hadoop入门之设置datanode的心跳时间的方法
做作业的过程中发现,把一节点停掉,dfsadmin和50070都无法马上感知到一个data node已经死掉
HDFS默认的超时时间为10分钟+30秒。
这里暂且定义超时时间为timeout
计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
参考 http://f.dataguru.cn/thread-128378-1-1.html
--------------------------
Linux环境:CentOs6.4
Hadoop版本:Hadoop-1.1.2
master: 192.168.1.241 NameNode JobTracker DataNode TaskTracker
slave:192.168.1.242 DataNode TaskTracker
内容:设置DataNode的心跳,当某一个节点失去连接之后,在超过设置的时间,看hadoop能否正常工作。
设置时间:
代码如下:
<name>heartbeat.recheck.interval</name>
<value>15</value>
</property>
第一步: 配置hdfs-site.xml
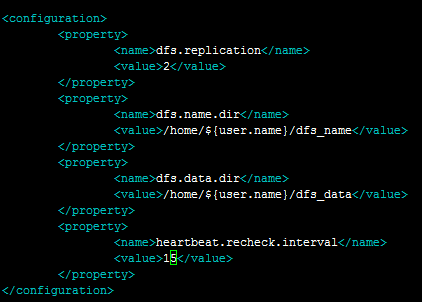
第二步:重启Hadoop
第三步:通过网页浏览两个节点的状态。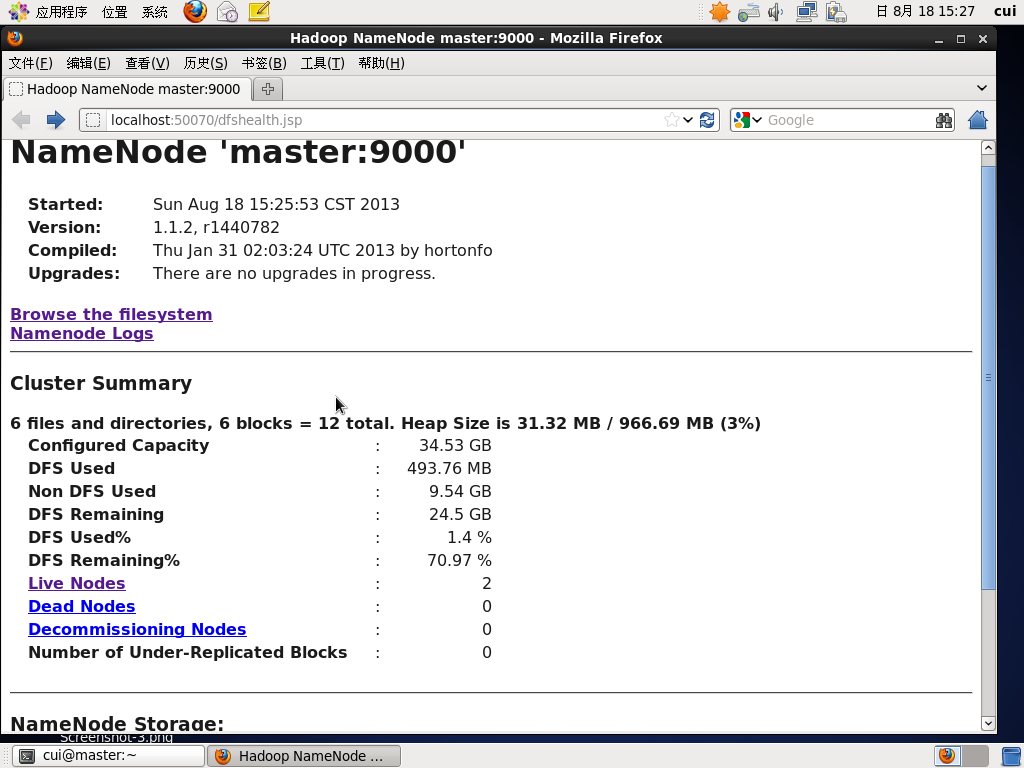
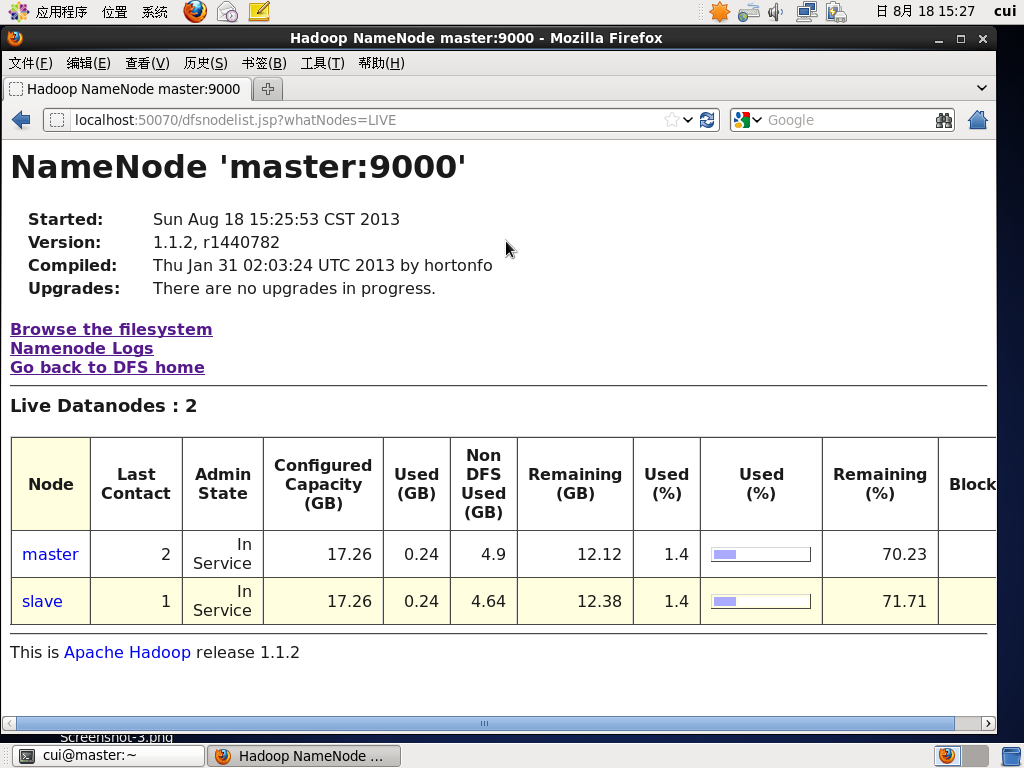
hadoop两个节点都已正常运行。
第三步:杀死主节点的进程,等待15秒。
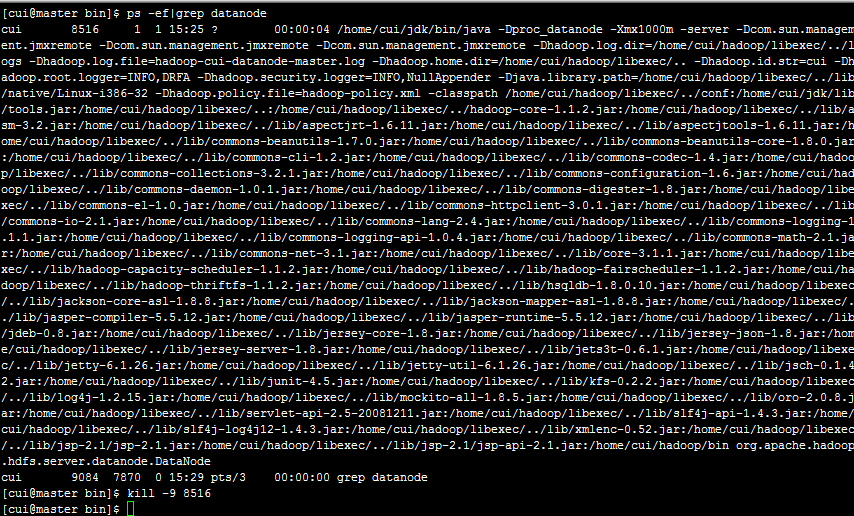
通过kill命令杀死master上的DataNode节点。
第四步:查看节点状态
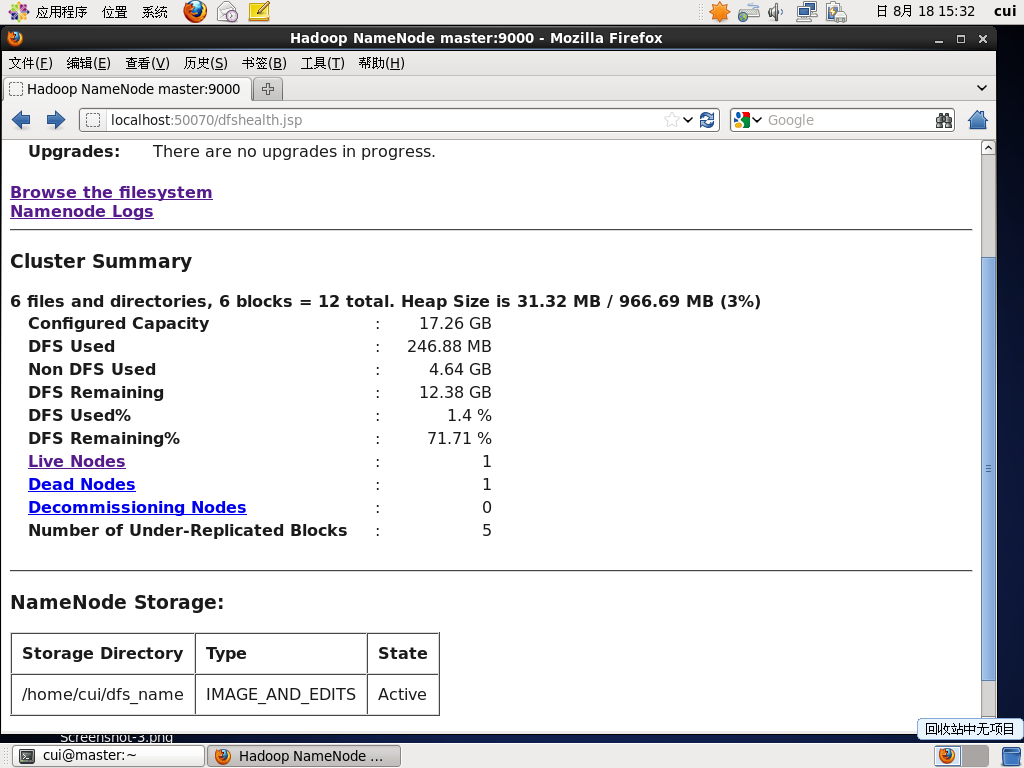
活着的DataNode还有1个,死亡的DataNode一个
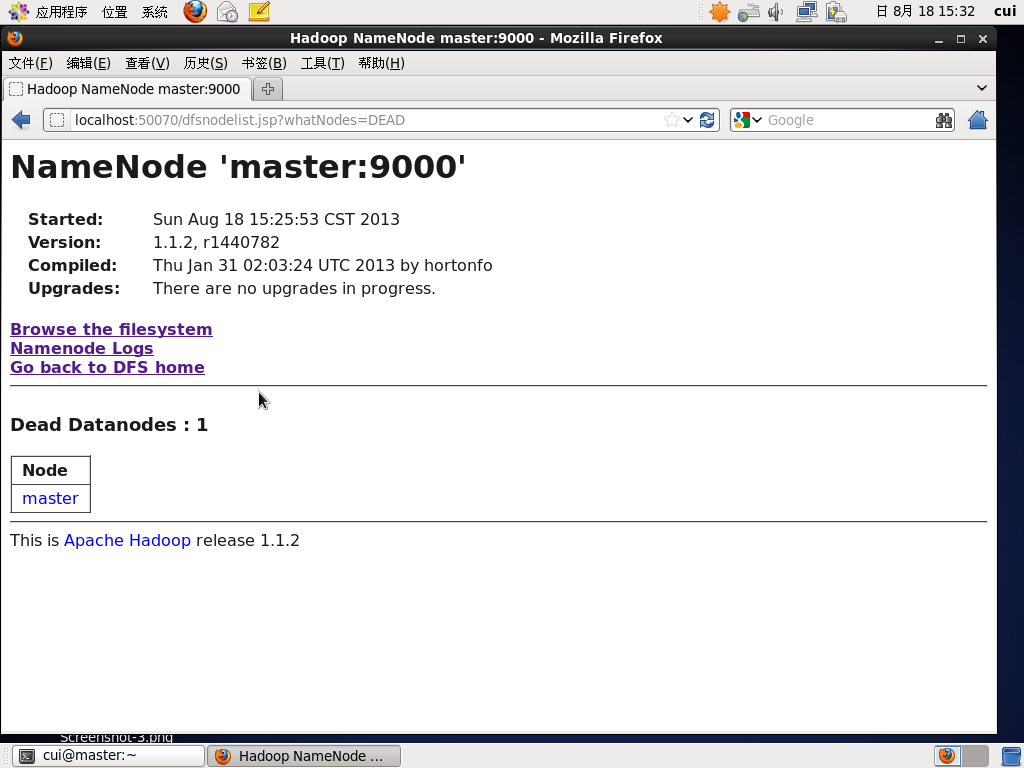
master上的DataNode节点已经标识为Dead

只剩下slave节点,其最后连接时间是2秒(Last Contact 2)
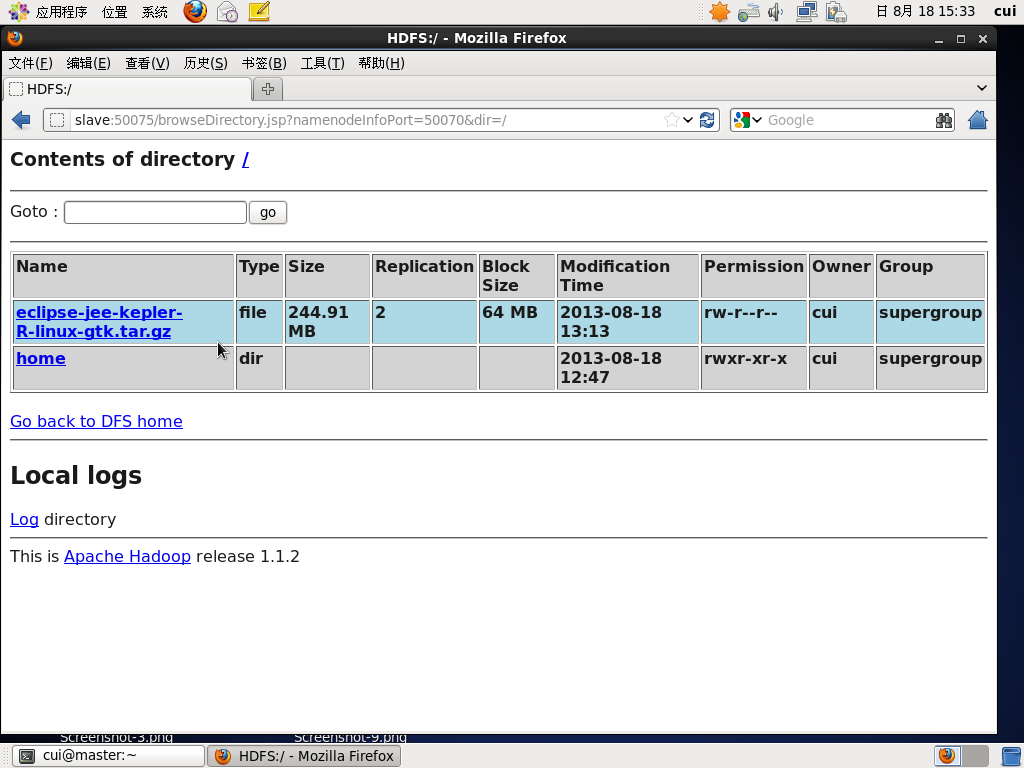
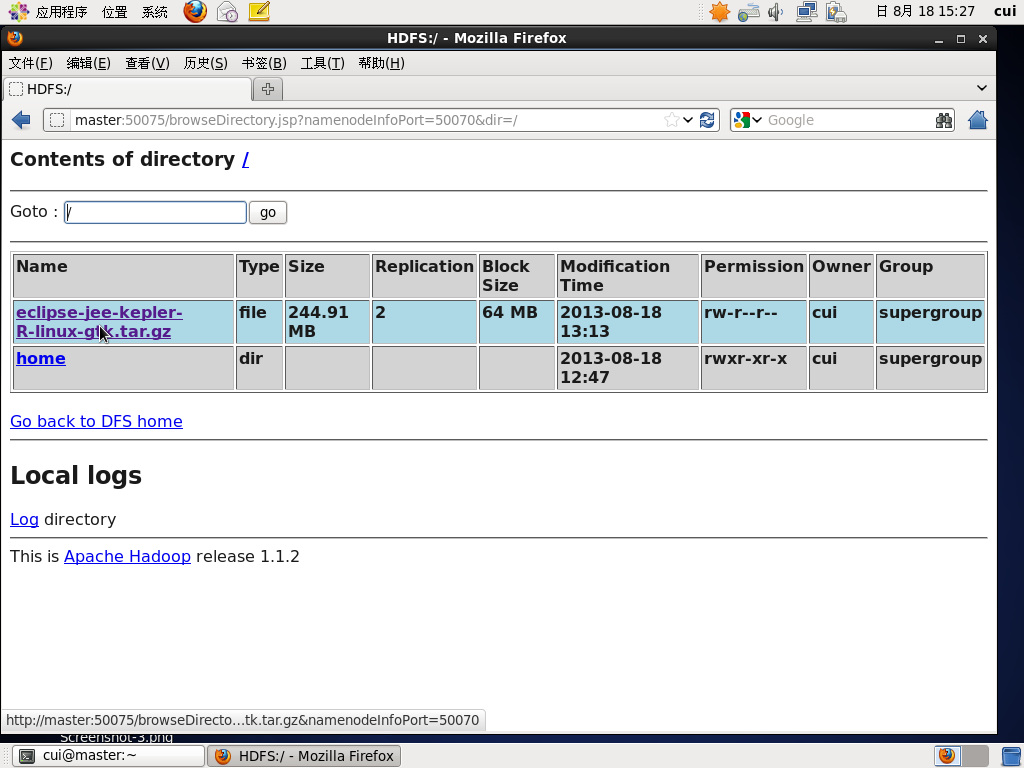
杀死一个节点,两一个节点仍能够正常查看文件信息。

只有slave节点在运行。
http://www.jb51.net/softjc/137250.html
hadoop入门之设置datanode的心跳时间的方法的更多相关文章
- Android 通过应用设置系统日期和时间的方法
Android 通过应用设置系统日期和时间的方法 android 2.3 android 4.0 测试可行,不过需要ROOT权限. ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- java设置配置session过期时间的方法
1) Timeout in the deployment descriptor (web.xml)以分钟为单位 代码如下 复制代码 <web-app ...> <session-co ...
- 【Hadoop】Hadoop DataNode节点超时时间设置
hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间 ...
- hadoop之 心跳时间与冗余快清除
1.Hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段 ...
- hadoop入门手册1:hadoop【2.7.1】【多节点】集群配置【必知配置知识1】
问题导读 1.说说你对集群配置的认识?2.集群配置的配置项你了解多少?3.下面内容让你对集群的配置有了什么新的认识? 目的 目的1:这个文档描述了如何安装配置hadoop集群,从几个节点到上千节点.为 ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- Hadoop入门之hdfs
大数据技术开篇之Hadoop入门[hdfs] 学习都是从了解到熟悉的过程,而学习一项新的技术的时候都是从这个技术是什么?可以干什么?怎么用?如何优化?这几点开始.今天这篇文章分为两个部分.一. ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
随机推荐
- wooyunAPI
经常要爬去乌云的信息,但是每次都是硬爬,写完了发现乌云有提供API的,整理给大家: 1. WooYun Api是什么 通过WooYun开放的Api接口,其它网站或应用可以根据自己获取的权限调用WooY ...
- Java Web表达式注入
原文:http://netsecurity.51cto.com/art/201407/444548.htm 0×00 引言 在2014年6月18日@终极修炼师曾发布这样一条微博: 链接的内容是一个名为 ...
- <<易货>>项目Postmortem结果
设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 一开始想做的事情还是太多,没有形成整个app的核心功能,浪费了很多时间. 是否有充足的时间来做计划? 有 ...
- Class.asSubclass浅谈
这是java.lang.Class中的一个方法,作用是将调用这个方法的class对象转换成由clazz参数所表示的class对象的某个子类.举例来说, 上面的代码将strList.getClass() ...
- TAROT.
/* * * */ #include<stdio.h> #include<stdlib.h> #include<time.h> int main() { int t ...
- Python学习(14)模块一
目录 Python 模块 import语句 from ... import 语句 from ... import * 语句 定位模块 PYTHONPATH变量 命名空间和变量 dir()函数. glo ...
- (一)使用springAPI以及自定义类 实现AOP-aop编程
Spring的另一个重要思想是AOP,面向切面的编程,它提供了一种机制,可以在执行业务前后执行另外的代码,Servlet中的Filter就是一种AOP思想的体现,下面通过一个例子来感受一下. 假设我们 ...
- mysql ERROR 1044 (42000): Access denied for user ''@'localhost' to database
新安装的mysql密码是空的. ./mysql -u root -p use mysql SELECT `Host`,`User` FROM user; UPDATE user SET `Host` ...
- bloom filter 详解[转]
Bloom Filter概念和原理 焦萌 2007年1月27日 Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.Bloom ...
- Freemarker 入门示例(zhuan)
http://cuisuqiang.iteye.com/blog/2031768 ************************************ 初步学习freemarker ,先做一个简单 ...