Hive(十三)【Hive on Spark 部署搭建】
Hive on Spark 官网详情:https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
一.安装Hive
具体安装参考:Hive(一)【基本概念、安装】
安装和Spark对应版本一起编译的Hive,当前官网推荐的版本关系如下:
| HiveVersion | SparkVersion |
|---|---|
| 1.1.x | 1.2.0 |
| 1.2.x | 1.3.1 |
| 2.0.x | 1.5.0 |
| 2.1.x | 1.6.0 |
| 2.2.x | 1.6.0 |
| 2.3.x | 2.0.0 |
| 3.0.x | 2.3.0 |
| master | 2.3.0 |
二.安装Spark
①在Hive所在机器安装Spark,配置Spark on Yarn模式。
可以将spark的日志,集成到Yarn上
②配置Spark的环境变量。
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile.d/my_env.sh
具体安装参考:Spark(一)【spark-3.0安装和入门】
三.向HDFS上传Spark纯净版jar包
使用不带hadoop的spark的包:spark-3.0.0-bin-without-hadoop.tgz
①解压
tar -zxvf /opt/software/spark/spark-3.0.0-bin-without-hadoop.tgz
②上传只HDFS的/spark-jars目录,该目录在下面需要配置
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
四.修改hive-site.xml文件
添加如下内容
<!--Spark依赖位置,上面上传jar包的hdfs路径-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎,使用spark-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
注意: hive.spark.client.connect.timeout的默认值是1000ms,如果执行hive的insert语句时,抛如下异常,可以调大该参数到10000ms
FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session d9e0224c-3d14-4bf4-95bc-ee3ec56df48e
五.测试
①启动hive的metstore服务和hive客户端
[root@hadoop102 ~]$ hive --service metastore
[root@hadoop102 hive]$ bin/hive
②创建一张测试表
hive (default)> create table student(id int, name string);
③通过insert测试效果
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功,第一次初始化spark session比较费时间,下次执行就很快了。
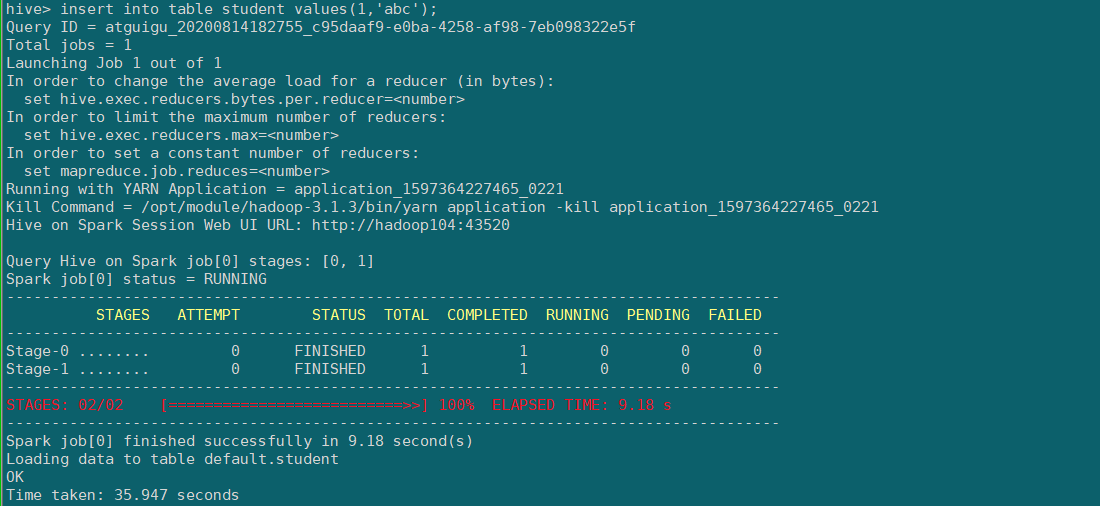
hive on spark 的相关原理可参考
FAQ
1.执行sql语句,报错信息。
hive> insert into table student values(1,'abc');
Query ID = atguigu_20200814150018_318272cf-ede4-420c-9f86-c5357b57aa11
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job failed with java.lang.ClassNotFoundException: org.apache.spark.AccumulatorParam
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
原因:由于当前的hive的版本3.1.2,spark版本3.0.0,只能自己编译。
建议用官方发布的hive+spark版本搭配。
2.启动hive的metstore服务,不然可能报错
hive> insert into table student values(1,'abc');
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
Hive(十三)【Hive on Spark 部署搭建】的更多相关文章
- 再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)
进入我这篇博客的博友们,相信你们具备有一定的spark学习基础和实践了. 先给大家来梳理下.spark的运行模式和常用的standalone.yarn部署.这里不多赘述,自行点击去扩展. 1.Spar ...
- Hive On Spark环境搭建
Spark源码编译与环境搭建 Note that you must have a version of Spark which does not include the Hive jars; Spar ...
- Spark环境搭建(四)-----------数据仓库Hive环境搭建
Hive产生背景 1)MapReduce的编程不便,需通过Java语言等编写程序 2) HDFS上的文缺失Schema(在数据库中的表名列名等),方便开发者通过SQL的方式处理结构化的数据,而不需要J ...
- Hive记录-Hive on Spark环境部署
1.hive执行引擎 Hive默认使用MapReduce作为执行引擎,即Hive on mr.实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on ...
- 【原创】大叔经验分享(24)hive metastore的几种部署方式
hive及其他组件(比如spark.impala等)都会依赖hive metastore,依赖的配置文件位于hive-site.xml hive metastore重要配置 hive.metastor ...
- Hive 1.2.1&Spark&Sqoop安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 服务端口 2 4. 安装MySQL 2 4.1. 安装MySQL 2 4.2. 创建Hive元数据库 4 5. 安装步骤 5 5.1. 下载Hiv ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- 数仓Hive和分布式计算引擎Spark多整合方式实战和调优方向
@ 目录 概述 Spark on Hive Hive on Spark 概述 编译Spark源码 配置 调优思路 编程方向 分组聚合优化 join优化 数据倾斜 任务并行度 小文件合并 CBO 谓词下 ...
- ubuntu下搭建hive(包括hive的web接口)记录
Hive版本 0.12.0(独立模式) Hadoop版本 1.12.1 Ubuntu 版本 12.10 今天试着搭建了hive,差点迷失在了网上各种资料中,现在把我的经验分享给大家,亲手实践过,但未必 ...
随机推荐
- 寻找下一个结点 牛客网 程序员面试金典 C++ java Python
寻找下一个结点 牛客网 程序员面试金典 C++ java Python 题目描述 请设计一个算法,寻找二叉树中指定结点的下一个结点(即中序遍历的后继). 给定树的根结点指针TreeNode* root ...
- SpringCloud微服务实战——搭建企业级开发框架(十二):OpenFeign+Ribbon实现负载均衡
Ribbon是Netflix下的负载均衡项目,它主要实现中间层应用程序的负载均衡.为Ribbon配置服务提供者地址列表后,Ribbon就会基于某种负载均衡算法,自动帮助服务调用者去请求.Ribbo ...
- Piakchu之RCE漏洞
一.Ping(远程系统命令执行) 首先正常输入一个ip,查看页面的返回值.发现有乱码,但是能看出执行了ping命令. 查看源代码,可以看到只是对操作系统进行了判断,而对输入内容是否为ip地址并没有判断 ...
- 【centos】更换yum源
yum下载有时候很慢,可以换一下源: 步骤: 1)下载wget yum install -y wget 2)备份默认的yum mv /etc/yum.repos.d /etc/yum.repos.d. ...
- MySQL新建用户并赋予权限:解决命令行与Navicat展示数据库不一致问题
1.创建新用户 'xiaoxiao'密码'123456' mysql> CREATE USER 'xiaoxiao'@'localhost' IDENTIFIED BY '123456'; 2. ...
- 【Python+postman接口自动化测试】(3)什么是接口测试?
什么是接口测试? 接口测试是测试系统组件间接口的一种测试.接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点.测试的重点是要检查数据的交换.传递和控制管理过程,以及系统间的相互逻辑依 ...
- Netty数据如何在 pipeline 中流动
前言 在之前文章中,我们已经了解了pipeline在netty中所处的角色,像是一条流水线,控制着字节流的读写,本文,我们在这个基础上继续深挖pipeline在事件传播 Unsafe对象 顾名思义,u ...
- 解读Java8的Thread源码
1.创建的一个无参的Thread对象,默认会有一个线程名,以Thread-开头,从0开始计数,采用了一个static修饰的int变量,当对象初始化一次时一直存放在jvm方法区中 2.构造Thread的 ...
- Python进阶(装饰器)
from datetime import datetime def log(func):#func表示装饰器作用于的函数 def wrapper(*args,**kw):#wrapper返回装饰器作用 ...
- 大爽Python入门教程 0-2 什么是IDE?python选什么IDE好?
大爽Python入门公开课教案 点击查看教程总目录 一 感受IDE 什么是IDE? 在这里,我并不想直接给出一个回答, 因为这个回答对初学者来说,可能有些抽象. 我想先带大家感受下IDE. 1 比较不 ...