ELK 性能(4) — 大规模 Elasticsearch 集群性能的最佳实践
ELK 性能(4) — 大规模 Elasticsearch 集群性能的最佳实践
介绍
集群规模
集群数:6
整体集群规模:
- 300 Elasticsearch 实例
- 141 物理服务器
- 4200 CPU 核心
- 38TB RAM
- 1.5 Pb 存储
索引日志:
- 100 亿/天
- 400k/秒
内容
开场白
健康提示
将 Elasticsearch 集群的名称 “elasticsearch” 进行重命名。当网络内有两个以上的集群时,就会发现这样做所带来的好处。
为了防止误删除,设置参数
action.destructive_requires_name=true
始终使用 SSD 。这并不是可选的。
需要至少 10G 的带宽。
采用监护人制度,开发并发布自己的版本。
扩展
扩展 Elasticsearch 集群
影响到 Elasticsearch 集群的因素
CPU
- 核心数 > 时钟速度
内存
- 文档的数量
- 分片的数量
磁盘 I/O
- SSD 持续写的速率
网络带宽
- 至少 10G 的带宽保证快速恢复与重新索引
影响到集群内存的因素
- 段内存(segment memory):~4b RAM/文档 = ~4Gb/10亿行日志
- 字段数据内存(field data memory):几乎与段内存相当
- 过滤器缓存(filter cache):~1/4 到 1/2 的段内存,取决于搜索的内容
- 剩下的所有(50% 的系统内存)用作操作系统文件的缓存
- 无法获得足够的内存
影响到集群I/O的因素
- SSD 持续写速率
- 计算片恢复的速度(假设一个节点失败):
- 片大小(Shard Size)=(日存储量 / 分片的数量)
- (每个节点上分片的数量 * 片大小)/ (磁盘写速度 / 节点分片的数量)
- 例如:30Gb 分片,每个节点 2 个分片,250Mbps 的写速度:
- (2 * 30Gb)/ 125Mbps = 8 mintues
- 恢复弹性所能忍受的时间
- 可以忍受失去多少节点
- 一台服务器多个节点会增加恢复所需的时间
影响到网络的因素
- 10G 至少
- 10 分钟恢复 vs 50+ 分钟恢复
- 1G 瓶颈:网络上线
- 10G 瓶颈:磁盘速度
扩展 Logstash 集群
扩展 Logstash 的 CPU
- 规则 1:买所能承受的尽可能快的 CPU 核心
- 规则 2:参见第一条
- 更多的过滤 = 更多的 CPU
监控
| Marvel | 自研 |
|---|---|
| 易用 | 需要花时间开发 |
| 数据存入 ES | 与自己的系统集成 |
| 很多分析度量 | |
| 没有集成 | 重复造轮子 |
| 成本高 | 免费 |
监控 Elasticsearch
度量在多个地方都有暴露:
_cat API
包括了大多数度量,易读
_stats API,_nodes API
涵盖所有,JSON格式,易于解析
发送到 Graphite
创建 dashboards
监控系统
SSD 性能
监控 Logstash 报管道阻塞的频率,并找出原因
动态的磁盘空间阀值
((服务器的数量 - 失败的数量)/ 服务器的数量)- 15%
100 服务器
最多允许 6 个失败
磁盘空间预警的阀值 =((100 - 6)/ 100)- 15%
磁盘空间预警的阀值 = 79%
根据集群增加与移除节点的数量配置并管理系统
额外的 15% 是用来提供申请并准备更多节点的时间
扩展 Logstash
影响 Logstash 性能的因素
日志行的长度
Grok 模式的复杂度 - 正则表达式非常慢
插件的使用
GC
- 增加的堆大小
超线程
- 度量,并关闭
重复测量
将日志以 JSON 格式输出并没有带来很大的好处,除非不使用 grok,kv 等。Logstash 还是需要将字符串转换成为 ruby 的 hash
GC 垃圾回收
缺省配置通常是可以的
确保记录了 GC 的图
Ruby 会很容易的创建很多对象:在做伸缩扩展时需要监控 GC
在写插件时需要时刻记住 GC
不好的:1_000_000.times { "This is a string" }
| | user | system | total | real
| ------------------------- | ------------------------|
| time | 0.130000 | 0.000000 | 0.130000 | ( 0.132482)好用法:foo = 'This is a string'; 1_000_000.times { foo }
| | user | system | total | real
| ------------------------- | ------------------------|
| time | 0.060000 | 0.000000 | 0.060000 | ( 0.055005)
插件性能基准
如何建立基准
度量某些过滤器
度量更多的过滤器
计算每个过滤器的成本
社区提供的过滤器只是在大多数情况下适用
- 对于特殊的场景需要自己开发
- 易于使用
在测评时执行至少 5 分钟的时间,使用大数据集
建立基准的吞吐量:Python,StatsD,Graphite
Logstash 简单配置,10m 行 apache 日志,没有过滤:
input {
file {
path => "/var/log/httpd/access.log"
start_position => "beginning"
}
}
output {
stdout { codec => "dots" }
}
Python 脚本将 Logstash 输出到 statsd :
sudo pip install statsd #!/usr/bin/env python
import statsd, sys
c = statsd.StatsClient('localhost', 8125)
while True:
sys.stdin.read(1)
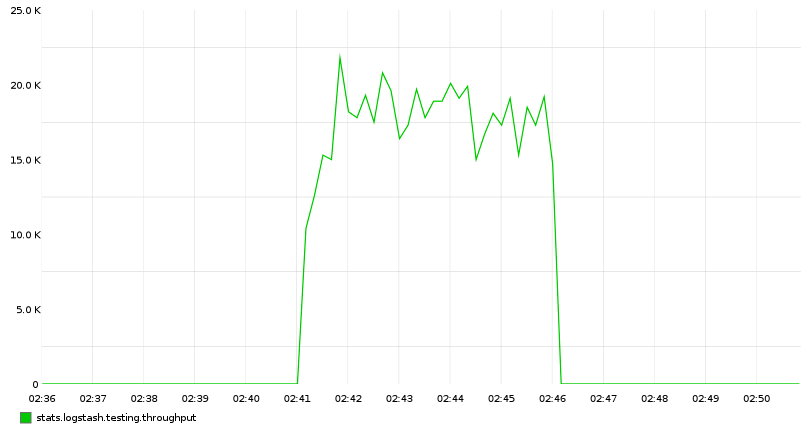
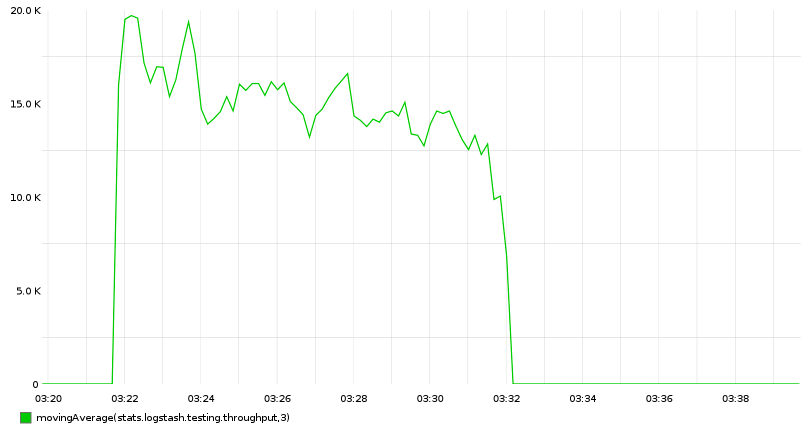
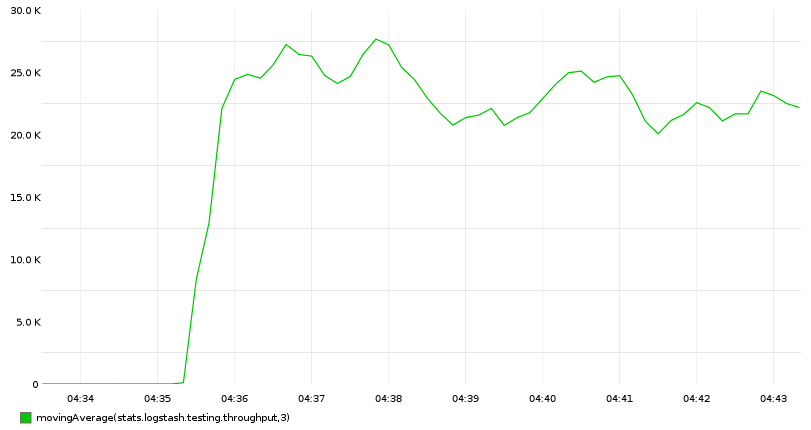
c.incr('logstash.testing.throughput', rate=0.001)
为什么我们不用 statsd 输出插件?它会降低输出的速度!
放在一起
logstash -f logstash.conf | pv -W | python throughput.py 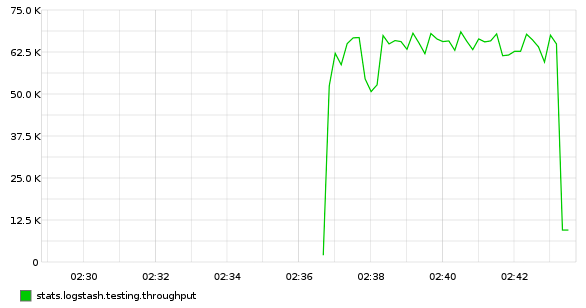
插件性能 Grok
增加一个简单的 Grok
grok { match => [ "message", "%{ETSY_APACHE_ACCESS}" ] }
在只有一个 worker 时,性能下降 80%
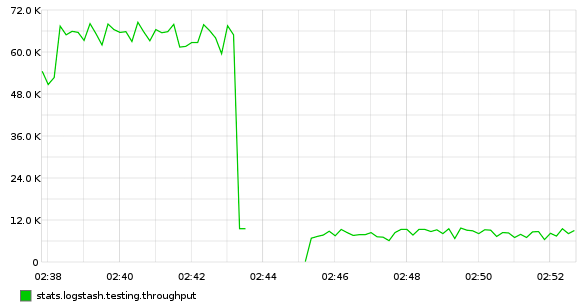
增加 worker 的数量,吞吐量仍然下降了 33%:65k/s -> 42k/s
-w <num_cpu_cores>
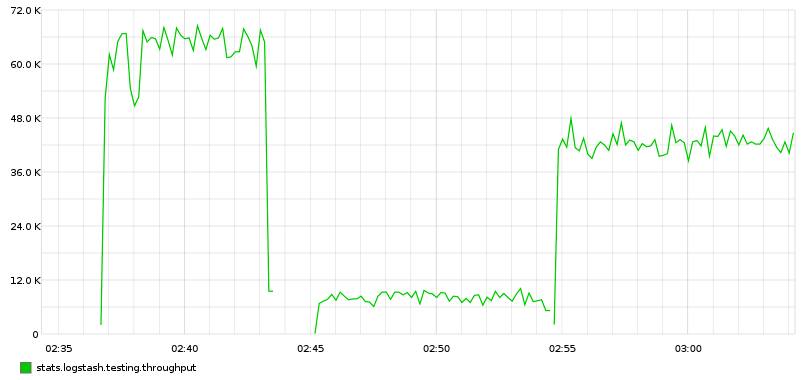
插件性能 kv
加一个 kv 过滤器
kv { field_split => "&" source => "qs" target => "foo" }
吞吐量基本不变,有 10% 的下降(40k/s)
吞吐量变化较大主要因为 GC 的压力
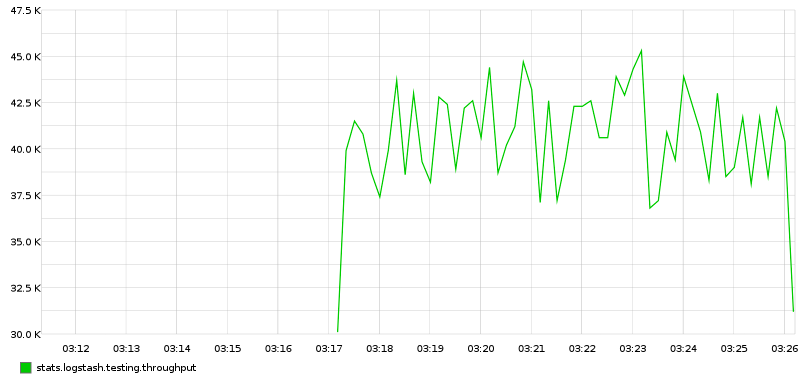
kv 很慢,以下是一个用来查询字符串的
splitkv插件kvarray = text.split(@field_split).map { |afield|
pairs = afield.split(@value_split)
if pairs[0].nil? || !(pairs[0] =~ /^[0-9]/).nil? || pairs[1].nil? ||
(pairs[0].length < @min_key_length && !@preserve_keys.include?(pairs[0]))
next
end
if !@trimkey.nil?
# 2 if's are faster (0.26s) than gsub (0.33s)
#pairs[0] = pairs[0].slice(1..-1) if pairs[0].start_with?(@trimkey)
#pairs[0].chop! if pairs[0].end_with?(@trimkey)
# BUT! in-place tr is 6% faster than 2 if's (0.52s vs 0.55s)
pairs[0].tr!(@trimkey, '') if pairs[0].start_with?(@trimkey)
end
if !@trimval.nil?
pairs[1].tr!(@trimval, '') if pairs[1].start_with?(@trimval)
end
pairs
}
kvarray.delete_if { |x| x == nil }
return Hash[kvarray]
splitkv之前的 CPU 占用率是 100% ,之后的占用率是 33% 。
Elasticsearch 的输出
- Logstash 的输出设置直接影响了 Logstash 所在机器的 CPU
- 将 flush_size 从 500 改到 5000 ,或更多
- 将 idle_flush_time 从 1s 改到 5s ,
- 增加输出线程 workers
- 结果受日志行的影响
- 调整,等待 15 分钟,然后观察
当使用缺省的 500 flush_size 时,Logstash 集群的峰值会达到 50% ,处理能力在每秒 ~40k 日志行。将这个值改到 10k 时,同时增加 idle_flush_time 到 5s 。处理能力在每秒 ~150k 日志行,同时 CPU 占用会下降到 25% 。
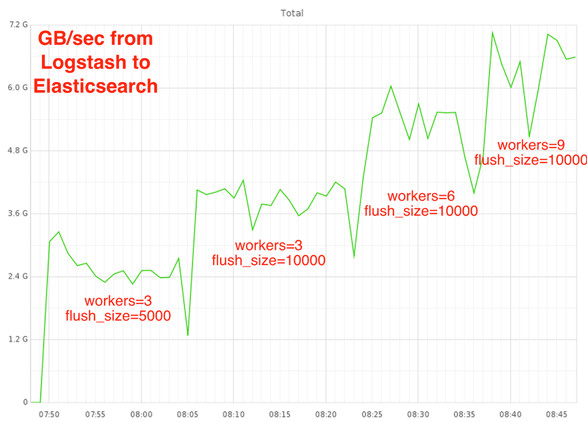
Pipeline 管道性能
Logstash 2.3 之前
…/vendor/…/lib/logstash/pipeline.rb
SizedQueue.new(20)
-> SizedQueue.new(500)
Logstash 2.3 之后
—pipeline-batch-size=500
最好在调优最后改变这个参数。管道的性能受输出插件性能的影响。
测试配置变更
增加上下文
发现管道的延迟
mutate { add_field =>
[ "index_time", "%{+YYYY-MM-dd HH:mm:ss Z}" ]
}
logstash 服务器处理日志行
mutate { add_field =>
[ "logstash_host", "<%= node[:fqdn] %>" ]
}
对日志行进行哈希,实现重放
hashid插件可以避免重复行~10% 下降
服务器上的配置
describe package('logstash'),
:if => os[:family] == 'redhat' do
it { should be_installed }
end
describe command('chef-client') do
its(:exit_status) { should eq 0 }
end
describe command('logstash -t -f ls.conf.test') do
its(:exit_status) { should eq 0 }
end
describe command('logstash -f ls.conf.test') do
its(:stdout) { should_not match(/parse_fail/) }
end
describe command('restart logstash') do
its(:exit_status) { should eq 0 }
end
describe command('sleep 15') do
its(:exit_status) { should eq 0 }
end
describe service('logstash'),
:if => os[:family] == 'redhat' do
it { should be_enabled }
it { should be_running }
end
describe port(5555) do
it { should be_listening }
end
Input
input {
generator {
lines => [ '<Apache access log>' ]
count => 1
type => "access_log"
}
generator {
lines => [ '<Application log>' ]
count => 1
type => "app_log"
}
}
Filter
filter {
if [type] == "access_log" {
grok {
match => [ "message", "%{APACHE_ACCESS}" ]
tag_on_failure => [ "parse_fail_access_log" ]
}
}
if [type] == "app_log" {
grok {
match => [ "message", "%{APACHE_INFO}" ]
tag_on_failure => [ "parse_fail_app_log" ]
}
}
}
Output
output {
stdout {
codec => json_lines
}
}
小结
更快的 CPU
CPU 核心数 > CPU 时钟速度
增加管道的大小
更多内存
18Gb+ 防止频繁 GC
横向扩展
为日志行添加上下文
编写自己的插件
对所有的东西进行性能评测
扩展 Elasticsearch
默认基准
Logstash 输出: 默认选项 + 4 workers
Elasticsearch: 默认选项 + 1 shard, no replicas
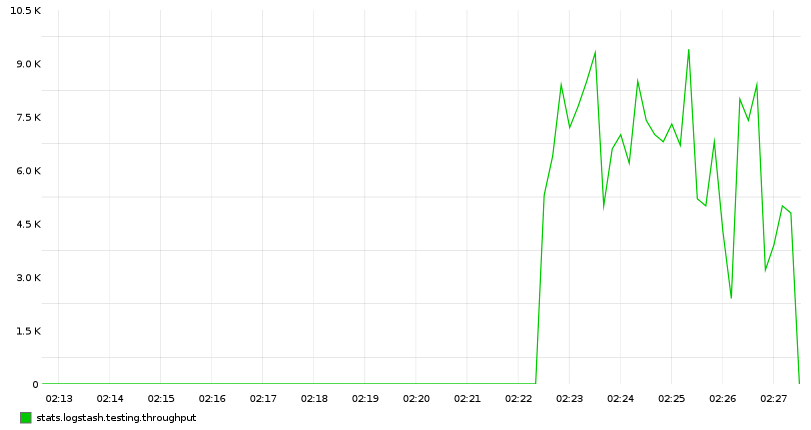
影响索引的因素
- 日志行的长度与分析,默认映射
- doc_values - 必须
- 使用更多的 CPU 时间
- 索引时使用更多的磁盘空间,磁盘 I/O
- 有助于降低内存的使用
- 如果发现 fielddata 使用过多内存,定位占用最多的,然后将它们移到 doc_values
- 为恢复保留足够的带宽
- CPU
分析
映射
默认映射会创建大量 .raw 字段
doc_values
合并
恢复
- 内存
- 索引的缓冲
- GC
- 段(segment)数量和未优化的索引
- 网络
恢复的速度
更快的网络 == 更短的恢复延迟
影响内存的因素
以 32Gb 堆为例的分布情况:
- Field data: 10%
- Filter cache: 10%
- Index buffer: 500Mb
- Segment cache (~4 bytes per doc):
每个节点可存储的文档数
32Gb - ( 32G / 10 ) - ( 32G / 10 ) - 500Mb = ~25Gb (段内存)
25Gb / 4b = 6.7bn 个文档(所有片的总和)
10bn docs / day, 200 shards = 50m docs/shard
- 1 daily shard per node: 6.7bn / 50m / 1 = 134 days
- 5 daily shards per node: 6.7bn / 50m / 5 = 26 days
Doc Values
Doc values 可以降低内存开销
Doc values 会消耗 CPU 和存储
部分字段使用 doc_values:
1.7G Aug 11 18:42 logstash-2015.08.07/7/index/_1i4v_Lucene410_0.dvd
所有字段使用 doc_values:
106G Aug 13 20:33 logstash-2015.08.12/38/index/_2a9p_Lucene410_0.dvd
不要盲目地为所有字段开启 doc_values
- 找到使用最频繁的字段,然后将它们转换成 Doc Values
- curl -s 'http://localhost:9200/_cat/fielddata?v' | less -S
示例
total request_uri _size owner ip_address 117.1mb 11.2mb 28.4mb 8.6mb 4.3mb 96.3mb 7.7mb 19.7mb 9.1mb 4.4mb 93.7mb 7mb 18.4mb 8.8mb 4.1mb 139.1mb 11.2mb 27.7mb 13.5mb 6.6mb 96.8mb 7.8mb 19.1mb 8.8mb 4.4mb 145.9mb 11.5mb 28.6mb 13.4mb 6.7mb 95mb 7mb 18.9mb 8.7mb 5.3mb 122mb 11.8mb 28.4mb 8.9mb 5.7mb 97.7mb 6.8mb 19.2mb 8.9mb 4.8mb 88.9mb 7.6mb 18.2mb 8.4mb 4.6mb 96.5mb 7.7mb 18.3mb 8.8mb 4.7mb 147.4mb 11.6mb 27.9mb 13.2mb 8.8mb 146.7mb 10mb 28.7mb 13.6mb 7.2mb
内存小结
实例使用 128Gb 或 256Gb RAM
根据硬件配置优化 RAM
Haswell/Skylake Xeon CPUs 有 4 个内存通道
Elasticsearch 多个实例
为每个实例分配自己的名称 node.name
CPU
CPU 密集型操作
- 索引:分析,合并,压缩
- 搜索:计算,解压缩
写压力
- CPU 核心数受并发的索引操作影响
- 核心数 优于 CPU 频率值
基准
为什么这么慢?
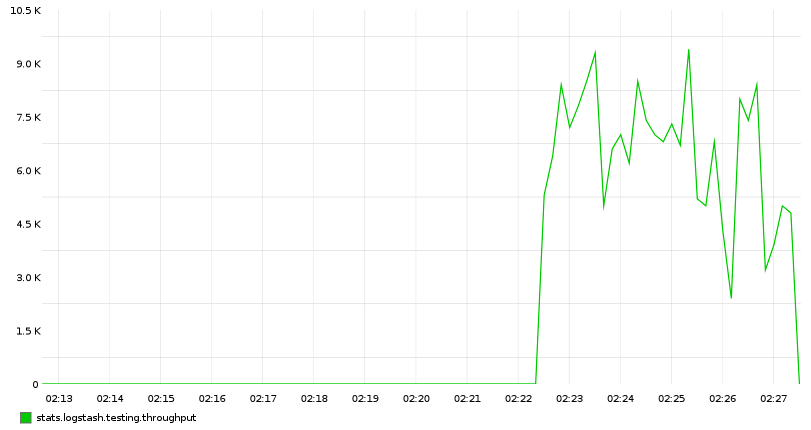
[logstash-2016.06.15][0] stop throttling indexing:
numMergesInFlight=4, maxNumMerges=5
合并
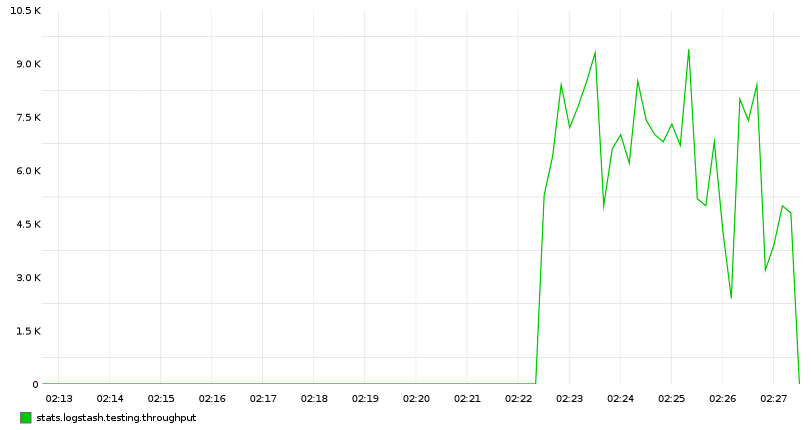
第一步:将分片数从 1 提升到 5
第二步:禁用 merge throttling(ES < 2.0)
index.store.throttle.type: none
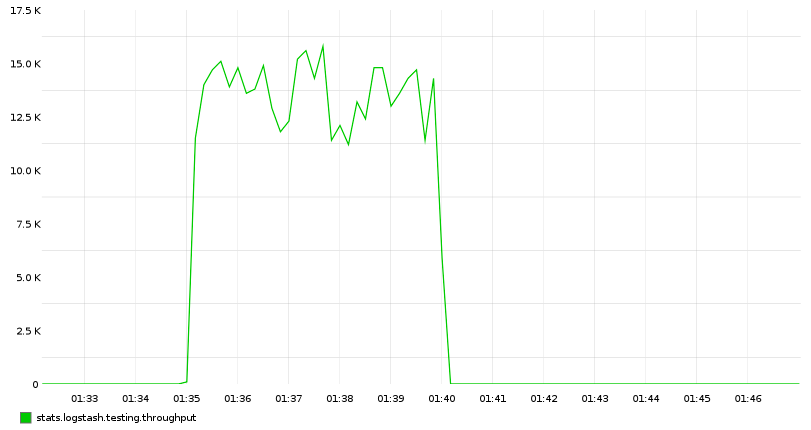
拆分 Hosts
当 CPU 接近最大时,需要加入更多节点
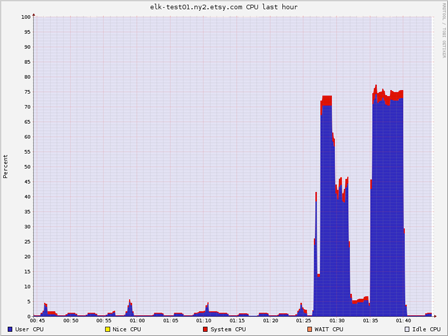
在不同 Hosts 上运行 Elasticsearch 以及 Logstash
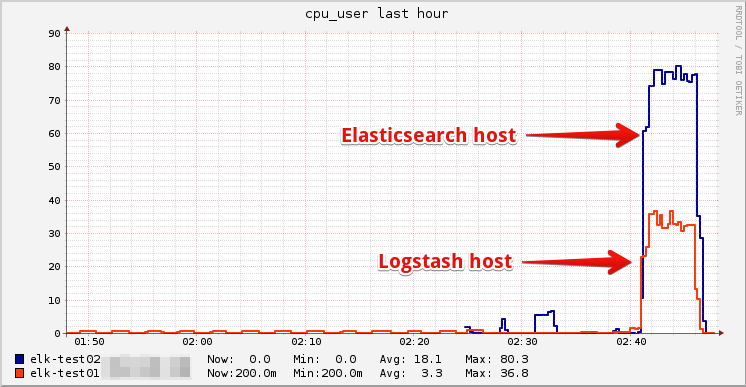
吞吐量有 50% 的提升:13k/s -> 19k/s
超线程 Hyperthreading
超线程可以提升 20% 的性能
CPU 治理
~15-30% 的性能提升。
# echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
存储
磁盘 I/O
建议
- 使用 SSD
- RAID 0
- 软 RAID 足够
更多的建议
好的 SSD 非常重要
廉价 SSD 会大大降低性能
不要使用多个数据路径,使用 RAID 0
大量的 translog 写磁盘操作会是瓶颈
如果有大量段合并,但是 CPU 和 磁盘 I/O 还有空闲:
可以尝试提升值
index.merge.scheduler.max_thread_count
降低间隔(Durability)
index.translog.durability: async
Translog fsync() 值为 5s ,足够
集群的恢复会吃掉大量磁盘 I/O
需要在恢复前后调整相应的参数
indices.recovery.max_bytes_per_sec: 300mb
cluster.routing.allocation.cluster_concurrent_rebalance: 24
cluster.routing.allocation.node_concurrent_recoveries: 2
任何的持续 I/O 等待都意味着存在一个次优状态
SSD 的选择
消费级
- 慢速写
- 廉价
- 低耐久性,每天相对较少的写次数
企业级
- 快速写
- 昂贵
- 高耐久性,每天相对较高的写次数
大量读
- 低耐久性,1-3 DWPD
- 低速读,代价小
混合使用
- 中度耐久性,10 DWPD
- 平衡读写,中等价位
大量写
- 高耐久性,25 DWPD
- 高速写,代价高
基准
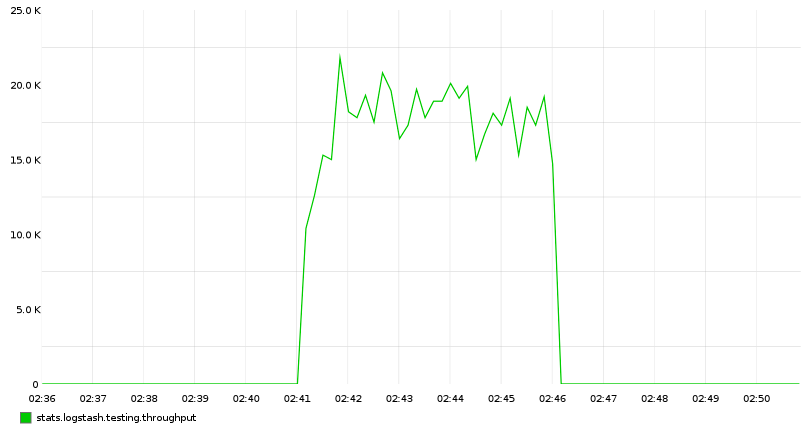
降低间隔后,基本仍然维持在 ~20-25k,但更平滑
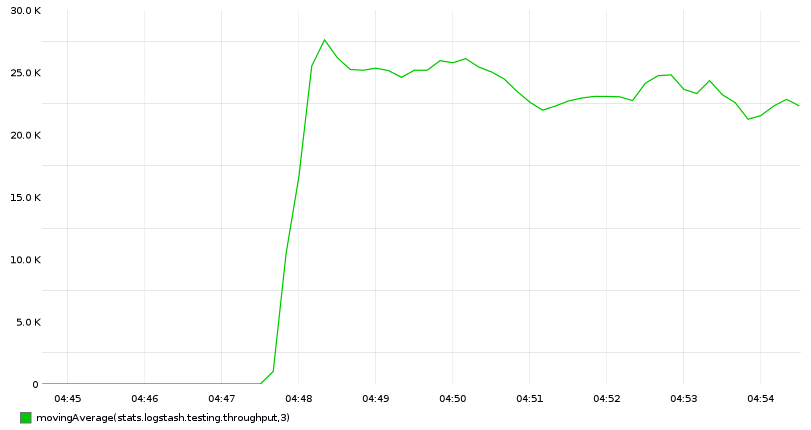
为什么提升很小?Merging
$ curl -s 'http://localhost:9200/_nodes/hot_threads?threads=10' | grep %
73.6% (367.8ms out of 500ms) 'elasticsearch[es][bulk][T#25]'
66.8% (334.1ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #139]'
66.3% (331.6ms out of 500ms) 'elasticsearch[es][[logstash][3]: Lucene Merge Thread #183]'
66.1% (330.7ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #140]'
66.1% (330.4ms out of 500ms) 'elasticsearch[es][[logstash][4]: Lucene Merge Thread #158]'
62.9% (314.7ms out of 500ms) 'elasticsearch[es][[logstash][3]: Lucene Merge Thread #189]'
62.4% (312.2ms out of 500ms) 'elasticsearch[es][[logstash][2]: Lucene Merge Thread #160]'
61.8% (309.2ms out of 500ms) 'elasticsearch[es][[logstash][1]: Lucene Merge Thread #115]'
57.6% (287.7ms out of 500ms) 'elasticsearch[es][[logstash][0]: Lucene Merge Thread #155]'
55.6% (277.9ms out of 500ms) 'elasticsearch[es][[logstash][2]: Lucene Merge Thread #161]'
分层存储
- 将更多访问的索引放在更多的服务器上,并分配更多的内存以及更快的 CPU
- 将 “冷” 索引独立存储(SSD下仍然需要这么做)
- 设置 index.codec: best_compression
- 移动索引,重新优化
- 构建 elasticsearch-curator 可以让事情变得简单
为什么默认的配置 Merging 如此多?
$ curl 'http://localhost:9200/_template/logstash?pretty'
看到了吗?
"string_fields" : {
"mapping" : {
"index" : "analyzed", // <--- see?
"omit_norms" : true,
"type" : "string",
"fields" : {
"raw" : {
"ignore_above" : 256, // <--- see?
"index" : "not_analyzed", // <--- see?
"type" : "string" // <--- see?
}
}
},
"match_mapping_type" : "string",
"match" : "*"
}
使用自定义映射
"string_fields" : {
"mapping" : {
"index" : "not_analyzed",
"omit_norms" : true,
"type" : "string"
},
"match_mapping_type" : "string",
"match" : "*"
}
有那么一点帮助
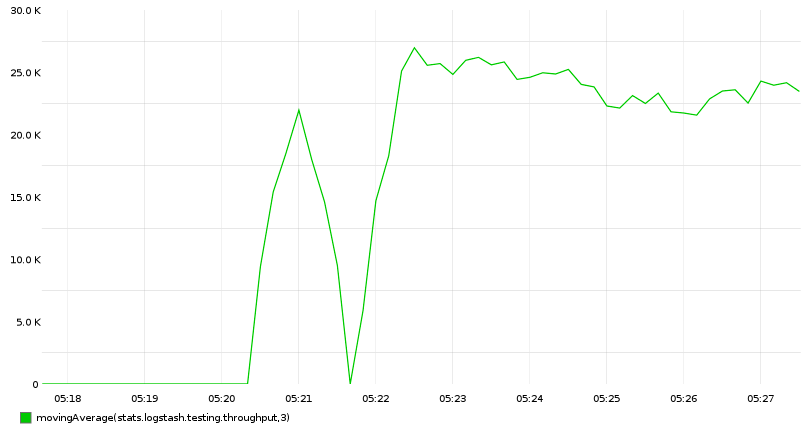
索引的性能
增加 bulk 线程池可以控制索引的爆发
但同时也要注意,这会隐藏性能的问题
增加索引的缓冲
增加刷新的时间,1s 到 5s
将索引请求发送到多个 hosts
增加 worker 直到没有明显的性能提升为止
num_cpu / 2
增加 flush_size 知道没有明显的性能提升为止
10,000
磁盘 I/O 性能
索引协议
- HTTP
- Node
- Transport
Transport 仍然是性能最好的,但是 HTTP 已经非常接近了
Node 基本上不会使用
自定义映射模板
- 默认模板为每个字段额外生成 not_analyzed.raw 字段
- 分析每个字段会占用 CPU
- 额外的字段会吃掉更多磁盘空间
- 动态字段和 Hungarian 标记
使用开启了动态字段的自定义映射模板,但是将它们设置为 non_analyzed 剔除 .raw 字段,除非真的需要它。
这可以将 Elasticsearch 集群的 CPU 的使用率从 28% 降到 15%
消息的复杂度也十分相关
加 20k 的新行与平均 1.5k 的索引速率
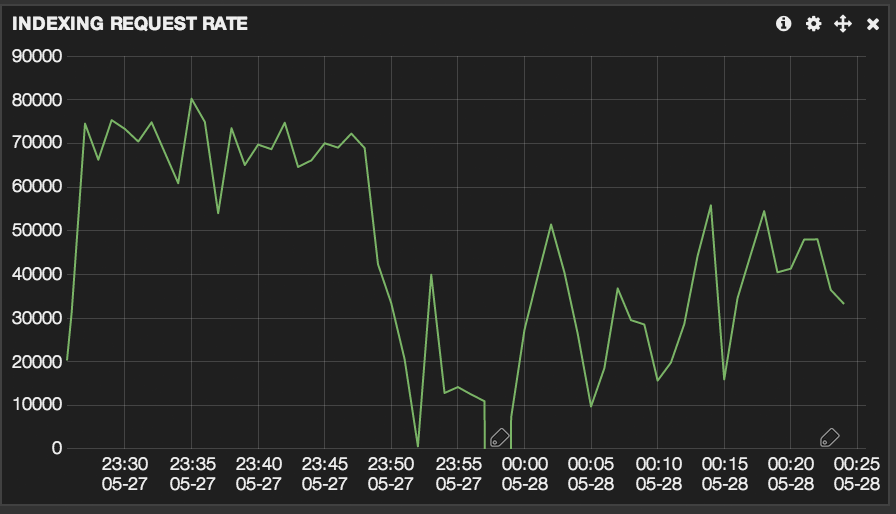
截断
ruby { code =>
"if event['message'].length > 10240 then
event['message'] = event['message'].slice!(0,10240)
end"
}
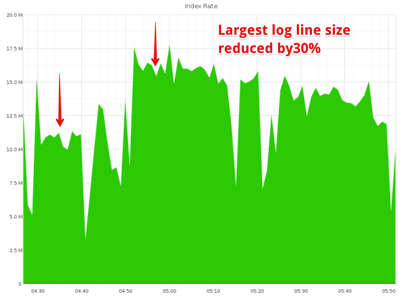
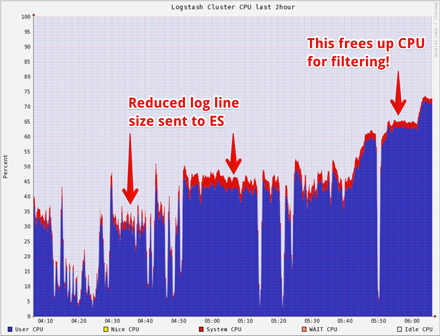
让 Logstash 做更多的事情
索引的大小
按索引来调优分片
num_shards = (num_nodes - failed_node_limit) / (number_of_replicas + 1)
50 个节点,并允许最多 4 个节点失败,replication 为 1x:
num_shards = (50 - 4) / (1 + 1) = 23
如果分片大于 25Gb ,需要相应增加分片数
调优 indices.memory.index_buffer_size
index_buffer_size = num_active_shards * 500Mb
其中“active_shards”:指任何 5 分钟内更新的分片
调试 refresh_interval
默认 1s - 过于频繁
增加到 5s
更高的值会导致磁盘抖动
目标:将磁盘里的缓冲尽可能的移储
例如:Samsung SM863 SSDs
DRAM buffer: 1Gb
Flush speed: 500Mb/sec
参考
参考来源:
2016.6 ELK: Moose-ively scaling your log system
结束
ELK 性能(4) — 大规模 Elasticsearch 集群性能的最佳实践的更多相关文章
- PB 级大规模 Elasticsearch 集群运维与调优实践
PB 级大规模 Elasticsearch 集群运维与调优实践 https://mp.weixin.qq.com/s/PDyHT9IuRij20JBgbPTjFA | 导语 腾讯云 Elasticse ...
- RHCS集群理论暨最佳实践
RHCS集群理论暨 最佳实践 什么是集群? 集群是一组(>2)相互独立的,通过高速网络互联的计算机组成的集合.群集一般可以分为科学集群,负载均衡集群,高可用性集群三大类. 科学集 ...
- ELK教程1:ElasticSearch集群的部署ELK
在分布式系统中,应用数量众多,应用调用链复杂,常常使用ELK作为日志收集.分析和展示的组件.本篇文章将讲讲解如何部署ELK,然后讲解如何使用Filebeat采集Spring Boot的日志输出到Log ...
- PB级大规模Elasticsearch集群运维与调优实践
导语 | 腾讯云Elasticsearch 被广泛应用于日志实时分析.结构化数据分析.全文检索等场景中,本文将以情景植入的方式,向大家介绍与腾讯云客户合作过程中遇到的各种典型问题,以及相应的解决思路与 ...
- PB级大规模Elasticsearch集群运维与调优实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>> Elasticsearch Service自建迁移特惠政策>>Elasticsearch Service新用户 ...
- 大规模Elasticsearch集群管理心得
转载:http://elasticsearch.cn/article/110 ElasticSearch目前在互联网公司主要用于两种应用场景,其一是用于构建业务的搜索功能模块且多是垂直领域的搜索,数据 ...
- vivo大规模 Kubernetes 集群自动化运维实践
作者:vivo 互联网服务器团队-Zhang Rong 一.背景 随着vivo业务迁移到K8s的增长,我们需要将K8s部署到多个数据中心.如何高效.可靠的在数据中心管理多个大规模的K8s集群是我们面临 ...
- 基于kubernetes集群的Vitess最佳实践
概要 本文主要说明基于kubernetes集群部署并使用Vitess; 本文假定用户已经具备了kubernetes集群使用环境,如果不具备请先参阅基于minikube的kubernetes集群搭建, ...
- ES集群性能调优链接汇总
1. 集群稳定性的一些问题(一定量数据后集群变得迟钝) https://elasticsearch.cn/question/84 2. ELK 性能(2) — 如何在大业务量下保持 Elasticse ...
随机推荐
- C# 使用 iTextSharp 将 PDF 转换成 TXT 文本
var pdfReader = new PdfReader("xxx.pdf"); StreamWriter output = new StreamWriter(new FileS ...
- 一个新的Android Studio 2.3.3可以在稳定的频道中使用。A new Android Studio 2.3.3 is available in the stable channel.
作者:韩梦飞沙 Author:han_meng_fei_sha 邮箱:313134555@qq.com E-mail: 313134555 @qq.com 一个新的Android Studio 2.3 ...
- 洛谷.2754.星际转移问题(最大流Dinic 分层)
题目链接 枚举时间 每一个时间点 对于每个之前的位置像当前位置连边,表示这一时刻可待在原地 每艘船 之前时刻位置向当前时刻连边 注意别漏了0时刻src连向earth的边 #include<cst ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第二课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 用单片机控制LED灯(项目)
#include <reg52.h> #define uchar unsigned char sbit LED_RED = P2^; sbit LED_GREEN = P2^; sbit ...
- C++ 类模板基础知识
类模板与模板类 为什么要引入类模板:类模板是对一批仅仅成员数据类型不同的类的抽象,程序员只要为这一批类所组成的整个类家族创建一个类模板,给出一套程序代码,就可以用来生成多种具体的类,(这类可以看作是类 ...
- String、StringBuffer、StringBulider
三者都实现了CharSequence接口,因此CharSequence可认为是一个字符串的协议接口 1.String类是不可变类,即一旦一个String对象被创建后,包含在这个对象中的字符序列是不可改 ...
- j2me必备之网络开发数据处理
第9章 无线网络开发MIDP提供了一组通用的网络开发接口,用来针对不同的无线网络应用可以采取不同的开发接口.基于CLDC的网络支持是由统一网络连接框架(Generic Connection Frame ...
- ssdb安装注意事项
官网的安装教程依赖于autoconf,需要提前安装.
- idea jsp html 空白页的问题
摘要 最近没事儿瞎折腾java web,在idea中,突然发现无法显示页面了. 问题 为什么会出现这个问题? 接触了过滤器的内容,然后在项目中添加了这样的一个过滤器,用来对post过来的数据进行ut8 ...