很大。
在默认情况下,最大可以跳过10000行。拥有通过过滤谓词而跳过大量的行的能力,你可以在表的 secondary keys 进行排序,从而可以大幅减少执行时间。
比如你的表的主分区是交易日期,那么你可以对次分区(state、zip code以及last name)进行排序。
四、Hive里面如何用ORCFile
在建Hive表的时候我们就应该指定文件的存储格式。所以你可以在Hive QL语句里面指定用ORCFile这种文件格式,如下:
CREATE TABLE ... STORED AS ORC ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC SET hive.default.fileformat=Orc
所有关于ORCFile的参数都是在Hive QL语句的TBLPROPERTIES字段里面出现,他们是:
| Key | Default | Notes |
|---|---|---|
| orc.compress | ZLIB | high level compression (one of NONE, ZLIB, SNAPPY) |
| orc.compress.size | 262,144 | number of bytes in each compression chunk |
| orc.stripe.size | 268435456 | number of bytes in each stripe |
| orc.row.index.stride | 10,000 | number of rows between index entries (must be >= 1000) |
| orc.create.index | true | whether to create row indexes |
下面的例子是建立一个没有启用压缩的ORCFile的表
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
五、序列化和压缩
对ORCFile文件中的列进行压缩是基于这列的数据类型是integer或者string。具体什么序列化我就不涉及了。。想深入了解的可以看看下面的英文:
Integer Column Serialization
Integer columns are serialized in two streams.
1、present bit stream: is the value non-null?
2、data stream: a stream of integers
Integer data is serialized in a way that takes advantage of the common distribution of numbers:
1、Integers are encoded using a variable-width encoding that has fewer bytes for small integers.
2、Repeated values are run-length encoded.
3、Values that differ by a constant in the range (-128 to 127) are run-length encoded.
The variable-width encoding is based on Google's protocol buffers and uses the high bit to represent whether this byte is not the last and the lower 7 bits to encode data. To encode negative numbers, a zigzag encoding is used where 0, -1, 1, -2, and 2 map into 0, 1, 2, 3, 4, and 5 respectively.
Each set of numbers is encoded this way:
1、If the first byte (b0) is negative:
-b0 variable-length integers follow.
2、If the first byte (b0) is positive:
it represents b0 + 3 repeated integers
the second byte (-128 to +127) is added between each repetition
1 variable-length integer.
In run-length encoding, the first byte specifies run length and whether the values are literals or duplicates. Duplicates can step by -128 to +128. Run-length encoding uses protobuf style variable-length integers.
String Column Serialization
Serialization of string columns uses a dictionary to form unique column values The dictionary is sorted to speed up predicate filtering and improve compression ratios.
String columns are serialized in four streams.
1、present bit stream: is the value non-null?
2、dictionary data: the bytes for the strings
3、dictionary length: the length of each entry
4、row data: the row values
Both the dictionary length and the row values are run length encoded streams of integers.
Hive:ORC File Format存储格式详解的更多相关文章
- C#中string.format用法详解
C#中string.format用法详解 本文实例总结了C#中string.format用法.分享给大家供大家参考.具体分析如下: String.Format 方法的几种定义: String.Form ...
- Python中格式化format()方法详解
Python中格式化format()方法详解 Python中格式化输出字符串使用format()函数, 字符串即类, 可以使用方法; Python是完全面向对象的语言, 任何东西都是对象; 字符串的参 ...
- Android的file文件操作详解
Android的file文件操作详解 android的文件操作要有权限: 判断SD卡是否插入 Environment.getExternalStorageState().equals( android ...
- python format 用法详解
format 用法详解 不需要理会数据类型的问题,在%方法中%s只能替代字符串类型 单个参数可以多次输出,参数顺序可以不相同 填充方式十分灵活,对齐方式十分强大 官方推荐用的方式,%方式将会在后面的版 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- Hadoop RCFile存储格式详解(源码分析、代码示例)
RCFile RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对(Key/Value Pairs)数据文件. 关键词:Reco ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
- hive lateral view 与 explode详解
ref:https://blog.csdn.net/bitcarmanlee/article/details/51926530 1.explode hive wiki对于expolde的解释如下: e ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
随机推荐
- 并发编程(十五)——定时器 ScheduledThreadPoolExecutor 实现原理与源码深度解析
在上一篇线程池的文章<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中从ThreadPoolExecutor源码分析了其运行机制.限于篇幅,留下了Scheduled ...
- 【朝花夕拾】Android性能篇之(六)Android进程管理机制
前言 Android系统与其他操作系统有个很不一样的地方,就是其他操作系统尽可能移除不再活动的进程,从而尽可能保证多的内存空间,而Android系统却是反其道而行之,尽可能保留进程.An ...
- SpringBoot入门教程(十三)CORS方式实现跨域
什么是跨域?浏览器从一个域名的网页去请求另一个域名的资源时,域名.端口.协议任一不同,都是跨域 . 跨域资源访问是经常会遇到的场景,当一个资源从与该资源本身所在的服务器不同的域或端口请求一个资源时,资 ...
- so beautiful so white
Topic Link http://ctf5.shiyanbar.com/stega/white.zip 1) 打开压缩包,接着打开图片,发现是白色的但根据提示 压缩包的密码就藏在这幅白色图片中,仔 ...
- RSA签名的PSS模式
本文由云+社区发表 作者:mariolu 一.什么是PSS模式? 1.1.两种签名方式之一RSA-PSS PSS (Probabilistic Signature Scheme)私钥签名流程的一种填充 ...
- 隔离 docker 容器中的用户
笔者在前文<理解 docker 容器中的 uid 和 gid>介绍了 docker 容器中的用户与宿主机上用户的关系,得出的结论是:docker 默认没有隔离宿主机用户和容器中的用户.如果 ...
- 【转载】C#将图片转换为二进制流调用
在C#中可以使用MemoryStream类.BinaryFormatter类等来操作图片,将图片读取到二进制数据流中,最终转成二进制数据流进行调用,详细的实现如下方法所示. private byte[ ...
- Maven(十三)Maven统一声明版本号
情景:当使用Spring下的多个包时,为了方便版本号的统一管理,避免出现因不同版本号造成的错误,必须更改为统一的版本号,但是当项目过多时手动修改不方便,因此引入此标签可以方便进行统一的修改. pom. ...
- 流程控制值while 循环
一.结束循环的两种方式 1. 修改条件tag=Truewhile tag: print(1) print(2) print(3) tag=False print(4) 2.while + break ...
- JavaScript面试总结(一)
(一).call,apply,bind 的用法与区别? 答案:摘自:https://www.cnblogs.com/Jade-Liu18831/p/9580410.html(总结的特别棒的一篇文章) ...