【转载】 强化学习(二)马尔科夫决策过程(MDP)
原文地址:
https://www.cnblogs.com/pinard/p/9426283.html
---------------------------------------------------------------------------------------
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素。但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策过程(Markov Decision Process,以下简称MDP)来简化强化学习的建模。
MDP这一篇对应Sutton书的第三章和UCL强化学习课程的第二讲。
1. 强化学习引入MDP的原因

对于马尔科夫性本身,我之前讲过的隐马尔科夫模型HMM(一)HMM模型,条件随机场CRF(一)从随机场到线性链条件随机场以及MCMC(二)马尔科夫链都有讲到。它本身是一个比较简单的假设,因此这里就不专门对“马尔可夫性”做专门的讲述了。

2. MDP的价值函数与贝尔曼方程

3. 状态价值函数与动作价值函数的递推关系

通俗说就是状态动作价值有两部分相加组成,第一部分是即时奖励,第二部分是环境所有可能出现的下一个状态的概率乘以该下一状态的状态价值,最后求和,并加上衰减。
这两个转化过程也可以从下图中直观的看出:
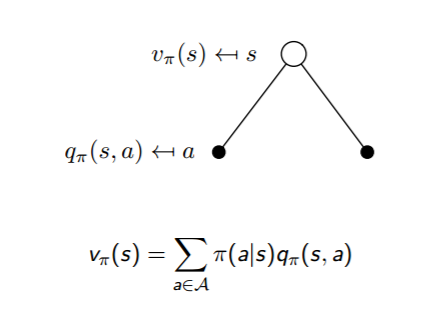

把上面两个式子互相结合起来,我们可以得到:

4. 最优价值函数

如何比较策略的优劣呢?一般是通过对应的价值函数来比较的,也就是说,寻找较优策略可以通过寻找较优的价值函数来完成。可以定义最优状态价值函数是所有策略下产生的众多状态价值函数中的最大者,即:

同理也可以定义最优动作价值函数是所有策略下产生的众多动作状态价值函数中的最大者,即:

对于最优的策略,基于动作价值函数我们可以定义为:
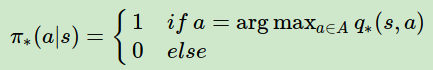
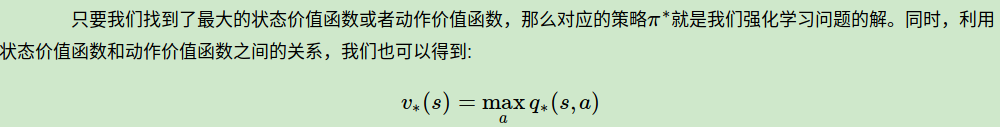
反过来的最优价值函数关系也很容易得到:

利用上面的两个式子也可以得到和第三节末尾类似的式子:
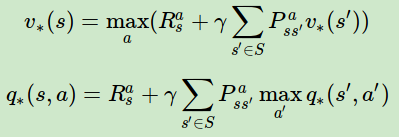
5. MDP实例
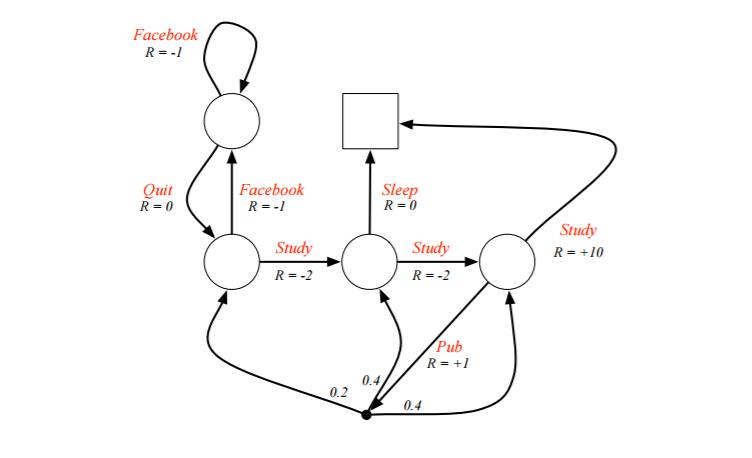
例子是一个学生学习考试的MDP。里面左下那个圆圈位置是起点,方框那个位置是终点。上面的动作有study, pub, facebook, quit, sleep,每个状态动作对应的即时奖励R已经标出来了。我们的目标是找到最优的动作价值函数或者状态价值函数,进而找出最优的策略。




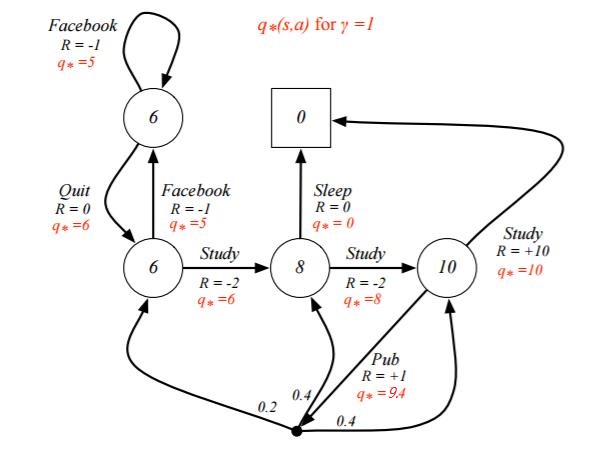
从而我们的最优决策路径是走6->6->8->10->结束。
6. MDP小结
MDP是强化学习入门的关键一步,如果这部分研究的比较清楚,后面的学习就会容易很多。因此值得多些时间在这里。虽然MDP可以直接用方程组来直接求解简单的问题,但是更复杂的问题却没有办法求解,因此我们还需要寻找其他有效的求解强化学习的方法。
下一篇讨论用动态规划的方法来求解强化学习的问题。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)
------------------------------------------------------------------------------------------------------------
【转载】 强化学习(二)马尔科夫决策过程(MDP)的更多相关文章
- 强化学习 1 --- 马尔科夫决策过程详解(MDP)
强化学习 --- 马尔科夫决策过程(MDP) 1.强化学习介绍 强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境 ...
- 强化学习(二)马尔科夫决策过程(MDP)
在强化学习(一)模型基础中,我们讲到了强化学习模型的8个基本要素.但是仅凭这些要素还是无法使用强化学习来帮助我们解决问题的, 在讲到模型训练前,模型的简化也很重要,这一篇主要就是讲如何利用马尔科夫决策 ...
- 【强化学习】MOVE37-Introduction(导论)/马尔科夫链/马尔科夫决策过程
写在前面的话:从今日起,我会边跟着硅谷大牛Siraj的MOVE 37系列课程学习Reinforcement Learning(强化学习算法),边更新这个系列.课程包含视频和文字,课堂笔记会按视频为单位 ...
- MCMC(二)马尔科夫链
MCMC(一)蒙特卡罗方法 MCMC(二)马尔科夫链 MCMC(三)M-H采样和Gibbs采样(待填坑) 在MCMC(一)蒙特卡罗方法中,我们讲到了如何用蒙特卡罗方法来随机模拟求解一些复杂的连续积分或 ...
- 强化学习(一)—— 基本概念及马尔科夫决策过程(MDP)
1.策略与环境模型 强化学习是继监督学习和无监督学习之后的第三种机器学习方法.强化学习的整个过程如下图所示: 具体的过程可以分解为三个步骤: 1)根据当前的状态 $s_t$ 选择要执行的动作 $ a_ ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- 机器学习理论基础学习13--- 隐马尔科夫模型 (HMM)
隐含马尔可夫模型并不是俄罗斯数学家马尔可夫发明的,而是美国数学家鲍姆提出的,隐含马尔可夫模型的训练方法(鲍姆-韦尔奇算法)也是以他名字命名的.隐含马尔可夫模型一直被认为是解决大多数自然语言处理问题最为 ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
随机推荐
- 数据结构与算法之PHP查找算法(哈希查找)
一.哈希查找的定义 提起哈希,我第一印象就是PHP里的关联数组,它是由一组key/value的键值对组成的集合,应用了散列技术. 哈希表的定义如下: 哈希表(Hash table,也叫散列表),是根据 ...
- https 不会被中间人攻击——因为中间人即使拿到了数据,也是加密的
只要你登陆了一个使用 HTTPS 数据加密的网站,浏览的页面的内容如果被人中途看见,将会是一团乱码.它也能保证,你浏览的页面就是你想浏览的,不会被黑客在中途修改,网站收到的数据包也是你最初发的那个,不 ...
- WebGoat 8安装、配置、使用教程(CentOS)
一.说明 1.1 背景说明 之前只用过dvwa,听说WebGoat也是类似的平台后,想装来试试有没有什么异同. 看了下载文件,和网上官方的.非官方的安装教程,感觉很多都对不上: 最后发现WebGoat ...
- ffmpeg录制流媒体,正常方式停止录制
QProcess m_Process; m_Process.setProcessChannelMode(QProcess::MergedChannels); //拼接命令行字符串 QString cm ...
- window.open打开新窗口 参数
1,基本描述 oNewWindow = window.open( sURL , sName , sFeatures, bReplace) window.open在打开一个窗口(其url为sURL)后, ...
- laravel创建资源路由控制器
php artisan make:controller PhotoController --resource
- NOI2019冬令营报到通知
由中国计算机学会(CCF)主办的2019全国青少年信息学奥林匹克冬令营(CCF NOI 2019冬令营)将于2019年1月24日-31日在广州市第二中学举行.其中1月24日为报到日,1月31日为疏散日 ...
- UVa 10891 - Game of Sum 动态规划,博弈 难度: 0
题目 https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem&a ...
- python if elif else判断语句
username = 'jack' password = ' _username = input('username') _password = input('password') if userna ...
- .net core webapi 配置swagger调试界面
一.创建一个.net core webapi的项目: 二.在nuget程序包管理器控制台输入 Install-Package Swashbuckle -version 6.0.0-beta902 ...