【Redis的那些事 · 续集】Redis的位图、HyperLogLog数据结构演示以及布隆过滤器
一、Redis位图
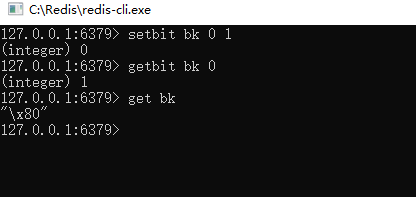
1、位图的最小单位是bit,每个bit的值只能是0和1,位图的应用场景一般用于一些签到记录,例如打卡等。
场景举例: 例如某APP要存储用户的打卡记录,如果按照正常的思路来做,可能是用户每天是否打卡的记录都单独设置一个key-value键值对来存储,这样的话,每个用户每天都需要耗费一个键值对空间。而如果是位图,就可以很方便地通过位图来进行记录,例如如下图:

位图不算基础数据结构或者特殊数据结构,其本质上还是字符串。由于每个bit代表一个数据,所以还可以当作是bit数组来看待。
2、可以通过命令:
setbit key 偏移量(索引位) value(0/1,默认是0)
进行设置对应位置的位图数据。
通过命令:
getbit key 偏移量
可以获取到对应的位图索引数据。
也可以通过:
get key
来获取位图对应的字符串信息。
3、例如hello字符串的ascii码对应的二进制,分别是:
h: 01101000
e: 01100101
l: 01101100
l: 01101100
o: 01101111
以下设置字符串hello的位图操作,如图所示,字符串对应二进制数拼接起来的二进制,值为1所在的bit索引位(offset),使用:
setbit key offset 1
进行设置1即可。
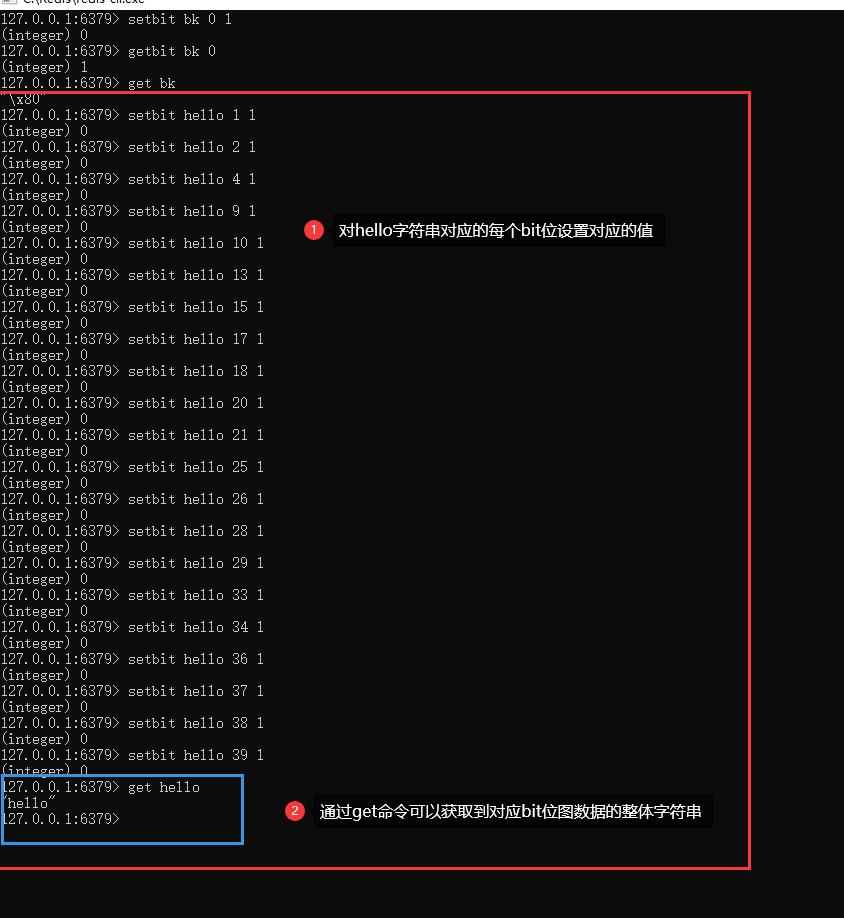
setbit/gitbit 和 set/get 实际上是可以互相转换的,只是一种是操作bit位,一种是操作直接的值。同时可以互相交叉操作使用,例如setbit存储,get读取;set 存储,getbit读取等等。
4、可以通过命令: bitcount key 起始字符索引 结束字符索引
对指定key里面的数据,指定的字符索引区间内,获取到对应的位图数据是1的个数。如果不指定,则会获取到全部字符串对应位图的1的个数。如下图所示,结合以上二进制数据可知,h字符有3个1,o字符有6个1。
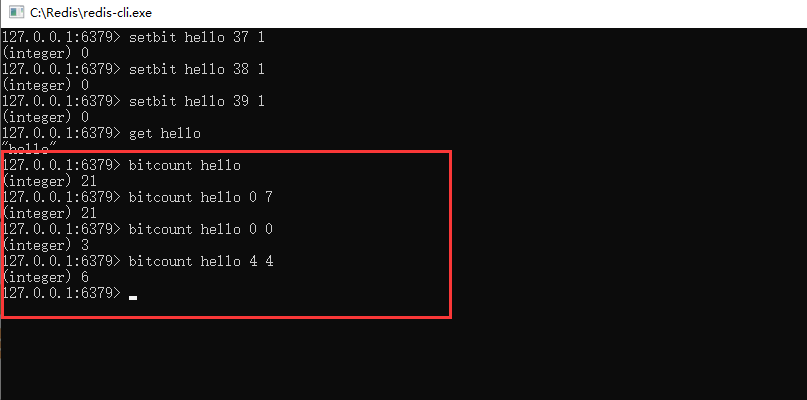
以上指令操作可以适用于在类似打卡天数统计上使用,可以快速统计出区间内为1的数据个数。
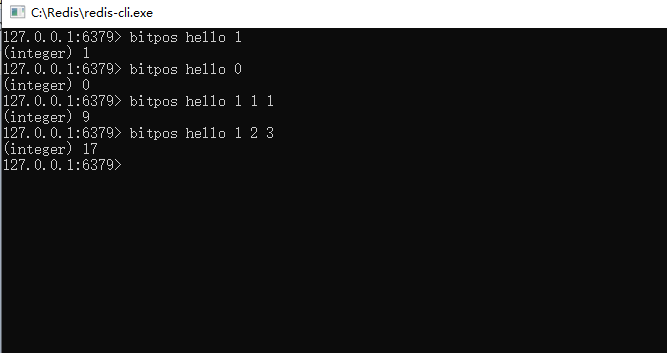
5、通过命令:bitops key bit值(0/1) 起始字符索引 结束字符索引
可以获取到指定的区间内,第一次出现指定的bit值(0或1)所在的位图索引。如果不指定区间,默认代表字符串全部区间。如下图所示,hello里面,第一次出现1是在位图的第一个索引位置;第一次出现0是在第0个位图索引位;字符索引位为1代表第二个字符,第一次出现的值为1的位图索引位置为9。
注意: 字符串的索引,0到N,0代表第一个字符,例如’h’。位图的索引,也是0到N,0代表位图上面第一个bit位,值为0或者1,例如h的位图索引位置是0的值是0 (01101000)
6、可以通过命令:
bitfield key get 类型 位图索引
来获取指定类型数据的ascii码。
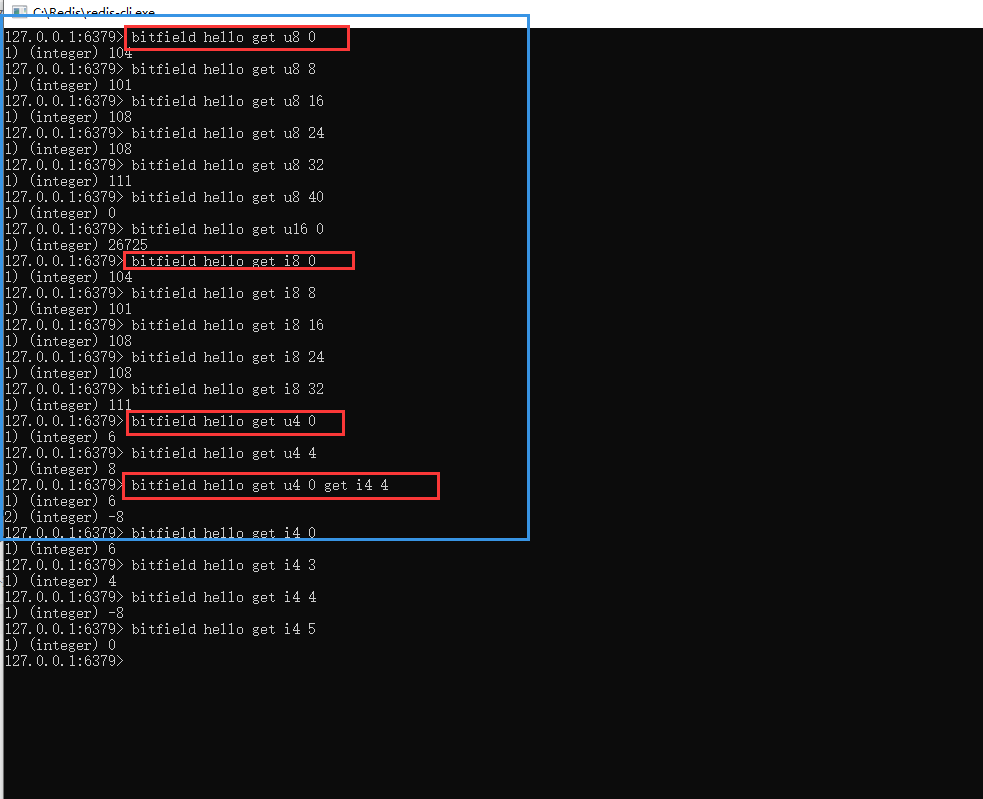
例如,以下截图中,命令:
bitfield hello get u8 0
其中,u8代表类型,u开头代表无符号数据,8代表获取8个bit位。如果是有符号的数据,是以i开头的。最后面的0,代表要获取的起始位图下标索引,此处是第0个索引。
hello五个字符,对应的ascii码分别为:104,101,108,108,111
如果以上命令的类型 u8 换成 u4 ,则获取到的值是0110,对应的值是6;以此类推。
也可以并列get获取,例如:
bitfield key get type1 offset1 type2 offset2 ……
其他玩法,大佬们可以自己尝试。我这边有关操作可以参考如下截图所示内容。
7、通过命令:
bitfield key set type 位图索引 ascii码
可以把对应的ascii码根据类型写入到指定的索引中,并且会返回原来索引被替换的ascii码值。
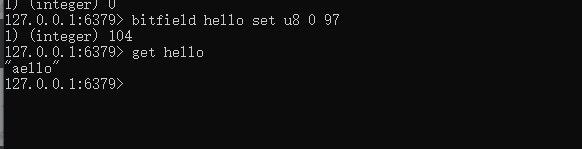
例如下图所示操作,位图索引从0开始,代表第一个字符h所在位置。97代表a的ascii码,执行以后,返回104(h的ascii码),并且通过get命令可以查看到字符串已经被替换了。
8、可以使用命令:
bitfield key incrby type 索引 自增值
对指定类型和索引区间的值进行累加 ,如下图所示。h通过 u8 类型自增1,即h+1=i
注意:对于累加的数据不能超出指定类型的最大值,例如 u4 最大值是15,累加到15以后会自动折返为0。

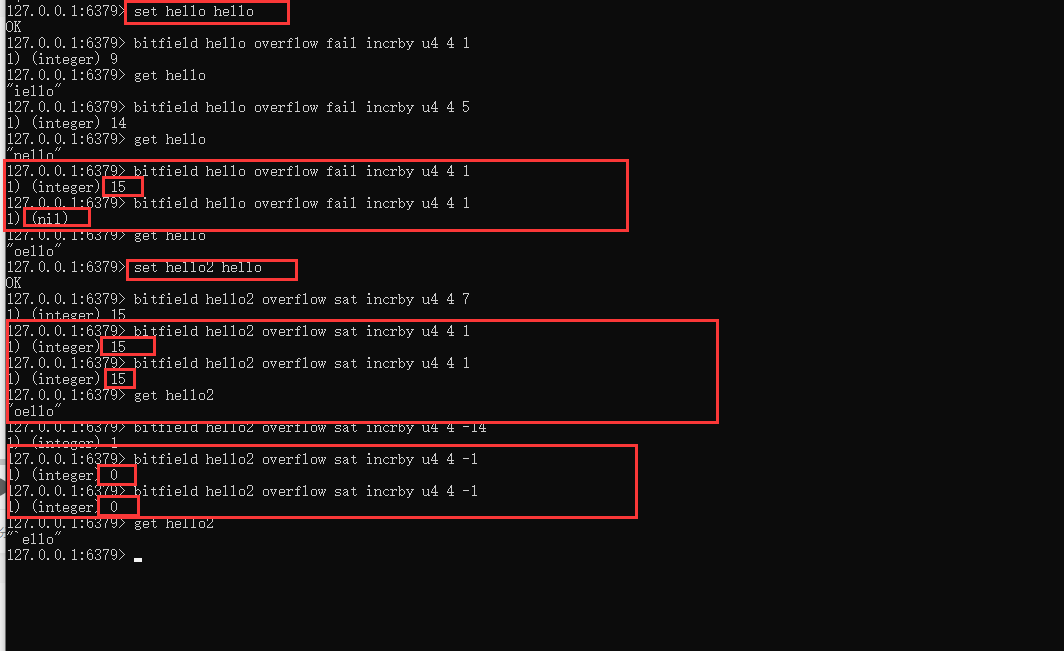
9、针对以上会出现折返的情况,可以使用溢出报错或者保持最大或最小值的方式来避免折返的情况。
使用命令:
Bitfield key overflow fail incrby type offset value
可以实现溢出的时候,会返回nil;
使用命令:
Bitfield key overflow sat incrby type offset value
可以实现当要溢出的时候,还是会返回当前的最大值或最小值。如下图所示。
二、HyperLogLog
10、HyperLogLog是一种可以快速去重的数据结构。但是有一定的误差率,大概在0.81%左右。应用场景一般是在需要针对一些大数据量的情况下进行去重计算大概的统计值使用,例如网站的PV量等等。
使用命令:
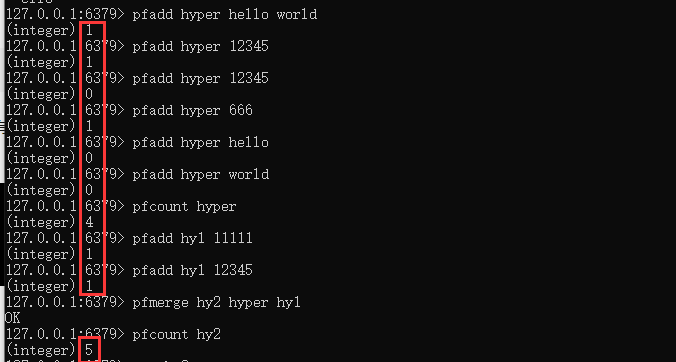
pfadd key value1 value2 ……
可以添加对应的多个数据集到指定的key里面去。
如果添加已经存在的数据,会被自动去重。
使用命令:pfcount key
可以统计数据集的个数。
使用命令:pfmerge 目标key 源key1 源key2 ……
可以对多个不同的key进行数据合并,并且数据集重复的会自动排重。
使用HyperLogLog的用途,是在针对大数据量的情况下,在允许一定的容错率的情况下,用它可以节约资源并且快速地进行排重。例如使用set来设置数据,资源损耗肯定是巨大的;但是使用hyperloglog来处理,资源损耗是固定的12kb,可以处理的数据量大约是2^64个数据。
冷门科普:命令是pf开头,是为了纪念HyperLogLog的作者——Philippe Flajolet
三、布隆过滤器
11、布隆过滤器,最常见的场景是商品推荐业务。例如购物时候浏览的信息被记录以后,可以进行推荐其他同类型的其他商品。推荐的其他商品不会和浏览过的商品重复(去重),但是也存在一定的误差。
布隆过滤器源地址链接:
https://github.com/RedisBloom/RedisBloom
先进行下载,下载方式可以按照自己喜欢的方式下载。例如此处我下载到d目录下的wesky/bloom文件夹下。

然后进入到文件夹内,使用make命令进行编译。编译成功的话,会产生一个 redisbloom.so的文件。如下,我也很尴尬,没成功,就暂且到这里吧。
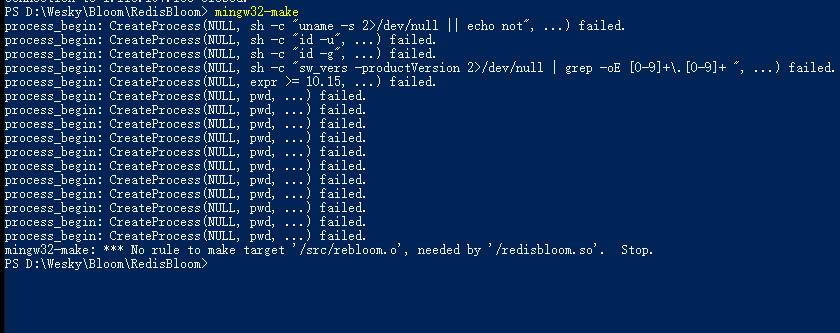
假如上面配置成功的话,启动redis服务的时候,可以把.so文件配置到redis.conf配置文件下,例如我上面所在的位置,新增的样式如下:
loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
或者使用命令启动的时候,使用命令进行指定:
redis-server --loadmodule D:/Wesky/Bloom/RedisBloom/redisbloom.so
由于当前我本机无法编译布隆过滤器源码,所以就暂且到这吧,请见谅。
布隆过滤器下,会有一些命令,供参考,大家可以根据自己情况,进行自己尝试,当作是留个悬念了。
命令:
bf.add key xxx
bf.madd key 数据1 数据2 ……
bf.exists key 数据
bf.mexists key 数据1 数据2 ……
……
今天是2022年的第一天,祝大家元旦快乐~~
【Redis的那些事 · 续集】Redis的位图、HyperLogLog数据结构演示以及布隆过滤器的更多相关文章
- 09 redis中布隆过滤器的使用
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容.问题来了,新闻客户端推荐系统如何实现推送去重的? 会想到服务器记录了用户看过的所有历史记录,当推 ...
- 关于Redis的那些事
1. MySql+Memcached架构的问题 Memcached采用客户端-服务器的架构,客户端和服务器端的通讯使用自定义的协议标准,只要满足协议格式要求,客户端Library可以用任何语言实现. ...
- 【Redis的那些事 · 上篇】Redis的介绍、五种数据结构演示和分布式锁
Redis是什么 Redis,全称是Remote Dictionary Service,翻译过来就是,远程字典服务. redis属于nosql非关系型数据库.Nosql常见的数据关系,基本上是以key ...
- redis持久化那些事(kēng)儿
这是一篇包含了介绍性质和吐槽性质的日志.主要介绍一下我学习redis持久化时候被坑的经历.redis的使用介绍现在没有打算写,因为比较多,以我如此懒的性格...好吧,还是有点这方面想法的,不过一篇博客 ...
- 第十章· Logstash深入-Logstash与Redis那点事
Logstash将日志写入Redis 为什么要使用Redis 在企业中,日志规模的量级远远超出我们的想象,这就是为什么会有一家公司日志易专门做日志收集,给大型金融公司收集日志,比如银行,因为你有可能看 ...
- Redis进阶实践之十一 Redis的Cluster集群搭建
一.引言 本文档只对Redis的Cluster集群做简单的介绍,并没有对分布式系统的详细概念做深入的探讨.本文只是提供了有关如何设置集群.测试和操作集群的说明,而不涉及Redis集群规范中涵 ...
- 【Redis】Redis学习(一) Redis初步入门
一.Redis基础知识 1.1 Redis简介 Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理.它支持字符串.哈希表.列表.集合.有序集合,位图,h ...
- Redis入门(二)-Redis能够做什么
引言 在上篇文章中,我们讲述了Redis的基本知识让读者对Redis有了基本的了解.那么这一节我们就来看一下Redis究竟能做什么. 上一节我们提到了Redis可用作数据库,高速缓存和消息队列代理.这 ...
- NoSql数据库Redis系列(1)——Redis简介
一.redis介绍 (一).Redis 简介 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库. Redis 与其他 key - value 缓存产品有以下三个特点 ...
随机推荐
- 大数据学习day39----数据仓库02------1. log4j 2. 父子maven工程(子spring项目的创建)3.项目开发(埋点日志预处理-json数据解析、清洗过滤、数据集成实现、uid回补)
1. log4j(具体见log4j文档) log4j是一个java系统中用于输出日志信息的工具.log4j可以将日志定义成多种级别:ERROR / WARN / INFO / DEBUG ...
- Oracle中常用的系统函数
本文主要来梳理下Oracle中的常用的系统函数,掌握这些函数的使用,对于我们编写SQL语句或PL/SQL代码时很有帮助,所以这也是必须掌握的知识点. 本文主要包括以下函数介绍:1.字符串函数2. 数值 ...
- Android获取通知栏的高度
1 public static int getStatusBarHeight(Context context){ 2 Class<?> c = null; 3 ...
- vue2 页面路由
vue官方文档 src/views/Login.vue <template> <div> <h2>登录页</h2> </div> </ ...
- jquery datatable真实示例
1 <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncodin ...
- Spring Boot中使用Servlet与Filter
在Spring Boot中使用Servlet,根据Servlet注册方式的不同,有两种使用方式.若使用的是Servlet3.0+版本,则两种方式均可使用:若使用的是Servlet2.5版本,则只能使用 ...
- java列表组件鼠标双击事件的实现
Swing中提供两种列表组件,分别是列表框(JList)和组合框(JComboBox). 一.JList组件 构造方法: public JList():构造一个空的.具有只读模型的JList.publ ...
- HDC2021技术分论坛:进程崩溃/应用卡死,故障频频怎么办?
作者:jiwenqiang,DFX技术专家 提到开发一个产品,我们通常首先想到的是要实现什么样的功能,但是除了功能之外,非功能属性也会很大程度上影响一个产品的体验效果,比如不定时出现的应用卡死.崩溃 ...
- 强化学习实战 | 表格型Q-Learning玩井子棋(三)优化,优化
在 强化学习实战 | 表格型Q-Learning玩井字棋(二)开始训练!中,我们让agent"简陋地"训练了起来,经过了耗费时间的10万局游戏过后,却效果平平,尤其是初始状态的数值 ...
- Mysql资料 查询条件
目录 一.计算 二.比较 三.逻辑运算符 四.位运算符 五.优先顺序 一.计算 二.比较 三.逻辑运算符 四.位运算符 五.优先顺序 实际上,很少有人能将这些优先级熟练记忆,很多情况下我们都是用&qu ...