BogoMips 和cpu主频无关 不等于cpu频率
http://tinylab.org/explore-linux-bogomips/
内核探索:Linux BogoMips 探秘
By Tao Hongliang of TinyLab.org 2015/04/12
1 背景
今天和往常一样,在实验室和一群攻城师同事们没日没夜的码着代码。突然,一个同学问了一句: /proc/cpuinfo (龙芯平台) 里的 BogoMIPS 和 CPU 的频率是什么关系? 一石激起千层浪,一时间各种奇葩的答案层出不穷,最终也没个定论。本攻城师决定直捣黄龙一探究竟,给迷茫的小伙伴们一个交代。
2 BogoMIPS 的由来
BogoMIPS 是 Linus 本人的独创,Bogo 意思是“假的,伪造的”,MIPS 意思是“Millions of Instructions Per Second”,如果系统启动时,计算出 BogoMIPS 为 100,可记为 100万条伪指令每秒。
之所以叫伪指令,是因为在计算 BogoMIPS 的值时,CPU 一直在单一的执行 NOP (空操作),而不是随机执行指令集中的任意指令,所以不能以此作为 CPU 的性能指标。
3 BogoMIPS 的计算
现在就让我们走进代码,看看他是怎么计算的。笔者是在 v3.13.0 版本的 Linux kernel 源码中做的实验。这一部分变动很少,其他相似版本应该无差别。 </br>
首先,在文件 arch/mips/kernel/proc.c 中给出了 BogoMIPS 的计算方式:
- seq_printf(m, "BogoMIPS\t\t: %u.%02u\n",
- cpu_data[n].udelay_val / (500000/HZ),
- (cpu_data[n].udelay_val / (5000/HZ)) % 100);
其中 HZ 是在内核配置的时候就确定好的常量,那在这个公式里就只剩 udelay_val 的值是未知的了。小提醒:这里是一个经典的用整型来表达浮点类型的例子,小伙伴们可以学习下。 </br>
然后,在文件 arch/mips/include/asm/bugs.h中给出了 udelay_val 的计算方式:
- cpu_data[cpu].udelay_val = loops_per_jiffy;
最后,在文件init/calibrate.c中,我们能找到 loops_per_jiffy 的计算方式:
- #define LPS_PREC 8
- static unsigned long calibrate_delay_converge(void)
- {
- /* First stage - slowly accelerate to find initial bounds */
- unsigned long lpj, lpj_base, ticks, loopadd, loopadd_base, chop_limit;
- int trials = 0, band = 0, trial_in_band = 0;
- lpj = (1<<12);
- /* wait for "start of" clock tick */
- /* 这里很聪明的选择了一个计算 loops 的起始时间,即,一个 tick 刚开始的时候 */
- ticks = jiffies;
- while (ticks == jiffies)
- ; /* nothing */
- /* Go .. */
- ticks = jiffies;
- /* 这里用逐渐逼近的方式计算在一个jiffy的时间段内,循环调用 __delay(NOP 循环),
- * 最后累计 delay 了多少。loops_per_jiffy 就是多少了。
- */
- do {
- if (++trial_in_band == (1<<band)) {
- ++band;
- trial_in_band = 0;
- }
- __delay(lpj * band);
- trials += band;
- } while (ticks == jiffies);
- /*
- * We overshot, so retreat to a clear underestimate. Then estimate
- * the largest likely undershoot. This defines our chop bounds.
- */
- trials -= band;
- loopadd_base = lpj * band;
- lpj_base = lpj * trials;
- /* 接下来,再对上面算出来的 loops_per_jiffy 的值进行微调,确保其准确 */
- recalibrate:
- lpj = lpj_base;
- loopadd = loopadd_base;
- /*
- * Do a binary approximation to get lpj set to
- * equal one clock (up to LPS_PREC bits)
- */
- chop_limit = lpj >> LPS_PREC;
- while (loopadd > chop_limit) {
- lpj += loopadd;
- ticks = jiffies;
- while (ticks == jiffies)
- ; /* nothing */
- ticks = jiffies;
- __delay(lpj);
- if (jiffies != ticks) /* longer than 1 tick */
- lpj -= loopadd;
- loopadd >>= 1;
- }
- /*
- * If we incremented every single time possible, presume we've
- * massively underestimated initially, and retry with a higher
- * start, and larger range. (Only seen on x86_64, due to SMIs)
- */
- if (lpj + loopadd * 2 == lpj_base + loopadd_base * 2) {
- lpj_base = lpj;
- loopadd_base <<= 2;
- goto recalibrate;
- }
- return lpj;
- }
这下我们搞清楚了 loops_per_jiffy 的实质。详细计算方式,可以参考上面代码中给出的中文注释。
- BogoMIPS = loops_per_jiffy ÷ (500000 / HZ) ---> BogoMIPS = (loops_per_jiffy * HZ) ÷ 500000
HZ 是什么,HZ 就是每秒的滴答数,即每秒的 jiffy 数。那么,loops_per_jiffy * HZ = loops_per_second
- BogoMIPS = loops_per_second ÷ 500000 ---> BogoMIPS = (loops_per_second * 2) ÷ 1000000
自此,BogoMIPS 的计算探秘结束。
4 BogoMIPS 和 CPU 频率的关系
看了上面 BogoMIPS 的计算方式,我们发现并没有一个直接的公式可以让 BogoMIPS 和 CPU 频率之间相互转换。但至少可以推断出对于同一款处理器:
- CPU 频率越快,loops_per_second 的值必然越大,那么 BogoMIPS 的值将会越大;
- CPU 频率越低,则 BogoMIPS 的值将越小;
- CPU 变频的时候,BogoMIPS 会随着 CPU 频率升高而升高,降低而降低。
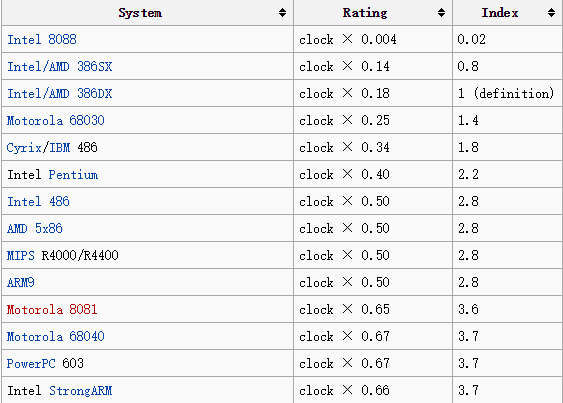
引用 维基百科上已有的数据,可以进一步的对于 BogoMIPS 和 CPU 频率之间的关系,有更深的感性认识:
| 支付宝打赏 ¥9.68元 |
微信打赏 ¥9.68元 |
|
 |
 请作者喝杯咖啡吧 |
 |
Read Related:
- LWN 646950: 重新设计 “时间轮(timer wheel)”
- LWN 228143: 可延迟定时器
- LWN 558284: 整个系统都空闲了吗?
- LWN 574962: 时钟广播框架(The tick broadcast framework)
- LWN 549580: 3.10 版本开始支持(接近)完全无周期时钟(full tickless)
Read Latest:
BogoMips 和cpu主频无关 不等于cpu频率的更多相关文章
- 基础 - 获得CPU主频
// 获得cpu主频.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <windows.h> #include ...
- Cpu 主频与睿频
主频就是一颗CPU的运行频率.比如一颗CPU是2.3G,无论是单核还是多核,所有的核心都是工作在2.3G. 睿频是Intel的一项加速技术,指当启动一个运行程序后,处理器会自动加速到合适的频率,而原来 ...
- 【UEFI】---关于BIOS,EIST和PState&CState和CPU主频变化得关系
Intel处理器都支持Turbo和EIST,且一般情况下,各家厂商在BIOS中都会设置EIST和PState的开关,那么这些开关与CPU的频率的关系是什么呢?今天对此做个总结: 按照国际惯例,本次梳理 ...
- (四)CPU主频与”性能“
一.什么是性能 CPU的性能就是就是时间的倒数,简单来说:耗时越少,性能越好,主要包含下面两个指标: 响应时间:程序执行耗时 吞吐率:单位时间处理数据或执行程序的量 缩短响应时间,一定时间内可以执行更 ...
- cpu主频信息
yangkunvanpersie ( yangkunvanpersie@163.com ) 通过"有道云笔记"邀请您查看以下笔记 修改CPU频率.note 打开笔记 kerne ...
- Linux下如何查看高CPU占用率线程 LINUX CPU利用率计算
目录(?)[-] proc文件系统 proccpuinfo文件 procstat文件 procpidstat文件 procpidtasktidstat文件 系统中有关进程cpu使用率的常用命令 ps ...
- CPU Rings, Privilege, and Protection.CPU的运行环, 特权级与保护
原文标题:CPU Rings, Privilege, and Protection 原文地址:http://duartes.org/gustavo/blog/ [注:本人水平有限,只好挑一些国外高手的 ...
- 初识CPU卡、SAM卡/CPU卡简介、SAM卡简介 【转】
初识CPU卡.SAM卡/CPU卡简介.SAM卡简介 IC卡按照接口方式可分为接触式卡.非接触式卡.复合卡:按器件技术可分为非加密存储卡.加密存储卡和CPU卡. 加密存储卡是对持卡人的认证,只有输入正确 ...
- 【转帖】处理器史话 | 这张漫画告诉你,为什么双核CPU能打败四核CPU?
处理器史话 | 这张漫画告诉你,为什么双核CPU能打败四核CPU? https://www.eefocus.com/mcu-dsp/371324 2016-10-28 10:28 作者:付丽华预计 9 ...
随机推荐
- ECharts绘制折线图
首先看实现好的页面 实现 首先引入echarts工具 // vue文件中引入echarts工具 let echarts = require('echarts/lib/echarts') require ...
- GoF设计模式合集
1 概述 这篇文章是对GoF23种设计模式+1种非GoF模式的合集,由笔者自己的笔记整理而来,每个模式都详细描述了步骤,角色等,以及使用Java实现的具体的例子. 2 基础 设计模式概述 UML与面向 ...
- DevOps之Jenkins相关知识
目录 认识Jenkins 持续集成 持续交付 Jenkins简介 为什么需要Jenkins Jenkins的目标 Jenkins安装 初次使用Jenkins 加速插件安装 Jenkins-CI Jen ...
- 分解uber依赖注入库dig-使用篇
golang的依赖注入库非常的少,好用的更是少之又少,比较好用的目前有两个 谷歌出的wire,这个是用抽象语法树在编译时实现的. uber出的dig,在运行时,用返射实现的,并基于dig库,写了一个依 ...
- 1.7.8- HTML合并单元格
跨行与跨列
- 如何使用Vue中的slot
之前看官方文档,由于自己理解的偏差,不知道slot是干嘛的,看到小标题,使用Slot分发内容,就以为 是要往下派发内容.然后就没有理解插槽的概念.其实说白了,使用slot就是先圈一块地,将来可能种花种 ...
- spring boot 实现redis 的key的过期监听,执行自己的业务
最近几天进一步了解了一下redis,发现了key的过期监听功能,实现方式如下: 在redis的配置文件 redis.conf 中找到"EVENT NOTIFICATION"模块, ...
- 基于dalvik模式下的Xposed Hook开发的某加固脱壳工具
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/77966109 这段时间好好的学习了一下Android加固相关的知识和流程也大致把A ...
- POJ1178枚举三个地方(所有点都去同一个点)
题意: 有一个国王和很多骑士,他们都要到某一个点去集合,然后问所有人都到达某个终点的距离和最小是多少?过程中如果国王遇到了一个骑士的话,国王就可以和骑士一起按照骑士的走法走,这是两个人算一 ...
- POJ1703带权并查集(距离或者异或)
题意: 有两个黑社会帮派,有n个人,他们肯定属于两个帮派中的一个,然后有两种操作 1 D a b 给出a b 两个人不属于同一个帮派 2 A a b 问a b 两个人关系 输出 同一个帮派 ...