自己动手写java 字节流输入输出流
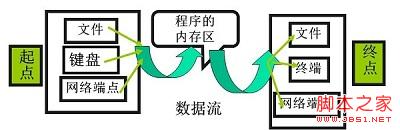
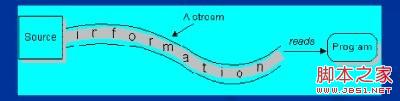
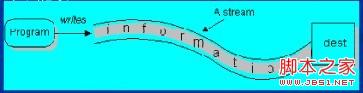
数据流是一串连续不断的数据的集合,就象水管里的水流,在水管的一端一点一点地供水,而在水管的另一端看到的是一股连续不断的水流。
“流是磁盘或其它外围设备中存储的数据的源点或终点。”
import java.io.IOException;
import java.io.InputStream; //字节数组输入流
public class MyByteInputStream extends InputStream { private byte[] buf;// 存放数据流的数组 private int bufLength;// 记录buf数组长度 private int pos;// 已经存放数据的下标位置 private int readPos = 0;// 记录当前数据流读取到的位置 public MyByteInputStream(int i) {
buf = new byte[32]; bufLength = 32;
pos = 0;
} // 构建输入流(直接存入待输入的流数据)
public MyByteInputStream(byte[] b) { if (b != null && b.length > 0) {
int copyLength = b.length;
buf = new byte[copyLength]; System.arraycopy(b, 0, buf, 0, copyLength);// 复制数组内容 bufLength = copyLength;
pos = copyLength;
} else {
buf = new byte[32]; bufLength = 32;
pos = 0;
}
} /*
* 若有数据则返回对应buf[readPos],否则返回-1
*/
public int read() throws IOException {
if (pos > 0 && readPos <= (pos - 1)) {
readPos = readPos + 1; return buf[readPos - 1];
} return -1;
} }
2.输出流代码
import java.io.OutputStream;
public class MyByteOutStream extends OutputStream {
private byte[] buf;// 输出流
private int length;// 存放输出流的长度
private int pos;// 写到的位置
public MyByteOutStream() {
buf = new byte[32];
length = 32;
pos = 0;
}
public MyByteOutStream(int size) {
if (size > 0) {
buf = new byte[size];
length = size;
pos = 0;
} else {
buf = new byte[32];
length = 32;
pos = 0;
}
}
/**
* 将字符b写入到字节流中,若流空间不够则扩展
*
* @param b
*/
public void write(int b) {
if (pos < length) {
buf[pos] = (byte) b;
pos = pos + 1;
} else {
// TODO:扩展字节流buf[]大小
}
}
/**
* 将输出流copy
*
* @return
*/
public byte[] toByteArray() {
if (pos > 0) {
byte[] b = new byte[pos];
System.arraycopy(buf, 0, b, 0, pos);
return b;
}
return null;
}
}
3.测试类
import java.io.IOException;
public class MyTest {
public static void main(String[] args) {
String inputStr = "Test input stream!";
String outStr = "Test out strem!";
// 自定义输入流
MyByteInputStream myByteInputStream = new MyByteInputStream(inputStr.getBytes());
try {
for (int i; (i = myByteInputStream.read()) != -1;) {
System.out.print(Character.toString((char) i));
}
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("");
// 自定义输出流
MyByteOutStream myByteOutStream = new MyByteOutStream(100);
byte[] b = outStr.getBytes();
for (int i = 0; i < b.length; i++) {
myByteOutStream.write(b[i]);
}
byte[] outb = myByteOutStream.toByteArray();
for (int i = 0; i < outb.length; i++) {
System.out.print(Character.toString((char) outb[i]));
}
System.out.println("");
}
}
ps:欢迎各位吐槽指点~
自己动手写java 字节流输入输出流的更多相关文章
- [JVM] - 一份<自己动手写Java虚拟机>的测试版
go语言下载 配置GOROOT(一般是自动的),配置GOPATH(如果想自己改的话) 参照<自己动手写Java虚拟机> > 第一章 指令集和解释器 生成了ch01.exe文件 这里还 ...
- 自己动手写Java大整数《3》除法和十进制转换
之前已经完毕了大整数的表示.绝对值的比較大小.取负值.加减法运算以及乘法运算. 详细见前两篇博客(自己动手写Java * ). 这里加入除法运算. 另外看到作者Pauls Gedanken在blog( ...
- java:利用java的输入/输出流将一个文件的每一行+行号复制到一个新文件中去
import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.Fi ...
- Java:输入输出流 java.io包的层次结构
1.什么是IO Java中I/O操作主要是指使用Java进行输入,输出操作. Java所有的I/O机制都是基于数据流进行输入输出,这些数据流表示了字符或者字节数据的流动序列.Java的I/O流提供了读 ...
- JAVA基础-输入输出流
一,File类:文件的创建和删除 1.File(String pathname):pathname是指路径名称.用法 File file = new File("d:/1.txt " ...
- Java基础—输入输出流
流的概念 在Java中,流是从源到目的地的字节的有序序列.Java中有两种基本的流——输入流(InputStream)和输出流(OutputStream). 根据流相对于程序的另一个端点的不同,分为节 ...
- java.IO输入输出流:过滤流:buffer流和data流
java.io使用了适配器模式装饰模式等设计模式来解决字符流的套接和输入输出问题. 字节流只能一次处理一个字节,为了更方便的操作数据,便加入了套接流. 问题引入:缓冲流为什么比普通的文件字节流效率高? ...
- 浅谈Java的输入输出流(转)
Java语言的输入输出功能是十分强大而灵活的,美中不足的是看上去输入输出的代码并不是很简洁,因为你往往需要包装许多不同的对象.在Java类库中,IO部分的内容是很庞大的,因为它涉及的领域很广泛:标准输 ...
- java 对象输入输出流
对象的输入输出流的作用: 用于写入对象 的信息读取对象的信息. 对象的持久化. 比如:用户信息. ObjectInputStream : 对象输入流 ...
随机推荐
- 存储结构比较vector,list,dequeue,stack(转)
vector适用:对象数量变化少,简单对象,随机访问元素频繁list适用:对象数量变化大,对象复杂,插入和删除频繁最大的区别是,list是双向的,而vector是单向的.因此在实际使用时,如何 ...
- ueditor编辑器使用总结
ueditor使用小结 一.简介 ueditor是百度编辑器,官网地址:http://ueditor.baidu.com/website/ 完整的功能演示,可以参考:http://ueditor.ba ...
- Flunetd 用于统一日志记录层的开源数据收集器
传统的日志查看方式 使用fluentd之后 一.介绍 Fluentd是一个开源的数据收集器,可以统一对数据收集和消费,以便更好地使用和理解数据. 几大特色: 使用JSON统一记录 简单灵活可插拔架构 ...
- Hibernate的系统 学习
Hibernate的系统 学习 一.Hibernate的介绍 1.什么是Hibernate? 首先,hibernate是数据持久层的一个轻量级框架.数据持久层的框架有很多比如:iBATIS,myBat ...
- LoadRunner性能测试-loadrunner事务
事务(Transaction): 简单来说就是用来模拟用户的一个相对完整的业务过程.添加事务,是用来衡量响应时间的重要方法.我们可以通过事务计时来对不同压力负载下的性能指标进行对比. 插入事务的方法: ...
- 7. leetcode 104. Maximum Depth of Binary Tree
Given a binary tree, find its maximum depth. The maximum depth is the number of nodes along the long ...
- mbos之动态图表设计
前言 所谓,一图胜千言.人脑有80%的部分专门用于视觉处理.而随着数据时代的全面来临,我们自然有必要将数据转化为图形与图表. Mbos是一个快速,稳定的云端轻应用开发平台.帮助企业快速开发移动应用,加 ...
- NYOJ--45--棋盘覆盖(大数)
棋盘覆盖 时间限制:3000 ms | 内存限制:65535 KB 难度:3 描述 在一个2k×2k(1<=k<=100)的棋盘中恰有一方格被覆盖,如图1(k=2时),现用一缺角的 ...
- centos7用户,组及文件权限管理
centos7安装过程中如果没有创建用户的话,默认只有ROOT用户,这个用户是具有最高权限的帐户,可以做任何事情,但实际生产环境中我们一般不会使用这个用户,因为权限太大了,很危险. 所以在生产环境中就 ...
- spring-session实现分布式集群session的共享
前言 HttpSession是通过Servlet容器创建和管理的,像Tomcat/Jetty都是保存在内存中的.但是我们把应用搭建成分布式的集群,然后利用LVS或Nginx做负载均衡,那么来自同一用户 ...