Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
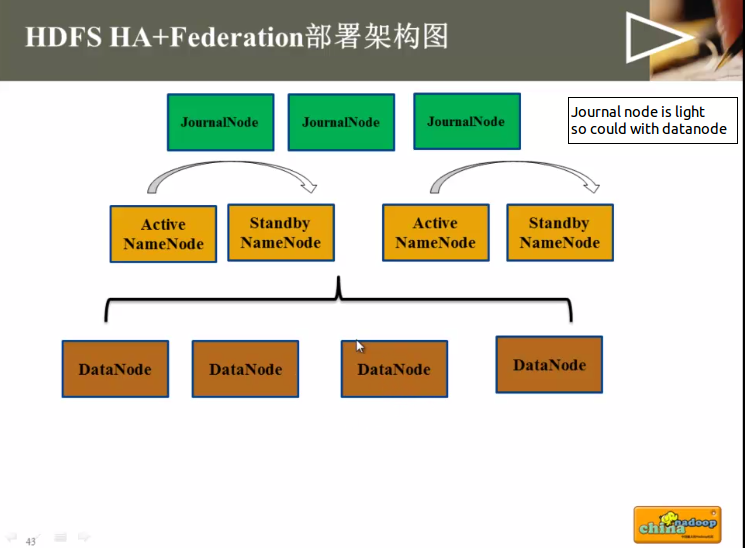
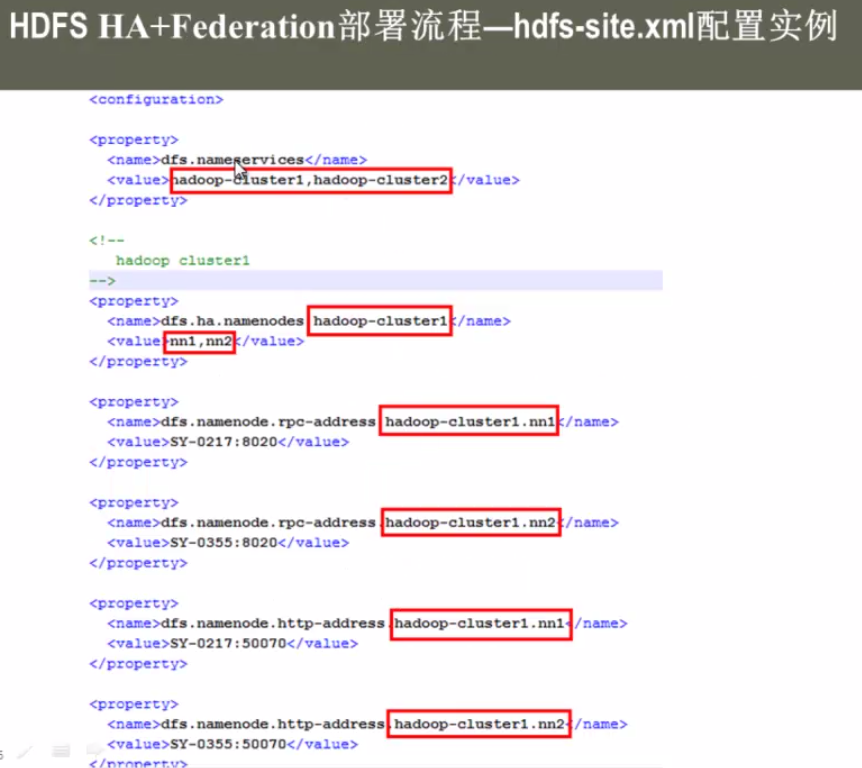

其他的配置跟HDFS-HA部署方式完全一样。但JournalNOde的配置不一样
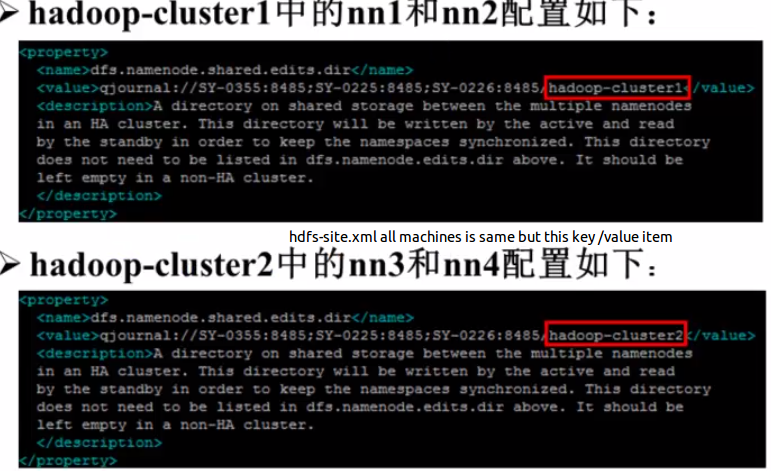
》hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的journalnode但dfs.namenode.shared.edits.dir配置不能相同。
hadoop-cluster1中的nn1和nn2配置如下:
hdfs ha federation启动/关闭流程
在nn1,nn2两个节点上如下操作
step1:在各个journalnode上,启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
step2:在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format -clusterId hadoop-cluster
sbin/hadoop-daemon.sh start namenode
step3:在[nn2]上,同步[nn1]的元数据信息
bin/hdfs namenode -bootstrapStandby
step4:在[nn2],启动Namenode:
sbin/hadoop-daemon.sh start namenode
(经过以上四步,nn1和nn2均处于standby状态)
step5:在[nn1]上,将NameNode切换为active
bin/hdfs haadmin -ns hadoop-cluster1 -transitionToActive nn1 [-ns 指定命名服务 在dfs.nameservices中指定了]

最后:在nn1上,启动所有datanode
sbin/hadoop-daemon[s].sh start datanode 依次看4个50070节点就行。有两个active ,两个standby
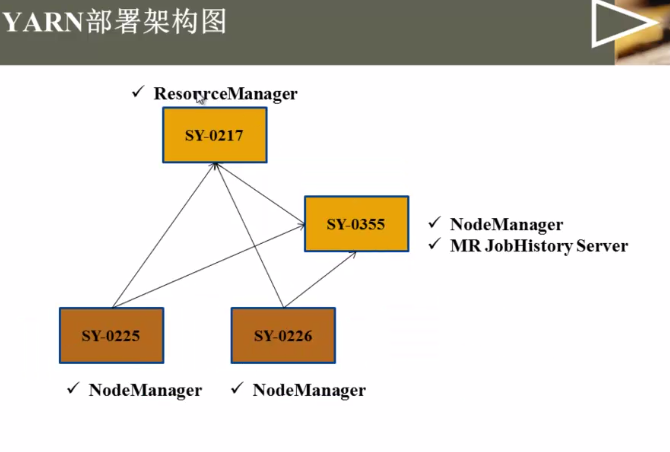
选一个作为rsourcemanager就行,其他作为nodemanager


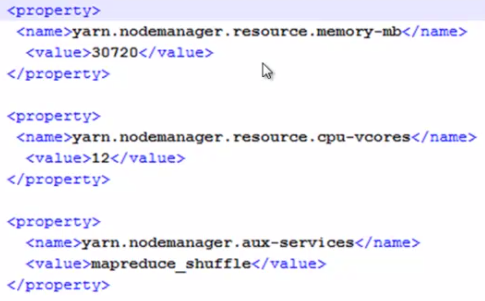
memory-mb与cpu-vcores:告诉resourcemanager我有多少资源可供使用,比方namenode上有20G内存供yarn使用,12个核,可以配置15G的内存,6个核供yarn使用。剩余的给hdfs或其他服务使用 fairscheduler.xml的配置实例:
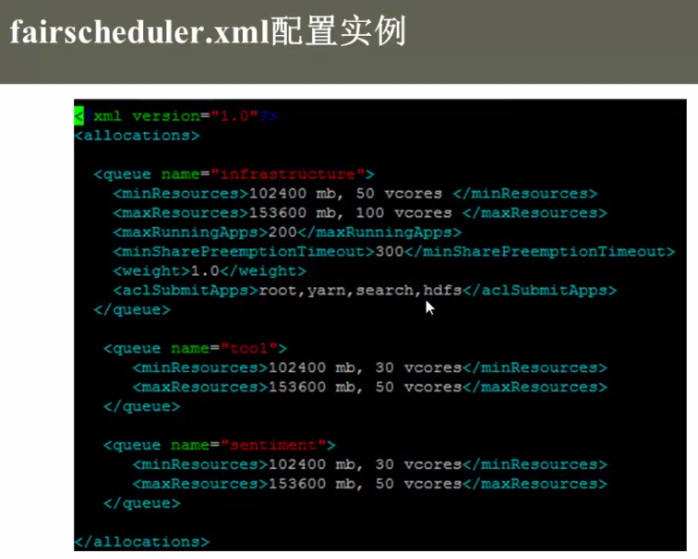
aclSubmitApps 指定了只有哪些用户可以使用这个队列。
mapred-site.xml

在sy-0217上启动yarnsbin/start-yarn.sh
停止:
sbin/stop-yarn.sh
在sy-0355上启动MR JOb history server:
sbin/mr-jobhistory-daemon.sh start historyserver (可以在命令行下查看所有mr历史任务,默认一个程序过去后他的一些历史数据就看不到了 )
Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署的更多相关文章
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压 step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建) 包括 ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- hadoop 学习笔记 (十) mapreduce2.0
MapReduce的特色---不擅长的方面 >实时计算 像mysql一样,在毫秒级或者秒级内返回结果 >流式计算 Mapreduce的输入数据时静态的,不能动态变化 MapReduce自身 ...
- Hadoop学习笔记—21.Hadoop2的改进内容简介
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更: (1)HDFS的NameNod ...
- hadoop学习笔记(五):java api 操作hdfs
HDFS的Java访问接口 1)org.apache.hadoop.fs.FileSystem 是一个通用的文件系统API,提供了不同文件系统的统一访问方式. 2)org.apache.hadoop. ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- hadoop学习笔记(二):centos7三节点安装hadoop2.7.0
环境win7+vamvare10+centos7 一.新建三台centos7 64位的虚拟机 master node1 node2 二.关闭三台虚拟机的防火墙,在每台虚拟机里面执行: systemct ...
- Hadoop学习笔记(两)设置单节点集群
本文描写叙述怎样设置一个单一节点的 Hadoop 安装.以便您能够高速运行简单的操作,使用 Hadoop MapReduce 和 Hadoop 分布式文件系统 (HDFS). 參考官方文档:Hadoo ...
随机推荐
- C# 动态创建出来的窗体间的通讯 delegate3
附件1:http://files.cnblogs.com/xe2011/CSharp_WindowsForms_delegate03.rar 一个RTF文件管理器 描述 Form2,Form3,For ...
- 第三篇——第二部分——第五文 配置SQL Server镜像——域环境SQL Server镜像日常维护
本文接上面两篇搭建镜像的文章: 第三篇--第二部分--第三文 配置SQL Server镜像--域环境:http://blog.csdn.net/dba_huangzj/article/details/ ...
- [TypeScript] Using Lodash in TypeScript with Typings and SystemJS
One of the most confusing parts of getting started with TypeScript is figuring out how to use all th ...
- PHPExcel的读取excel的操作
首先导入类库: require_once 'PHPExcel.php'; require_once 'PHPExcel\IOFactory.php'; require_once 'PHPExcel\R ...
- MYSQL学习笔记3--mysql 2PC二阶段协义 与 日志闪回
mysql两份日志: binlog :server innodb redo log:engine 两份日志顺序一致性:否则主备不一致 两份日志:原子性,同时都有,同时都无 2PC二阶段协义: 第一阶段 ...
- LCA问题
基本概念 LCA:树上的最近公共祖先,对于有根树T的两个结点u.v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u.v的祖先且x的深度尽可能大. RMQ:区间最小值查询问题.对于长度为n的 ...
- C#教程之打印和打印预览
最近研究一了一下关于PDF打印和打印预览的功能,在此小小的总结记录一下学习过程. 实现打印和打印预览的方法,一般要实现如下的菜单项:打印.打印预览.页面设置. PrintDocument类 Print ...
- hibernate和mybatis思想,区别,优缺点
Hibernate 简介 Hibernate对数据库结构提供了较为完整的封装,Hibernate的O/R Mapping实现了POJO 和数据库表之间的映射,以及SQL 的自动生成和执行.程序员往往只 ...
- Sql操作表字段
1.增加字段 alter table docdsp add dspcodechar(200)2.删除字段 ALTER TABLE table_NAME DROP COLUMNc ...
- PHP语言、浏览器、操作系统、IP、地理位置、ISP
)]; } else { $Isp = 'None'; } return $Isp; }}