ELK教程1:ElasticSearch集群的部署ELK
在分布式系统中,应用数量众多,应用调用链复杂,常常使用ELK作为日志收集、分析和展示的组件。本篇文章将讲讲解如何部署ELK,然后讲解如何
使用Filebeat采集Spring Boot的日志输出到Logstash上,logstash再将日志输出到Elasticsearch上,最后展示到kibana上面。整个日志采集流程如下图:

在传统的日志采集只会用ELK,那么为什么需要使用filebeat呢,因为
logstash是java应用,解析日志是非的消耗cpu和内存,logstash安装在应用部署的机器上显得非常的影响应用的性能。最常见的做法是用filebeat部署在应用的机器上,logstash单独部署,然后由
filebeat将日志输出给logstash解析,解析完由logstash再传给elasticsearch。
安装计划
本文主要讲解如何部署ElasticSearch 集群,部署的ElasticSearch的版本为7.2,计划用三台机器组成一个ElasticSearch集群,从而组成高可用,机器分配如下:
| 节点 | 规则 | 数量 |
| -------- | -----: | :----: |
| 192.168.1.1 | 2核4G | 1 |
| 192.168.1.2 | 2核4G | 1 |
| 192.168.1.3 | 2核4G | 1 |
安装
下载安装执行以下命令:
# 下载elasticsearch-7.2.-x86_64的rpm包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-x86_64.rpm
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-x86_64.rpm.sha512
# shasum 检查版本信息
shasum -a -c elasticsearch-7.2.-x86_64.rpm.sha512
# rpm本地安装
sudo rpm --install elasticsearch-7.2.-x86_64.rpm
安装成功ElasticSearch成功后,执行一下命令启动elasticSearch,并设置为开启自启动:
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
elasticSearch的默认端口为9200,启动成功后,执行以下命令:
curl -X GET "localhost:9200/"
如果返回以下的信息,则证明安装成功:
{
"name" : "VM_0_5_centos",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "gst98AuET6a648YmAkXyMw",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
查看节点的健康状态,执行命令 curl localhost:9200/_cluster/health ,如果返回以下信息,则Elasticsearch则为监控状态
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : ,
"number_of_data_nodes" : ,
"active_primary_shards" : ,
"active_shards" : ,
"relocating_shards" : ,
"initializing_shards" : ,
"unassigned_shards" : ,
"delayed_unassigned_shards" : ,
"number_of_pending_tasks" : ,
"number_of_in_flight_fetch" : ,
"task_max_waiting_in_queue_millis" : ,
"active_shards_percent_as_number" : 100.0
}
可以执行以下的命令,查看es的 journal:
sudo journalctl --unit elasticsearch
配置
以下的路径的配置文件可以配置es的java_home,es_config_home :
/etc/sysconfig/elasticsearch
es本身的一些配置在以下的路径,在这里可以配置elasticsearch的堆内存,数据保留天数等信息:
/etc/elasticsearch
所有的配置文件描述和路径如下表所示:
| 配置类型 | 描述 | 路径 |
| home | elasticsearch的home目录 | /usr/share/elasticsearch |
| bin | elasticsearch的bin目录 | /usr/share/elasticsearch/bin |
| conf | elasticsearch的配置文件 | /etc/elasticsearch |
| conf | elasticsearch的环境变量配置 | /etc/sysconfig/elasticsearch |
| data | elasticsearch的数据目录 | /var/lib/elasticsearch |
| logs | elasticsearch的日志目录 | /var/log/elasticsearch |
| plugins | elasticsearch的插件目录 | /usr/share/elasticsearch/plugins |
集群搭建
在三台机器上分别装完elasticsearch,在主节点vim /etc/elasticsearch/,配置一下的信息:
主节点的配置如下:
#三个集群需要同样的集群名
cluster.name: my-application
# 每个node的名字需要唯一
node.name: node- node.master: true
#允许该节点存储数据(默认开启)
node.data: true
#注意一定要是路径后面加上/var/lib/elasticsearch/nodes,要不然无法加入集群
path.data: /var/lib/elasticsearch/nodes
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port:
transport.tcp.port:
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: false
discovery.seed_hosts: ["192.168.1.1", "192.168.1.2", "192.168.1.3"]
cluster.initial_master_nodes: ["192.168.1.1", "192.168.1.2", "192.168.1.3"]
同理从节点的配置:
cluster.name: my-application
# 每个node的名字需要唯一,两个从节点的名字不能相同
node.name: node-
node.master: true
#允许该节点存储数据(默认开启)
node.data: true
path.data: /var/lib/elasticsearch/nodes
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port:
transport.tcp.port:
xpack.security.enabled: false
http.cors.enabled: true
http.cors.allow-origin: "*"
discovery.seed_hosts: ["192.168.1.1", "192.168.1.2", "192.168.1.3"]
cluster.initial_master_nodes: ["192.168.1.1", "192.168.1.2", "192.168.1.3"]
配置完主从节点,需要重启三台elasticsearch,重启命令如下:
sudo systemctl restart elasticsearch.service
重启三台Elasticsearch后,执行curl http://localhost:9200/_cat/master,如果响应如下,则证明安装成功
SHBUDVUAQhi7FauSoI8bMg 192.168.1.1 192.168.1.1 node-
也路执行命令curl -XGET ‘http://127.0.0.1:9200/_cat/nodes?pretty’,返回类型如下的数据则安装成功:
192.168.1.2 0.00 0.03 0.05 mdi - node-
192.168.1.3 0.01 0.07 0.07 mdi - node-
192.168.1.1 0.05 0.05 0.05 mdi * node-
也可以通过命令curl localhost:9200/_cluster/health?pretty,查看集群的健康状态:
{
"cluster_name" : "my-application",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : ,
"number_of_data_nodes" : ,
"active_primary_shards" : ,
"active_shards" : ,
"relocating_shards" : ,
"initializing_shards" : ,
"unassigned_shards" : ,
"delayed_unassigned_shards" : ,
"number_of_pending_tasks" : ,
"number_of_in_flight_fetch" : ,
"task_max_waiting_in_queue_millis" : ,
"active_shards_percent_as_number" : 100.0
}
Elasticsearch中信息很多,同时ES也有很多信息查看命令,可以帮助开发者快速查询Elasticsearch的相关信息。
$ curl localhost:/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
head安装
在elasticsearch的高级版本之后,head不在是一个插件,而是一个独立的应用来部署,源码地址在https://github.com/mobz/elasticsearch-head。
需要提前安装node,安装命令如下:
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
安装成功后,打开 http://localhost:9100/,浏览器显示如下的界面,则安装成功:
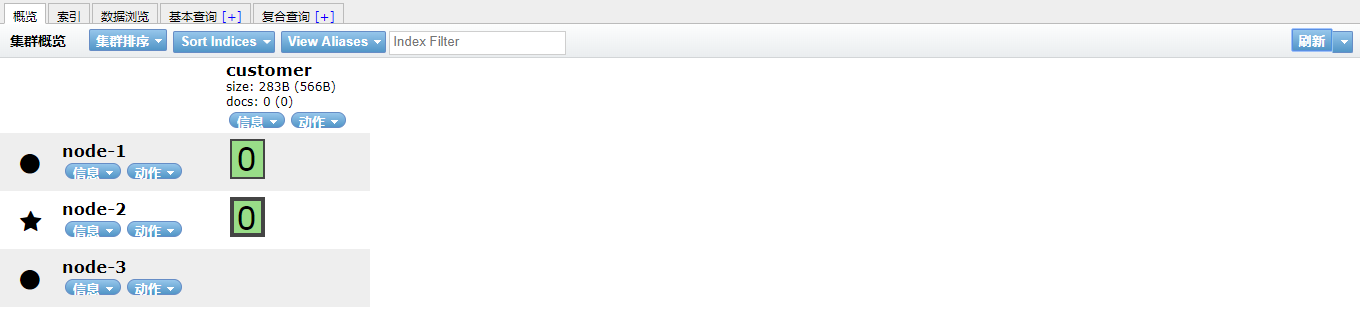
如上图所示,在Head组件的界面上,可以很方便的查看集群的状态和数据。
参考资料
https://www.elastic.co/guide/en/elasticsearch/reference/7.2/rpm.html
https://www.elastic.co/guide/index.html
https://www.elastic.co/guide/en/elasticsearch/plugins/current/installation.html
本文地址:https://www.cnblogs.com/xikui/p/11792618.html
版权声明:本文为CSDN博主「方志朋」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/forezp/article/details/98322077
ELK教程1:ElasticSearch集群的部署ELK的更多相关文章
- ELK 中的elasticsearch 集群的部署
本文内容 背景 ES集群中第一个master节点 ES slave节点 本文总结 Elasticsearch(以下简称ES)搭建集群的经验.以 Elasticsearch-rtf-2.2.1 版本为例 ...
- Centos8 部署 ElasticSearch 集群并搭建 ELK,基于Logstash同步MySQL数据到ElasticSearch
Centos8安装Docker 1.更新一下yum [root@VM-24-9-centos ~]# yum -y update 2.安装containerd.io # centos8默认使用podm ...
- EFK教程(4) - ElasticSearch集群TLS加密通讯
基于TLS实现ElasticSearch集群加密通讯 作者:"发颠的小狼",欢迎转载 目录 ▪ 用途 ▪ ES节点信息 ▪ Step1. 关闭服务 ▪ Step2. 创建CA证书 ...
- 日志分析平台ELK之搜索引擎Elasticsearch集群
一.简介 什么是ELK?ELK是Elasticsearch.Logstash.Kibana这三个软件的首字母缩写:其中elasticsearch是用来做数据的存储和搜索的搜索引擎:logstash是数 ...
- elasticsearch 集群的安装部署
一 介绍 elasticsearch 是居于lucene的搜素引擎,可以横向集群扩展以及分片,开发者无需关注如何实现了索引的备份,集群同步,分片等,我们很容易通过简单的配置就可以启动elasticse ...
- EFK教程(5) - ES集群开启用户认证
基于ES内置及自定义用户实现kibana和filebeat的认证 作者:"发颠的小狼",欢迎转载 目录 ▪ 用途 ▪ 关闭服务 ▪ elasticsearch-修改elastics ...
- 手把手教你搭建一个Elasticsearch集群
一.为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? (1)高可用性 Elasticsearch 作为一个 ...
- Elasticsearch 集群 单服务器 超级详细教程
前言 之前了解了Elasticsearch的基本概念.将spring boot + ElasticSearch + head插件 搞通之后.紧接着对es进行下一步的探索:集群.查阅资料的过程中,找到了 ...
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
随机推荐
- 压测工具wrk的编译安装与基础使用
Linux上编译安装: [root@centos ~]# cd /usr/local/src [root@centos ~]# yum install git -y [root@centos ~]# ...
- 【转载】 C#使用Math.Abs返回数值的绝对值
在C#的数值运算中,有时候我们需要计算值类型对象的绝对值,此时需要用到C#的数值计算类Math类中的Abs绝对值函数,Math.Abs绝对值函数一共有7个重载类型,支持decimal.double.f ...
- src属性与浏览器渲染
img标签 只要设置了src属性, 就会开始下载,因此可以使用这个特性,配合display:none,默默的下载一些图片,用的时候直接用,快了那么一丢丢~ 注意:不一定要添加到文档后才会开始下载,是只 ...
- iOS应用状态保存和恢复
当应用被后台Kill掉的时候希望从后台返回的时候显示进入后台之前的内容 在Appdelegate中设置 - (BOOL)application:(UIApplication *)application ...
- oracle 删除表空间
第一步,删除表空间前如果忘记表空间名称和用户名,可以通过以下命令进行查询. ---查找用户select * from dba_users; --查找工作空间的路径select * from dba_d ...
- gitlab(7.9)升级到8.0.1
1.gitlab8.0更新说明 GitLab 8.0 现在完全集成了持续集成工具 (GitLab CI) ,此外还完全重写了 UI,节省了至少 50% 的磁盘空间.更快的合并,内置持续集成(CI)到 ...
- python的time模块和datetime模块
1. 将当前时间转成字符串 strftime 方法,并输出 import datetime # 获取当前时间 datetime.datetime.now() print(datetime.dateti ...
- XPath知识点【一】
什么是 XPath? XPath 使用路径表达式在 XML 文档中进行导航 XPath 包含一个标准函数库 XPath 是 XSLT 中的主要元素 XPath 是一个 W3C 标准 XPath 路径表 ...
- 小程序框架之视图层 View
(1)视图层View 框架的视图层由 WXML 与 WXSS 编写,由组件来进行展示. 将逻辑层的数据反应成视图,同时将视图层的事件发送给逻辑层. WXML(WeiXin Markup languag ...
- codevs 1341 与3和5无关的数
题目描述 Description 有一正整数a,如果它能被x整除,或者它的十进制表示法中某位上的数字为x,则称a与x相关.现求所有小于等于n的与3或5无关的正整数的平方和. 输入描述 Input De ...