python+rabbitMQ实现生产者和消费者模式
(一)安装一个消息中间件,如:rabbitMQ
(二)生产者
sendmq.py
import pika
import sys
import time # 远程rabbitmq服务的配置信息
username = 'admin' # 指定远程rabbitmq的用户名密码
pwd = 'admin'
ip_addr = '10.1.7.7'
port_num = 5672 # 消息队列服务的连接和队列的创建
credentials = pika.PlainCredentials(username, pwd)
connection = pika.BlockingConnection(pika.ConnectionParameters(ip_addr, port_num, '/', credentials))
channel = connection.channel()
# 创建一个名为balance的队列,对queue进行durable持久化设为True(持久化第一步)
channel.queue_declare(queue='balance', durable=True) message_str = 'Hello World!'
for i in range(100000000):
# n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange.
channel.basic_publish(
exchange='',
routing_key='balance', # 写明将消息发送给队列balance
body=message_str, # 要发送的消息
properties=pika.BasicProperties(delivery_mode=2, ) # 设置消息持久化(持久化第二步),将要发送的消息的属性标记为2,表示该消息要持久化
) # 向消息队列发送一条消息
print(" [%s] Sent 'Hello World!'" % i)
# time.sleep(0.2)
connection.close() # 关闭消息队列服务的连接
运行sendmq.py文件,可以从以下方法查看队列中的消息数量。
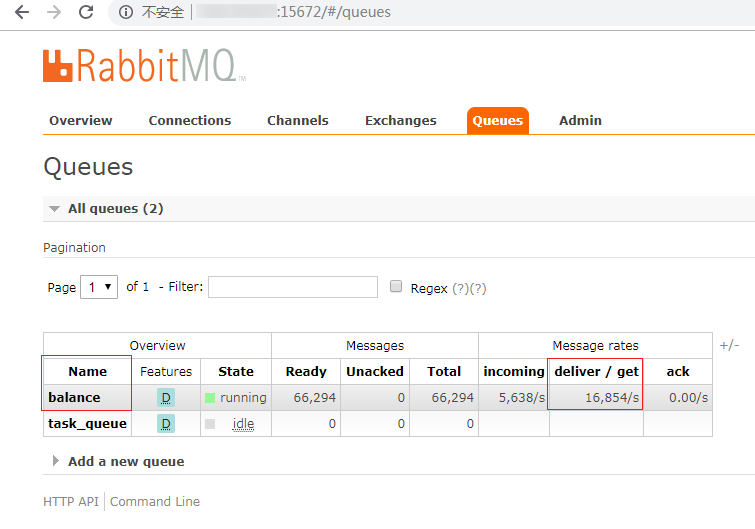
一是,rabbitmq的管理界面,如下图所示:

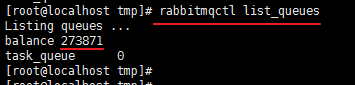
二是,从服务器端命令查看
rabbitmqctl list_queues
(三)消费者
receivemq.py
import pika
import sys
import time # 远程rabbitmq服务的配置信息
username = 'admin' # 指定远程rabbitmq的用户名密码
pwd = 'admin'
ip_addr = '10.1.7.7'
port_num = 5672 credentials = pika.PlainCredentials(username, pwd)
connection = pika.BlockingConnection(pika.ConnectionParameters(ip_addr, port_num, '/', credentials))
channel = connection.channel() # 消费成功的回调函数
def callback(ch, method, properties, body):
print(" [%s] Received %r" % (time.time(), body))
# time.sleep(0.2) # 开始依次消费balance队列中的消息
channel.basic_consume(queue='balance', on_message_callback=callback, auto_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 启动消费
运行receivemq.py文件,可以从以下方法查看队列中的消息数量。
或者
rabbitmqctl list_queues
延伸:
systemctl status rabbitmq-server.service # 状态
systemctl restart rabbitmq-server.service # 重启
python+rabbitMQ实现生产者和消费者模式的更多相关文章
- 使用libuv实现生产者和消费者模式
生产者和消费者模式(Consumer + Producer model) 用于把耗时操作(生产线程),分配给一个或者多个额外线程执行(消费线程),从而提高生产线程的响应速度(并发能力) 定义 type ...
- java生产者与消费者模式
前言: 生产者和消费者模式是我们在学习多线程中很经典的一个模式,它主要分为生产者和消费者,分别是两个线程, 目录 一:生产者和消费者模式简介 二:生产者和消费者模式的实现 声明:本例来源于java经典 ...
- condition版生产者与消费者模式
1.简介 在爬虫中,生产者与消费者模式是经常用到的.我能想到的比较好的办法是使用redis或者mongodb数据库构造生产者消费者模型.如果直接起线程进行构造生产者消费者模型,线程容易假死,也难以构造 ...
- python queue和生产者和消费者模型
queue队列 当必须安全地在多个线程之间交换信息时,队列在线程编程中特别有用. class queue.Queue(maxsize=0) #先入先出 class queue.LifoQueue(ma ...
- Java并发编程(4)--生产者与消费者模式介绍
一.前言 这种模式在生活是最常见的,那么它的场景是什么样的呢? 下面是我假象的,假设有一个仓库,仓库有一个生产者和一个消费者,消费者过来消费的时候会检测仓库中是否有库存,如果没有了则等待生产,如果有就 ...
- Java多线程设计模式(2)生产者与消费者模式
1 Producer-Consumer Pattern Producer-Consumer Pattern主要就是在生产者与消费者之间建立一个“桥梁参与者”,用来解决生产者线程与消费者线程之间速度的不 ...
- 【爬虫】Condition版的生产者和消费者模式
Condition版的生产者和消费者模式 threading.Condition 在没有数据的时候处于阻塞状态,有数据可以使用notify的函数通知等等待状态的线程运作 threading.Condi ...
- 【爬虫】Load版的生产者和消费者模式
''' Lock版的生产者和消费者模式 ''' import threading import random import time gMoney = 1000 # 原始金额 gLoad = thre ...
- java 线程并发(生产者、消费者模式)
线程并发协作(生产者/消费者模式) 多线程环境下,我们经常需要多个线程的并发和协作.这个时候,就需要了解一个重要的多线程并发协作模型“生产者/消费者模式”. Ø 什么是生产者? 生产者指的是负责生产数 ...
随机推荐
- Windows 8(64位)如何搭建 Android 开发环境与真机测试(转)
可以参考http://wenku.baidu.com/link?url=ghU6IFS1WJXLFKfM_0efv9YQEnMDBrdi9CXwirSs5IOLLeUfdIOh8OOVv0DX89Lt ...
- Oracle relink 重新编译
如此而已! export ORACLE_HOME=/opt/oracle/11.2 export LD_LIBRARY_PATH=/lib:/lib64:$ORACLE_HOME/lib:$ORACL ...
- [Node.js] 04 - Event and Callback
回调函数 回调函数在完成任务后就会被调用,Node 使用了大量的回调函数,Node 所有 API 都支持回调函数. 异步读取文件的回调函数: var fs = require("fs&quo ...
- Spring 整合 Junit4 进行单元测试
1. pom.xml 引入JAR依赖: <dependency> <groupId>junit</groupId> <artifactId>junit& ...
- IDEA导入springboot项目不能启动
由于工具没有识别到项目的pom.xml文件,所以需要在右侧的Maven栏目中点击 + 号,选中项目的pom.xml文件,则导入成功.
- 一次项目实践中DBCP数据库连接池性能优化
关于数据库连接池DBCP的关注源于刚刚结束的一轮测试,测试内容是衡量某Webserver服务创建用户接口的性能.这是一款典型的tomcat应用,使用的测试工具是Grinder.DBCP作为tomcat ...
- java中Date与DateFormat的格式输出
一.DateFormat java.text.DateFormat 使用 getDateInstance 来获取该国家/地区的标准日期格式.另外还提供了一些其他静态工厂方法.使用 getTimeIns ...
- 初窥scrapy爬虫
2017-10-30 21:49:55 前言: 初步使用scrapy爬虫框架,爬取各个网站信息 系统环境: 64位win10系统,装有64位python3.6,IDE为pycharm,使用cmd命令 ...
- thinkPHP框架 简单的删除和修改数据的做法 和 模板继承的意思大概做法
BiaodanController.class.php控制器页面 <?php namespace Admin\Controller; use think\Controller; class Bi ...
- CentOS7(linux) 通过服务名查询安装目录
#ps aux|grep nginx root 1231 0.0 0.0 46336 956 ? Ss 04:21 0:00 nginx: master process /usr/sbin/nginx ...