MapReduce 入门之一步步自实现词频统计功能
原创播客,如需转载请注明出处。原文地址:http://www.cnblogs.com/crawl/p/7687120.html
----------------------------------------------------------------------------------------------------------------------------------------------------------
笔记中提供了大量的代码示例,需要说明的是,大部分代码示例都是本人所敲代码并进行测试,不足之处,请大家指正~
本博客中所有言论仅代表博主本人观点,若有疑惑或者需要本系列分享中的资料工具,敬请联系 qingqing_crawl@163.com
-----------------------------------------------------------------------------------------------------------------------------------------------------------
前言:这一个月实在是抽不出空来写博客了,最近在为学校开发网上办事大厅,平时还要上课,做任务,很忙,压力也很大,终于在本月的最后一天抽出了点时间。其实,这一篇播客一直在我的草稿箱中,楼主本来想先仔细写一写 Hadoop 伪分布式的部署安装,然后介绍一些 HDFS 的内容再来介绍 MapReduce,是在是没有抽出空,今天就简单入门一下 MapReduce 吧。
一、MapReduce 概述
1.MapReduce 是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
2.MapReduce 由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算
二、具体实现
1.先来看一下 Eclipse 中此应用的包结构

2.创建 map 的任务处理类:WCMapper
/*
* 1.Mapper 类的四个泛型中,前两个指定 mapper 输入数据的类型,后两个指定 mapper 输出数据的类型
* KEYIN 是输入的 key 的类型,VALUEIN 是输入的 value 的类型
* KEYOUT 是输出的 key 的类型,VALUEOUT 是输出的 value 的类型
* 2.map 和 reduce 的数据的输入输出都是以 key-value 对的形式封装的
* 3.默认情况下,框架传递给我们的 mapper 的输入数据中,key 是要处理的文本中一行的起始偏移量,为 Long 类型,
* 这一行的内容为 value,为 String 类型的
* 4.后两个泛型的赋值需要我们结合实际情况
* 5.为了在网络中传输时序列化更高效,Hadoop 把 Java 中的 Long 封装为 LongWritable, 把 String 封装为 Text
*/
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> { //重写 Mapper 中的 map 方法,MapReduce 框架每读一行数据就调用一次此方法
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//书写具体的业务逻辑,业务要处理的数据已经被框架传递进来,就是方法的参数中的 key 和 value
//key 是这一行数据的起始偏移量,value 是这一行的文本内容 //1.将 Text 类型的一行的内容转为 String 类型
String line = value.toString(); //2.使用 StringUtils 以空格切分字符串,返回 String[]
String[] words = StringUtils.split(line, " "); //3.循环遍历 String[],调用 context 的 writer()方法,输出为 key-value 对的形式
//key:单词 value:1
for(String word : words) {
context.write(new Text(word), new LongWritable(1));
} } }
2.创建 reduce 的任务处理类:WCReducer:
/*
* 1.Reducer 类的四个泛型中,前两个输入要与 Mapper 的输出相对应。输出需要联系具体情况自定义
*/
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> { //框架在 map 处理完之后,将所有的 kv 对缓存起来,进行分组,然后传递一个分组(<key,{values}>,例如:<"hello",{1,1,1,1}>),
//调用此方法
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)throws IOException, InterruptedException { //1.定义一个计数器
long count = 0; //2.遍历 values的 list,进行累加求和
for(LongWritable value : values) {
//使用 LongWritable 的 get() 方法,可以将 一个 LongWritable 类型转为 Long 类型
count += value.get();
} //3.输出这一个单词的统计结果
context.write(key, new LongWritable(count));
} }
3.创建一个类,用来描述一个特定的作业:WCRunner,(此类了楼主没有按照规范的模式写)
/**
* 此类用来描述一个特定的作业
* 例:1.该作业使用哪个类作为逻辑处理中的 map,哪个作为 reduce
* 2.指定该作业要处理的数据所在的路径
* 3.指定该作业输出的结果放到哪个路径
*/
public class WCRunner { public static void main(String[] args) throws Exception { //1.获取 Job 对象:使用 Job 静态的 getInstance() 方法,传入 Configuration 对象
Configuration conf = new Configuration();
Job wcJob = Job.getInstance(conf); //2.设置整个 Job 所用的类的 jar 包:使用 Job 的 setJarByClass(),一般传入 当前类.class
wcJob.setJarByClass(WCRunner.class); //3.设置本 Job 使用的 mapper 和 reducer 的类
wcJob.setMapperClass(WCMapper.class);
wcJob.setReducerClass(WCReducer.class); //4.指定 reducer 输出数据的 kv 类型 注:若 mapper 和 reducer 的输出数据的 kv 类型一致,可以用如下两行代码设置
wcJob.setOutputKeyClass(Text.class);
wcJob.setOutputValueClass(LongWritable.class); //5.指定 mapper 输出数据的 kv 类型
wcJob.setMapOutputKeyClass(Text.class);
wcJob.setMapOutputValueClass(LongWritable.class); //6.指定原始的输入数据存放路径:使用 FileInputFormat 的 setInputPaths() 方法
FileInputFormat.setInputPaths(wcJob, new Path("/wc/srcdata/")); //7.指定处理结果的存放路径:使用 FileOutputFormat 的 setOutputFormat() 方法
FileOutputFormat.setOutputPath(wcJob, new Path("/wc/output/")); //8.将 Job 提交给集群运行,参数为 true 表示显示运行状态
wcJob.waitForCompletion(true); } }
4.将此项目导出为 jar 文件
步骤:右击项目 ---> Export ---> Java ---> JAR file --->指定导出路径(我指定的为:e:\wc.jar) ---> Finish
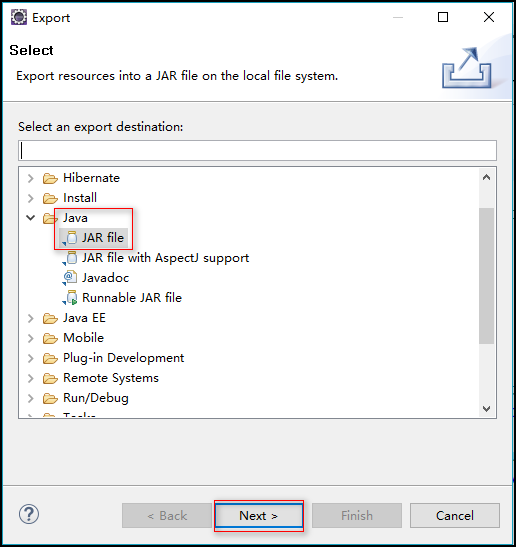
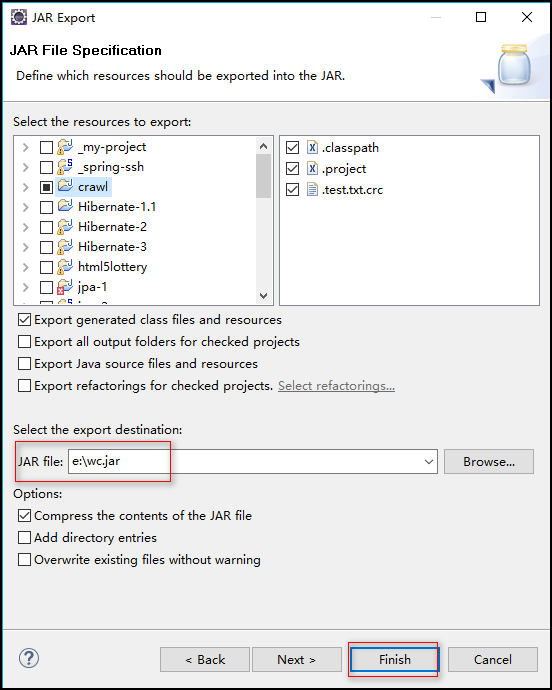
5.将导出的 jar 包上传到 linux 上
楼主使用的方法是:在 SecureCRT 客户端中使用 Alt + p 快捷键打开上传文件的终端,输入 put e"\wc.jar 即可上传

6.创建初始测试文件:words.log
命令: vi words.log 自己输入测试数据即可

7.在 hdfs 中创建存放初始测试文件 words.log 的目录:我们在 WCRunner 中指定的是 /wc/srcdata/
命令:
[hadoop@crawl ~]$ hadoop fs -mkdir /wc
[hadoop@crawl ~]$ hadoop fs -mkdir /wc/srcdata
8.将初始测试文件 words.log 上传到 hdfs 的相应目录
命令:[hadoop@crawl ~]$ hadoop fs -put words.log /wc/srcdata
9.运行 jar 文件
命令:hadoop jar wc.jar com.software.hadoop.mr.wordcount.WCRunner
此命令为 hadoop jar wc.jar 加上 WCRunner类的全类名,程序的入口为 WCRunner 内的 main 方法,运行完此命令便可以看到输出日志信息:
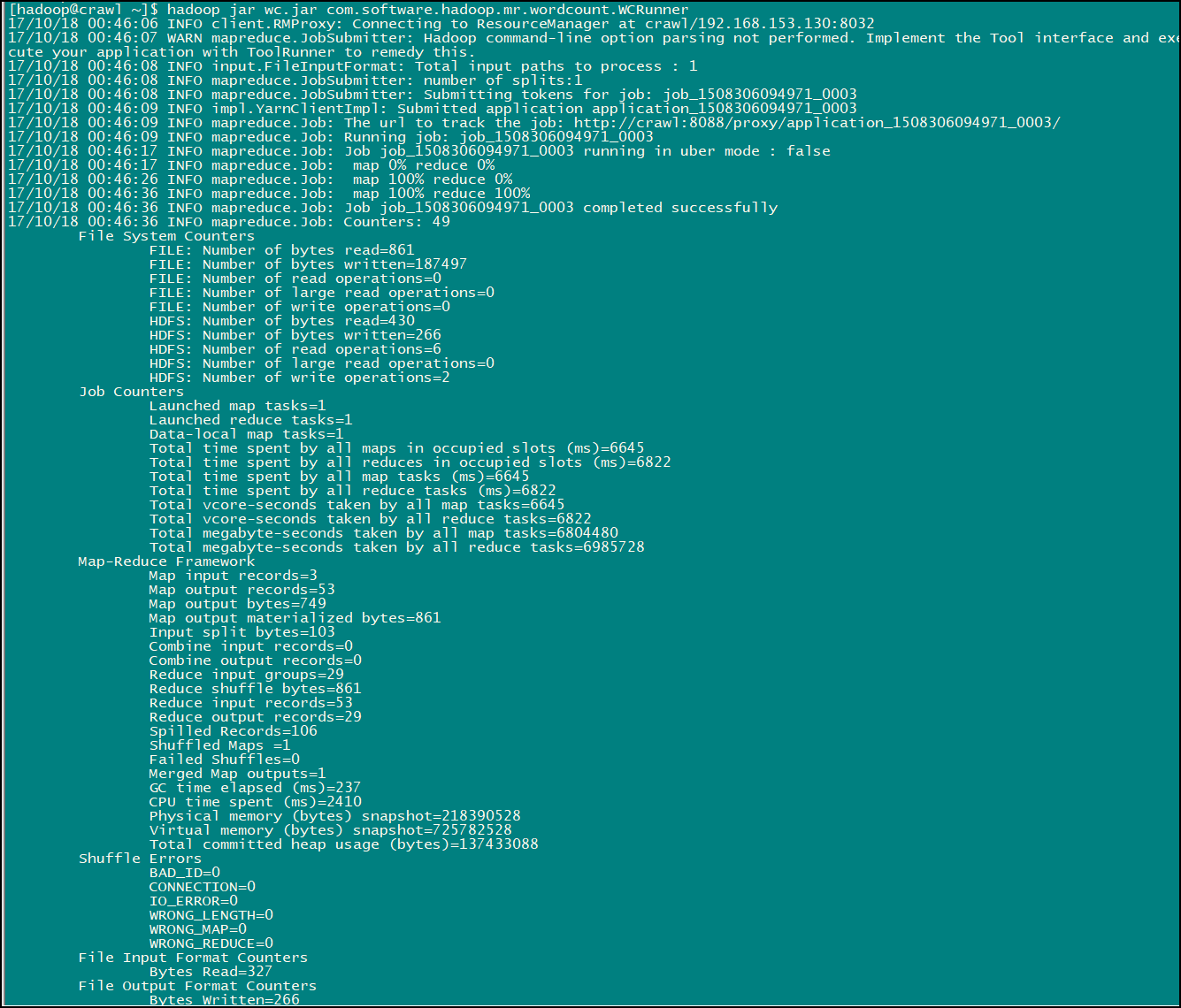
然后前去我们之前配置的存放输出结果的路径(楼主之前设置的为:/wc/output/)就可以看到 MapReduce 的执行结果了
输入命令:hadoop fs -ls /wc/output/ 查看以下 /wc/output/ 路径下的内容

结果数据就在第二个文件中,输入命令:hadoop fs -cat /wc/output/part-r-00000 即可查看:

至此我们的这个小应用就完成了,是不是很有意思的,楼主在实现的时候还是发生了一点小意外:
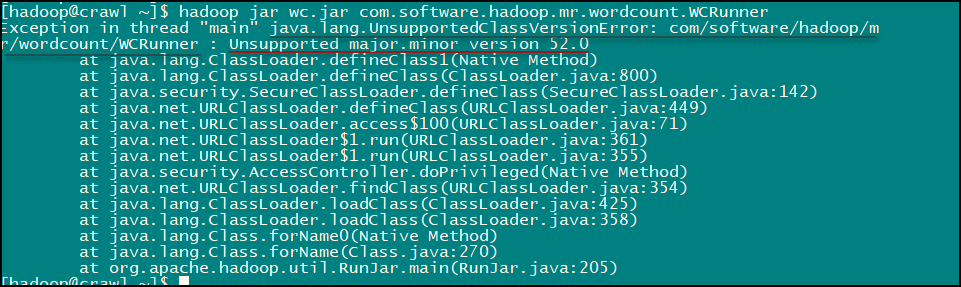
楼主查阅资料发现这是由于 jdk 版本不一致导致的错误,统一 jdk 版本后便没有问题了。
MapReduce 入门之一步步自实现词频统计功能的更多相关文章
- Java实现的词频统计——功能改进
本次改进是在原有功能需求及代码基础上额外做的修改,保证了原有的基础需求之外添加了新需求的功能. 功能: 1. 小文件输入——从控制台由用户输入到文件中,再对文件进行统计: 2.支持命令行输入英文作品的 ...
- awk词频统计功能
[root@test88 ~]# vim word_freq.sh #!/bin/bash if [ $# -ne 1 ];then echo "Usage: $0 filename&quo ...
- 使用HDFS完成wordcount词频统计
任务需求 统计HDFS上文件的wordcount,并将统计结果输出到HDFS 功能拆解 读取HDFS文件 业务处理(词频统计) 缓存处理结果 将结果输出到HDFS 数据准备 事先往HDFS上传需要进行 ...
- 如何用java完成一个中文词频统计程序
要想完成一个中文词频统计功能,首先必须使用一个中文分词器,这里使用的是中科院的.下载地址是http://ictclas.nlpir.org/downloads,由于本人电脑系统是win32位的,因此下 ...
- 软工之词频统计器及基于sketch在大数据下的词频统计设计
目录 摘要 算法关键 红黑树 稳定排序 代码框架 .h文件: .cpp文件 频率统计器的实现 接口设计与实现 接口设计 核心功能词频统计器流程 效果 单元测试 性能分析 性能分析图 问题发现 解决方案 ...
- 使用Storm进行词频统计
词频统计 1.需求:读取指定目录的数据,并且实现单词计数功能 2.实现方案: Spout用于读取指定文件夹(目录),读取文件,将文件的每一行发射到Bolt SplitBolt用于接收Spout发射过来 ...
- MapReduce词频统计
自定义Mapper实现 import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; impor ...
- MapReduce实现词频统计
问题描述:现在有n个文本文件,使用MapReduce的方法实现词频统计. 附上统计词频的关键代码,首先是一个通用的MapReduce模块: class MapReduce: __doc__ = ''' ...
- map-reduce入门
map-reduce入门 近期在改写mahout源代码,感觉自己map-reduce功力不够深厚,因此打算系统学习一下. map-reduce事实上是一种编程范式,从统计词频(wordCount)程序 ...
随机推荐
- UWP appButtonBar样式
UWP 的appButtonBar使用<AppBarButton Icon = "Next" Label = "Next" /> Icon是 Sym ...
- win10 uwp 如何拖动一个TextBlock的文字到另一个TextBlock
我在堆栈网看到有人问 如何拖动一个TextBlock的文字到另一个TextBlock 于是看到一个大神给出的方法,下面我就来和大家说下如何拖动 一开始我们需要一个界面,就放两个TextBlock 一个 ...
- win10 UWP 全屏
win10 可以全屏软件或窗口,窗口有一般.最小化.最大化.我们有新的API设置我们软件是全屏,是窗口.我们可以使用ApplicationView让我们软件全屏,取消. 下面是一个简单的例子,判断我们 ...
- eclipse环境下,java操作MySQL的简单演示
首先先通过power shell 进入MySQL 查看现在数据库的状态(博主是win10系统) 右键开始,选择Windows powershell ,输入MySQL -u用户名 -p密码 选择数据库( ...
- 怎么样防止Sql注入
(1)对于动态构造SQL查询的场合,可以使用下面的技术: 第一:替换单引号,即把所有单独出现的单引号改成两个单引号,防止攻击者修改SQL命令的含义.再来看前面的例子,“SELECT * from Us ...
- eclipse远程调试Linux环境下的web项目
前提: 远程服务器上的代码和本地的代码同步 第一步 : 配置远程服务器下的startup.sh文件 在第一行添加 : declare -x CATALINA_OPTS="-server -X ...
- C#,COM口,接收,发送数据
这里写一种,COM口的数据接收,发送方法. 1.COMHelper类 /// <summary>初始化串行端口</summary> private SerialPort _se ...
- 优先队列(存储结构数组)--Java实现
/*优先队列--是对队列的一种改进 *要存储的数据存在优先级--数值小的优先级高--在队头 *优先队列的实现 *1.数组:适合数据量小的情况(没有用rear+front实现) *优先队列头在items ...
- Appium python自动化测试系列之等待函数如何进行实战(九)
9.1 等待函数的使用 9.1.1 为什么要使用等待函数 我们在做自动化的时候很多时候都不是很顺利,不是因为app的问题,我们的脚本也没问题,但是很多时候都会报错,比如一个页面本来就有id为1的这个 ...
- 【机器学习】支持向量机(SVM)
感谢中国人民大学胡鹤老师,课程深入浅出,非常好 关于SVM 可以做线性分类.非线性分类.线性回归等,相比逻辑回归.线性回归.决策树等模型(非神经网络)功效最好 传统线性分类:选出两堆数据的质心,并做中 ...