论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos
CVPR 2016
Motivation:
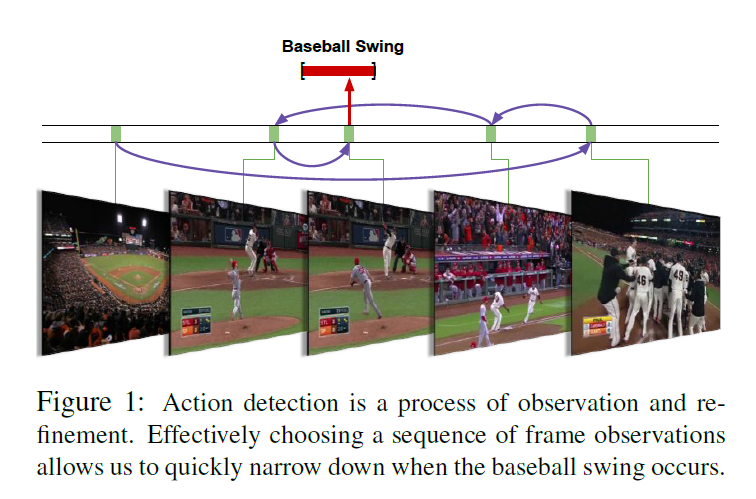
本文主要是想借助空间的 attention model 来去协助进行行人识别的工作。作者认为 long, read-world videos 是一个非常具有挑战的视觉问题。算法必须推理出是否出现了某个 action, 并且还要在时间步骤上推出出现在什么时刻。大部分的工作都是通过构建 frame-level classifiers,通过多个时间尺度,并且采用后期处理的方法,如:duration priors and non-maximum supression。但是这种间接地动作定位的方法在时间复杂度和精确度上都有待提升。
本文提出了一种 end to end 的方法进行行为的识别,直接来推理 action的 temporal bounds。我们的关键直觉在于:行为识别的过程是一个 continuous, iterative observation and refinement. 我们可以序列的决定 where to look and how to refine our hypotheses 以得到准确的行为定位和尽可能少的搜索。
基于该想法,我们提出 single coherent model,将 long video 作为输入,输出检测到的 action instances 的 temporal bounds。我们的模型可以看做是 an agent 学习一个策略,来序列的决定和优化关于 action instances 的优化假设。本文算法也是基于 Recurrent Model of Visual Attention 这个文章来的,但是 action recognition 提出了一种新的挑战: how to handle a variable-sized set of structured detection outputs ?
为了解决这个问题,我们提出的模型可以同时决定 which frame to observe next 以及 when to emit a prediction. 在此基础上,提出了一种奖励机制来确保学习到该策略。本文是第一个提出 end to end approach 来学习视频中行为的检测。
Methods:
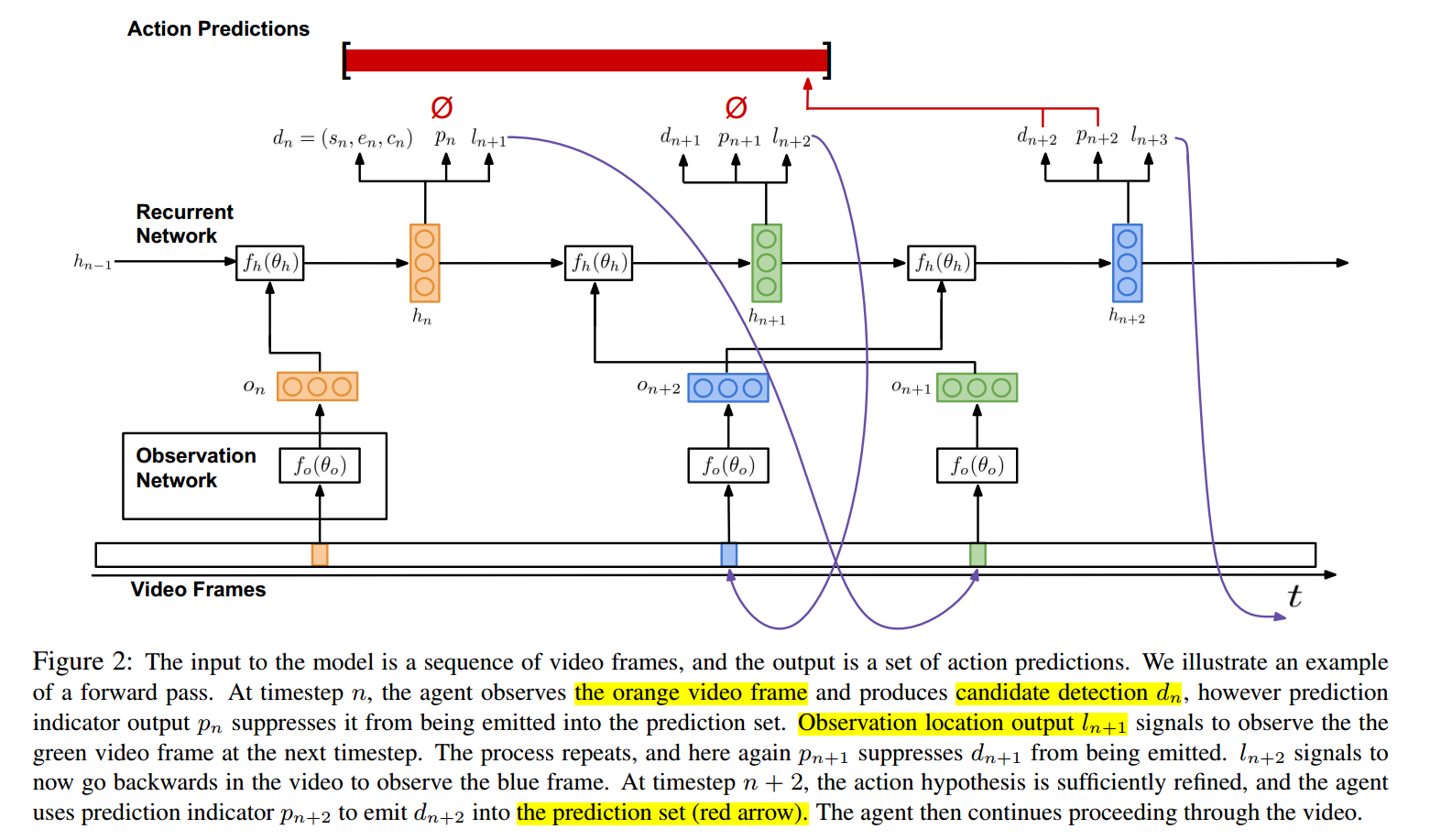
网络结构的设计主要包括两个部分: an observation network, and a recurrent network. 其中,观测网络主要是用来编码 video frame 的视觉表达,而 RNN 主要是用来处理这些观测以及决定下一步观测哪一帧,何时进行发射(即:进行 action 的预测)。
1. Observation Network:
像图2展示的那样,观测网络每一个时间步骤,观测到一个视频帧;将其编码为 a feature vector $o_n$,并且将其作为 RNN 的输入。
更重要的是,$o_n$ 编码了 where 和 what 的信息,即:where in the video an observation was taken 以及 what was seen。观测网络的输入是:the normalized temporal location of the observation, $l_n \in [0, 1]$,以及 对应的视频帧 $v_{l_n}$。
2. Recurrent Network:
RNN 网络 fh,构成了 agent 的核心。像图2所示的那样,每一个时刻 n 的输入是:观测特征向量 $o_n$。网络的 hidden state $h_n$,是 $o_n$ 和 前一个时刻状态 $h_{n-1}$,关于 action instance,对 temporal hypotheses 进行了建模。
随着 agent 在视频中进行推理,在每一个时间步骤,有三个输出:candidate detection $d_n$, binary indicator $p_n$ 表明是否对 $d_n$ 进行发射,以得到一个预测结果,temporal location $l_{n+1}$ 表示下一个时刻需要观测的视频帧。
Candidate detection (候选检测):
利用函数 $d_n = f_d(h_n; \theta_d)$ 得到一个候选检测 $d_n$,其中 fd 是全连接层。dn 是一个 tuple $(s_n, e_n, c_n) \in [0, 1]^3$,其中,sn 和 en 是归一化的 开始和结束的检测位置,cn 是检测的候选置信度。这个 candidate detection 代表了当前action instance周围的 agent 假设。然而,并非每一个时刻都进行检测,因为这会导致大量的 noise 以及许多 false positive。相反,the agent 利用 separate prediction indicator output 来表示候选检测应该被发射,以得到当前的 prediction。
Prediction indicator (预测指示器):
二进制的 prediction indicator $p_n$ 表示对应的候选检测 dn 应该被发射作为一个 prediction。$P_n = f_p(h_n; \theta_p)$,其中 fp 是全连接层,紧跟着 sigmoid nonlinearity. 在训练的时候,fp is used to parameterize a Bernoulli distribution from which $p_n$ is sampled; 在测试的时候,选择最大后验预测。
候选检测 和 预测标识符 的组合 对于检测问题来说,是非常重要的,因为 positive instance 可能随处可见,也可能根本不会出现。这样就确保了该网络可以
Location of next observation (下一个观测的位置):
时间的位置 $l_{n+1} \in [0, 1]$ 表示了 agent 选择的下一个时刻要选择的 video frame。位置不受限,agent 可以随意的在 video 上进行 skip。
位置的计算依赖于函数 $l_{n+1} = f_l (h_n; \theta_l)$,其中 fl 是全连接层, agent 的决策 是关于其过去观测的历史 以及 temporal location 的函数。在训练的时候,$l_{n+1}$ 是从 Gaussian distribution 上采样出来的;在测试的时候,the maximum a posteriori estimate is used.
Training :
我们的最终目标是输出一组检测到的动作(output a set of detected actions)。为了达到这个目标,我们需要训练在每个时刻都有三个输出:candidate detection, prediction indicator, and next observation location. 给定长视频中,时序动作标注的监督,训练这些涉及到以下几个挑战:
1. suitable loss
2. reward function
3. handling non-differentiable model components.
我们这里采用 REINFORCE 的方法来训练 $p_n and L_{n+1}$ 以及 监督学习的方法来训练 $d_n$。
1. Candidate dections:
候选检测是利用反向传播来训练,已得到最大化每个 candidate 的得分。我们希望最大化 correctness,而不管是否一个 candidate 被无限的发射,因为 candidate 编码了 agent's 关于 actions 的hypotheses。这需要在训练的时候,将每一个候选 和 gt instance 进行匹配。我们利用一个观察:at each timestep, the agent should form a hyposis around the action instance (if any) nearest its current location in the video. 这使得我们可以设计一个简单有效的匹配算法。
Matching to ground truth.
给定一组候选检测 D,这些候选检测是由 RNN 走了 N 个时间步骤得到的,给定的 gt action instance g1, ... M, 每一个候选和一个 gt instance 匹配,否则,如果M=0,则为 none 。
我们定义 matching function 如下:

换句话说,
Loss function (损失函数):
一旦 candidate detections 已经和 gt instance 进行了匹配,我们优化一个 multi-task classification and localization loss function over the set D:
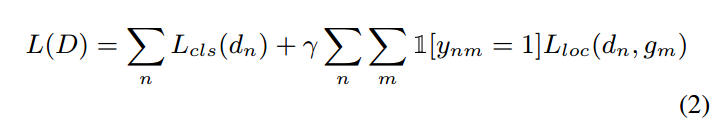
此处,分类项 $L_{cls(d_n)}$ 是检测置信度 $c_n$ 的 标准交叉熵损失函数,当匹配 dn 和一个 gt instance 匹配上的时候,就鼓励 the confidence 接近1,否则就是 0。
此处的 matching function 其实不是那么容易理解,要注意每个细节,不然太容易懵逼了。。。
该 loss function 是根据反向传播进行优化的。
2. Observation and emission sequences :
the observation location and prediction indicator output 是不可倒的,无法利用反向传播进行求解优化。

然后作者对 RL 算法进行了简介,指出目标函数不可导的原因在于:
this leads to a non-trivial optimization problem due to the high-dimensional space of possible action sequences.
REINFORCE 之所以可以解决这个问题,是因为:通过MC采样,来学习网络的参数,他对梯度等式进行了估计:

其中,一般都会减去一个 baseline,以降低方差:

REINFORCE learns model parameters according to this approximate gradient. The log-probability log πθ of actions leading to high future reward are increased, and those leading to low reward are decreased. Model parameters can then be updated using backpropagation.
Reward Function:
此处,训练 REINFORCE 需要设计合适的奖励函数。我们的目标是学习一个策略,对于 location and prediction indicator outputs,可以得到的 action detection 更高的 recall,以及更好的精度(high precision)。所以我们的奖励函数,就设计的是要去寻找这个策略,可以使得:最大化 true positive detections, 与此同时,最小化 false positive:
在第 Nth 时间步骤,提供所有的奖励,而对于 n < N, 则全为 0,因为我们想要学习的策略可以联合的得到 high overall detection performance. M 是 gt action instance 的个数,Np 是 agent 发射的预测的个数。N+ 是 true positive predictions 的个数;N- 是false positive predictions 的个数,R+ and R- 是这些预测带来的 positive and negative rewards。
A prediction is considered correct if its overlap with a ground truth is both greater than a threshold and higher than that of any other prediction.
论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos的更多相关文章
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- 论文阅读 | Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition
源地址 arXiv:1712.07465: Recurrent Attentional Reinforcement Learning for Multi-label Image Recognition ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- [论文阅读] A Discriminative Feature Learning Approach for Deep Face Recognition (Center Loss)
原文: A Discriminative Feature Learning Approach for Deep Face Recognition 用于人脸识别的center loss. 1)同时学习每 ...
- 【CV论文阅读】Dynamic image networks for action recognition
论文的重点在于后面approximation部分. 在<Rank Pooling>的论文中提到,可以通过训练RankSVM获得参数向量d,来作为视频帧序列的representation.而 ...
- 论文阅读 | DeepDrawing: A Deep Learning Approach to Graph Drawing
作者:Yong Wang, Zhihua Jin, Qianwen Wang, Weiwei Cui, Tengfei Ma and Huamin Qu 本文发表于VIS2019, 来自于香港科技大学 ...
- 【CV论文阅读】YOLO:Unified, Real-Time Object Detection
YOLO的一大特点就是快,在处理上可以达到完全的实时.原因在于它整个检测方法非常的简洁,使用回归的方法,直接在原图上进行目标检测与定位. 多任务检测: 网络把目标检测与定位统一到一个深度网络中,而且可 ...
- 【CV论文阅读】Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
由RCNN到FAST RCNN一个很重要的进步是实现了多任务的训练,但是仍然使用Selective Search算法来获得ROI,而FASTER RCNN就是把获得ROI的步骤使用一个深度网络RPN来 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
随机推荐
- 【Hadoop学习之三】Hadoop全分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop3.1.1 全分布式就是集群,注意配置主机名. ...
- 1、第一个android APP
https://blog.csdn.net/tongyong128/article/details/68484726
- java springboot activemq 邮件短信微服务,解决国际化服务的国内外兼容性问题,含各服务商调研情况
java springboot activemq 邮件短信微服务,解决国际化服务的国内外兼容性问题,含各服务商调研情况 邮件短信微服务 spring boot 微服务 接收json格式参数 验证参数合 ...
- css的优先级 和 权重
之前写页面样式时,有时会遇到 用多条样式定义规则对同一个元素进行样式设置的时候,当时想到的就是 按css选择器的优先级来搞定这个问题,说实话当时也就只记得 内嵌样式 > id > cla ...
- SpringBoot整合redis哨兵主从服务
前提环境: 主从配置 http://www.cnblogs.com/zwcry/p/9046207.html 哨兵配置 https://www.cnblogs.com/zwcry/p/9134721. ...
- Django MTV simple_tag filter inclusion_tag
Django框架 模型(Model).视图(View)和控制器(Controller),具有耦合性低.重用性高.生命周期成本低等优点. MVC 框架 -- Model -View -Controll ...
- eclipse格式化代码样式
1.Window->Preferences //Java 格式化 2.Java->Code Style->Formatter->New->Edit->Line Wr ...
- Java 注释规范
基本的要求: 1.注释形式统一 在整个应用程序中,使用具有一致的标点和结构的样式来构造注释.如果在其它项目中发现它们的注释规范与这份文档不同,按照这份规范写代码,不要试图在既成的规范系统中引入新的规范 ...
- node.js的on、emit、off封装
//绑定事件.触发事件和移除事件 //绑定事件 //on(eventName,cb){} //第一步判断当前事件是否存在,如果不存在则初始化:key:[],然后在将回调函数添加到数据中去 let ev ...
- 关于Eclipse新建Dynamic Web Projecj默认未创建web.xml的问题
当使用eclipse新建Dynamic Web Projecj时,由于J2EE技术规范的更新,当使用Dynamic web module version默认版本为3.0时,将默认不会创建web.xml ...