14-1-Unsupervised Learning ---dimension reduction
无监督学习(Unsupervised Learning)可以分为两种:
化繁为简
- 聚类(Clustering)
- 降维(Dimension Reduction)
无中生有(Generation)
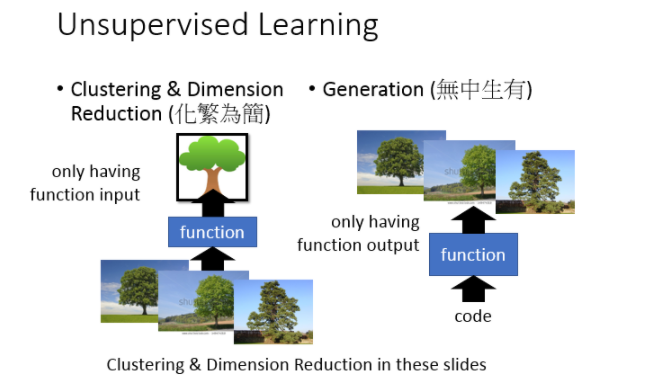
所谓的“化繁为简”的意思:现在有很多种不同的input,比如说:你现在找一个function,它可以input看起来很多像树的东西,output都是抽象的树,把本来比较复杂的input变成比较简单的output。那在做unsupervised learning的时候,你只会有function的其中一边。比如说:我们要找一个function要把所有的树都变成抽象的树,但是你所拥有的train data就只有一大堆的image(各种不同的image),你不知道它的output应该是要长什么样子。
那另外一个unsupervised learning可以做Generation,也就是无中生有,我们要找一个function,你随机给这个function一个input(输入一个数字1,然后output一棵树;输入数字2,然后output另外一棵树)。在这个task里面你要找一个可以画图的function,你只有这个function的output,但是你没有这个function的input。你这只有一大堆的image,但是你不知道要输入什么样的code才会得到这些image。这张投影片我们先focus在dimension reduction这件事上,而且我们只focus在linear dimension reduction上。

Clustering(聚类)
Introduction
聚类,顾名思义,就是把相近的样本划分为同一类,比如对下面这些没有标签的image进行分类,手动打上cluster 1、cluster 2、cluster 3的标签,这个分类过程就是化繁为简的过程
一个很critical的问题:我们到底要分几个cluster?

K-means
Clustering中最常用的方法是K-means方法


HAC
HAC,全称Hierarchical Agglomerative Clustering,层次聚类
假设现在我们有5个样本点,想要做clustering:
build a tree:
整个过程类似建立Huffman Tree,只不过Huffman是依据词频,而HAC是依据相似度建树
- 对5个样本点两两计算相似度,挑出最相似的一对,比如样本点1和2
- 将样本点1和2进行merge (可以对两个vector取平均),生成代表这两个样本点的新结点
- 此时只剩下4个结点,再重复上述步骤进行样本点的合并,直到只剩下一个root结点
pick a threshold:
选取阈值,形象来说就是在构造好的tree上横着切一刀,相连的叶结点属于同一个cluster
下图中,不同颜色的横线和叶结点上不同颜色的方框对应着切法与cluster的分法
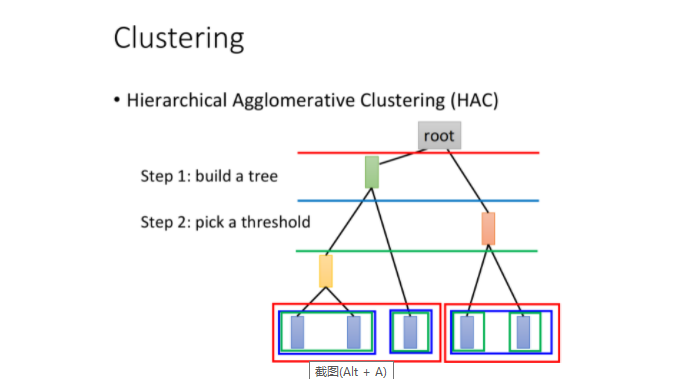
那cluster有另外一种方法叫做Hierarchical Agglomerative Clusteing(HAC),那这个方法是先建一个tree。假设你现在有5个example,你想要把它做cluster,那你先做一个tree structure,咋样来建这个tree structure呢?你把这5个example两两去算它的相似度,然后挑最相似的那个pair出来。假设最相似的那个pair是第一个example和第二个example merge起来再平均,得到一个新的vector,这个vector代表第一个和第二个example。现在只剩下四笔data了,然后两两再算相似度,发现说最后两笔是最像的,再把他们merge average起来。得到另外一笔data。现在只剩下三笔data了,然后两两算他们的similarity,发现黄色这个和中间这个最像,然后再把他们平均起来,最后发现只剩红色跟绿色,在把它们平均起来,得到这个tree 的root。你就根据这五笔data他们之间的相似度,就建立出一个tree structure,这只是建立一个tree structure,这个tree structure告诉我们说:哪些example是比较像的。比较早分枝代表比较不像的。
接下来你要做clustering,你要决定在这个tree structure上面切一刀(切在图上蓝色的线),你如果切这个地方的时候,那你就把你的五笔data变成是三个cluster。如果你这一刀切在红色的那部分,就变成了二个cluster,如果你这一刀切在绿色这一部分,就变成了四个cluster。这个就是HAC的做法
HAC跟刚才K-means最大的差别就是:你如果决定你的cluster的数目,在k-means里面你要决定K value是多少,有时候你不知道有多少cluster不容易想,你可以换成HAC,好处就是你现在不决定有多少cluster,而是决定你要切在这个 tree structure的哪里。
总结:
HAC和K-means最大的区别在于如何决定cluster的数量,在K-means里,K的值是要你直接决定的;而在HAC里,你并不需要直接决定分多少cluster,而是去决定这一刀切在树的哪里
Dimension Reduction
Introduction
clustering的缺点是以偏概全,它强迫每个object都要属于某个cluster
但实际上某个object可能拥有多种属性,或者多个cluster的特征,如果把它强制归为某个cluster,就会失去很多信息;我们应该用一个vector来描述该object,这个vector的每一维都代表object的某种属性,这种做法就叫做Distributed Representation。
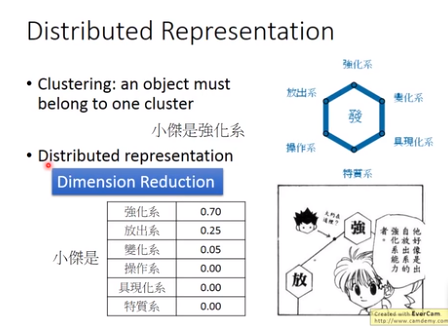
如果原先的object是high dimension的,比如image,那现在用它的属性来描述自身,就可以使之从高维空间转变为低维空间,这就是所谓的降维(Dimension Reduction)
上图为动漫“全职猎人”中小杰的念能力分布,从表中可以看出我们不能仅仅把他归为强化系。
降维
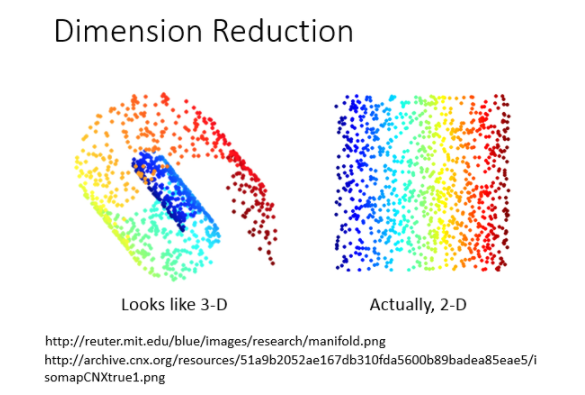
那从另外一个角度来看:为什么dimension reduction可能是有用的。举例来说:假设你的data分布是这样的(在3D里面像螺旋的样子),但是用3D空间来描述这些data其实是很浪费的,其实你从资源就可以说:你把这个类似地毯卷起来的东西把它摊开就变成这样(右边的图)。所以你只需要在2D的空间就可以描述这个3D的information,你根本不需要把这个问题放到这个3D来解,这是把问题复杂化,其实你可以在2D就可以做这个task。
举一个具体的例子
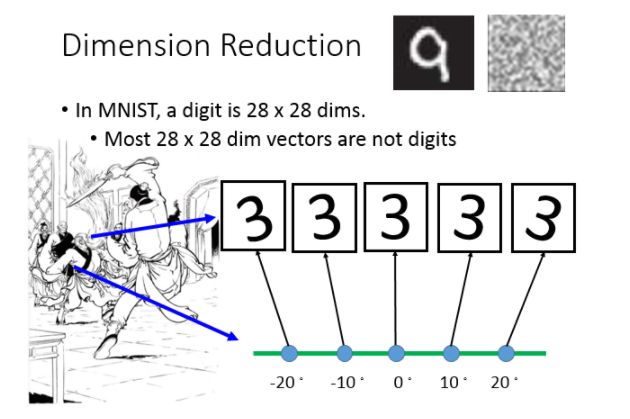

How to do Dimension Reduction?
Feature Selection


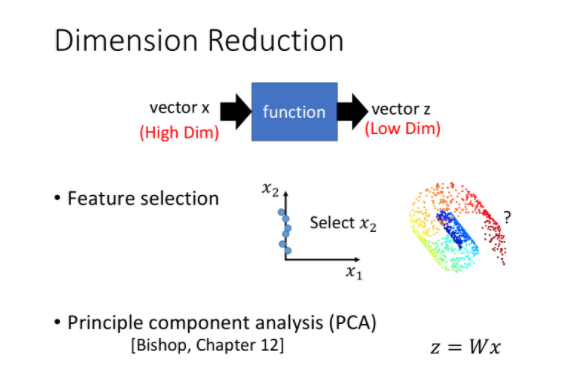
PCA(Principe Component Analysis)

那怎么做dimension reduction呢?在做dimension reduction的时候,我们要做的事情就是找一个function,这个function的input是一个vector x,output是另外一个vector z。但是因为是dimension reduction,所以你output这个vector z这个dimension要比input这个x还要小,这样才是在做dimension reduction。
PCA for 1-D
后面在补充
14-1-Unsupervised Learning ---dimension reduction的更多相关文章
- 无监督学习:Linear Dimension Reduction(线性降维)
一 Unsupervised Learning 把Unsupervised Learning分为两大类: 化繁为简:有很多种input,进行抽象化处理,只有input没有output 无中生有:随机给 ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- Beginners Guide To Learn Dimension Reduction Techniques
Beginners Guide To Learn Dimension Reduction Techniques Introduction Brevity is the soul of wit This ...
- 机器学习,数据挖掘,统计学,云计算,众包(crowdsourcing),人工智能,降维(Dimension reduction)
机器学习 Machine Learning:提供数据分析的能力,机器学习是大数据时代必不可少的核心技术,道理很简单:收集.存储.传输.管理大数据的目的,是为了“利用”大数据,而如果没有机器学习技术分析 ...
- 无监督学习(Unsupervised Learning)
无监督学习(Unsupervised Learning) 聚类无监督学习 特点 只给出了样本, 但是没有提供标签 通过无监督学习算法给出的样本分成几个族(cluster), 分出来的类别不是我们自己规 ...
- Unsupervised Learning: Use Cases
Unsupervised Learning: Use Cases Contents Visualization K-Means Clustering Transfer Learning K-Neare ...
- Unsupervised Learning and Text Mining of Emotion Terms Using R
Unsupervised learning refers to data science approaches that involve learning without a prior knowle ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- Unsupervised learning无监督学习
Unsupervised learning allows us to approach problems with little or no idea what our results should ...
随机推荐
- Django整理(一) - 项目和应用创建及运行
一.项目组织结构 · 一个Project包含有多个App · 一个App就是一个Python包,就代表一个功能模块,比如: 用户模块,商品模块等 .各个功能模块间可以保持相对的独立 . ...
- docker-compose 搭建kafka集群
docker-compose搭建kafka集群 下载镜像 1.wurstmeister/zookeeper 2.wurstmeister/kafka 3.sheepkiller/kafka-manag ...
- 基于ZooKeeper,Spring设计实现的参数系统
一.简介 基于ZooKeeper服务端.ZooKeeper Java客户端以及Spring框架设计的用于系统内部进行参数维护的系统. 二.设计背景 在我们日常开发的系统内部,开发过程中最常见的一项工作 ...
- Spring的JDK动态代理如何实现的(源码解析)
前言 上一篇文章中提到了SpringAOP是如何决断使用哪种动态代理方式的,本文接上文讲解SpringAOP的JDK动态代理是如何实现的.SpringAOP的实现其实也是使用了Proxy和Invoca ...
- Frida高级逆向-Hook Java
Frida Hook Java 层 Frida两种启动方式的区别 span 模式:frida 重新打开一个进程 frida -U -f 包名 -l js路径 --no-pause attch 模式: ...
- 解决更新页面版本后用户需CTRL+F5强刷才能应用最新页面
设置文件永远不从缓存读取 第一步:在html文件设置文件不缓存 <!DOCTYPE html> <html lang="en" class="theme ...
- ES2020新特性记录
1.可选链操作符 // oldlet ret = obj && obj.first && obj.first.second// newlet ret = obj?.fi ...
- 第五次Scrum Metting
日期:2021年5月2日 会议主要内容概述:讨论前端进度,修改后端接口. 一.进度情况 组员 负责 两日内已完成的工作 后两日计划完成的工作 工作中遇到的困难 徐宇龙 后端 模板模块的实现及批量插入更 ...
- RAW RGB格式
RAW RGB格式 10bit Raw RGB, 就是说用10bit去表示一个R, G, 或者B, 通常的都是用8bit的. 所以你后面处理时要把它转换为8bit的, 比较简单的方法就是将低两位去掉, ...
- Codeforces Round #742 (Div. 2)题解
链接 \(A,B\)题签到,就完了. \(C\)题,考虑进位时多进一位,由于是隔一位进的,所以可以发现奇数位和偶数位是相互独立的,那么我们就把奇数位和偶数位单独拉出来组成数字例如:34789,我们单独 ...