Unicode 与 Unicode Transformation Format(UTF,UTF-8 / UTF-16 / UTF-32)
- ASCII(American Standard Code for Information Interchange):早期它使用7 bits来表示一个字符,总共表示27 = 128个字符;后来扩展到8 bits,即用一个字节来表示一个字符,总共表示28 = 256个字符,这种ASCII扩展字符集如IBM字符集和ISO Latin-1,首位为1(128~255)的编码区域表示扩展字符
- Unicode:由于ASCII字符集总数有限且只适用于欧洲语言国家,不同语言体系的国家要统一使用同一种字符集,就需要一种更大的字符集。Unicode早期采用2个字节编码,总共可表示216 = 65536个字符,它通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符;然而,可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format),如UTF-8、UTF-16、UTF-32。Universal Character Set(UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集,UCS-2用两个字节编码,UCS-4用4个字节编码。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码,以保持两者兼容。Unicode计划使用17个平面(Plane,包含216 = 65536个码位。Plane 0被称为Basic Multilingual Plane),一共有17×65536=1114112个码位(0~1114111)。ISO承诺ISO 10646将不会替超出U+10FFFF(1114111)的UCS-4编码赋值,以使得两者保持一致
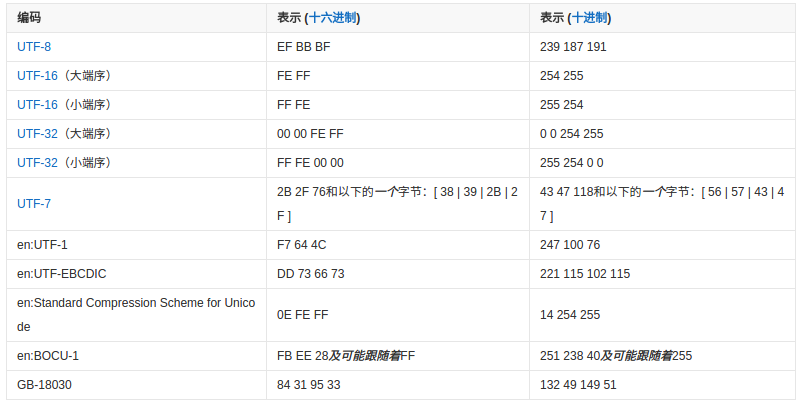
- BOM(Byte Order Mark,字节顺序标记):特殊字符U+FEFF叫做 "Zero Width No-Break Space" ,中文译作“零宽无间断间隔”的字符,实际不会出现在正常字节流中。但在传输字节流前,先传输字符 "Zero Width No-Break Space",如果收到FFFE,就表明这个字节流是 Little- Endian (小端序、小字节序、低字节序、小尾序,即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端)的;如果收到 FEFF,就表明这个字节流是 Big-Endian (大端序,字节顺序与 Little- Endian 刚好相反)的。因此字符 "Zero Width No-Break Space" 又被称作 BOM,它将出现在文本文件头部,表明文件的编码方式。UTF-8 虽是字节顺序无关的,但仍然可以用 BOM (EF BB BF)来表明其编码方式。下图展示了编码方式与BOM的对应关系:
PHP并不会忽略UTF-8文件的BOM,所以在读取、包含或者引用这些文件时,会把BOM作为该文件开头正文的一部分。因此,PHP文件采用UTF-8编码时可保存无BOM格式。
如果U+FEFF出现在数据流中,该怎么办呢?下面这段来自Wikipedia,关于Word Joiner(WJ, U+2060):
The word joiner replaces the zero-width no-break space (ZWNBSP), a deprecated use of the Unicode character at code point U+FEFF. Character U+FEFF is intended for use as a Byte Order Mark at the start of a file. However, if encountered elsewhere it should, according to Unicode, be treated as a "zero-width non-breaking space." The deliberate use of U+FEFF for this purpose is deprecated as of Unicode 3.2, with the word joiner strongly preferred.
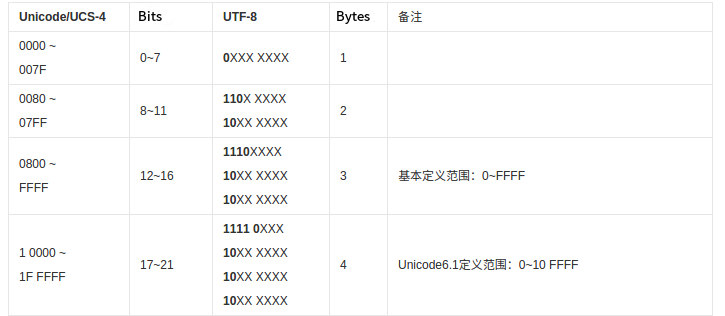
- UTF-8(万国码):它是可变长编码,即用1~4个字节来编码Unicode字符集。其与Unicode的转换关系如下:
另外,以下部分非Unicode编码范围,属于UCS-4 编码早期的规范:

UTF-8用1个字节(U+0000~U+007F)来编码所有ASCII字符,并且与ASCII字符表示是一样的,故其与ASCII兼容,而那些ISO Latin-1扩展ASCII字符集的字符(128~255)是Unicode的子集,但不是UTF-8的子集;其他的字符UTF-8编码将需要2~4个字节,首字节连续的1的个数表示字符编码所需的字节数。“编”的Unicode编码是U+7F16,因此UTF-8需要3个字节来表示,形如1110xxxx 10xxxxxx 10xxxxxx这种格式。
由于UTF-8采用的是变长字符编码,与UTF-16和UTF-32相比,无论是计算字符数,还是执行索引操作效率都不高,因此UTF-8适合在传输数据中使用,可在数据接收完毕后将其转换为UTF-16或UTF-32进行处理,最后再转换回UTF-8(但这转换本身也会有性能损耗);但UTF-8空间足够大,无字节序问题,且容错性高,局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来。另外,utf8mb4是utf8的一个超集,支持最多4个字节来表示一个字符,如emoji表情字符就占用4个字节。
- UTF-16:以2个字节16bits为编码基本单位。假设U代表字符的Unicode编码,如果U < 0x10000且U∉[0xD800,0xDFFF],U的UTF-16编码就是U对应的16位无符号整数(0x00000~0xFFFF,除去0xD800-0xDFFF作为BMP的代理区部分);如果U ≥ 0x10000,则使U' = U - 0x10000(最大为0x10FFFF - 0x10000 = 0xFFFFF),然后将U'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码二进制表示就是:110110yyyyyyyyyy(0xD800~0xDBFF) 110111xxxxxxxxxx(0xDC00~0xDFFF)。由此可见,Unicode字符的UTF-16表示要么是2个字节长度,要么是4个字节长度,为将二者区分开来、防止冲突,设计者将0xD800-0xDFFF保留下来,称代理区(Surrogate):

High Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节;Low Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的后两个字节;High Private Use Surrogates是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节,但该Unicode字符属于平面15和平面16这两个专用区 - UTF-32:用4个字节32bits来编码一个Unicode字符,Unicode的UTF-32编码就是其对应的32位无符号整数
- 更多信息参考链接:http://www.unicode.org/faq/utf_bom.html
Unicode 与 Unicode Transformation Format(UTF,UTF-8 / UTF-16 / UTF-32)的更多相关文章
- Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)
ASCII(American Standard Code for Information Interchange):早期它使用7 bits来表示一个字符,总共表示27 = 128个字符:后来扩展到8 ...
- 细说Unicode(一) Unicode初认识
https://segmentfault.com/a/1190000007992346 细说Unicode(一) Unicode初认识 网站开发中经常会被乱码问题困扰.知道文件编码错误会导致乱码,但对 ...
- Ansi、GB2312、GBK、Unicode(utf8、16、32)
关于ansi,一般默认为本地编码方式,中文应该是gb编码 他们之间的关系在这边文章里描写的很清楚:http://blog.csdn.net/ldanduo/article/details/820353 ...
- js 中文汉字转Unicode、Unicode转中文汉字、ASCII转换Unicode、Unicode转换ASCII、中文转换&#XXX函数代码
最近看不少在线工具里面都有一些编码转换的代码,很多情况下我们都用得到,这里脚本之家小编就跟大家分享一下这些资料 Unicode介绍 Unicode(统一码.万国码.单一码)是一种在计算机上使用的字符编 ...
- 杂项-Unicode:Unicode
ylbtech-杂项-Unicode:Unicode Unicode(统一码.万国码.单一码)是计算机科学领域里的一项业界标准,包括字符集.编码方案等.Unicode 是为了解决传统的字符编码方案的局 ...
- java 中文转Unicode 以及 Unicode转中文
package com.sun; public class Snippet { public static void main(String[] args) { String cn ...
- .net C#实现 中文转Unicode、Unicode转中文 及与js对应关系
中文转Unicode:HttpUtility.UrlEncodeUnicode(string str); 转换后中文格式:"%uxxxx" 举例:"柳_abc123&q ...
- unicode和unicode编码
unicode编码是什么? 这其实是两个问题,unicode 是什么什么?unicode是怎样编码的? What is Unicode? Unicode provides a unique numbe ...
- utf 8无bom和utf 8什么区别
今天在上传CSV文件的时候,Windows下调试一切正常.妈的一到Linux下面,就出现问题,第一行数据总是读取不出来, 利用print_r()打印出读取文件的内容,发现有一个很奇怪的字符在作怪.为什 ...
随机推荐
- 源码安装zabbix_server服务端
按照上一篇安装lnmp环境:http://www.cnblogs.com/armo/p/6067716.html 保证lnmp正常运行,然后安装zabbix_server 安装依赖 yum -y in ...
- [leetcode-623-Add One Row to Tree]
Given the root of a binary tree, then value v and depth d, you need to add a row of nodes with value ...
- [leetcode-594-Longest Harmonious Subsequence]
We define a harmonious array is an array where the difference between its maximum value and its mini ...
- 第一章:windows下 python 的安装和使用
1. 主流的python版本和大部分人使用的版本都是 2.7 和3.6 2.安装 python2.7 和 python3.6的步骤 1. 下载 python对应的版本:选择使用的 系统, 64位和32 ...
- java基础系列--Calendar类
原创作品,可以转载,但是请标注出处地址:http://www.cnblogs.com/V1haoge/p/7136575.html 1.Calendar概述 Java官方推荐使用Calendar来替换 ...
- webpack初步介绍
我们通过npm -g可以安装一个webpack的东西. npm -g叫做全局安装,通常是安装CLI程序(commond line interface). 我们只用过一次,装了cnpm.此时就能在CMD ...
- Interlocked原子函数陷阱
一.问题 windows api函数中提供了InterlockedExchange.InterlockedDecrement, InterlockedIncrement, ExInterlockedA ...
- Python之MRO及其C3算法
[<class '__main__.B'>, <class '__main__.A'>, <class 'object'>] (<class '__main_ ...
- [补] winpcap编程——EAP协议与EAPSOCKET实现
EAP SOCKET Implement Mentohust 时间:20161115,大二上 ## 准备. 什么是 EAP 协议 ? WIKI : https://en.wikipedia.org/w ...
- Spring源码情操陶冶-AbstractApplicationContext
前言-阅读源码有利于陶冶情操,本文承接前文Spring源码情操陶冶-ContextLoader 约束:本文指定contextClass为默认的XmlWebApplicationContext Abst ...