Scrapy终端(Scrapy shell)
1.介绍文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html#
2.终端的启用方式:scrapy shell url
url 即为你要爬取的网站
3.使用scrapy shell遇到的问题

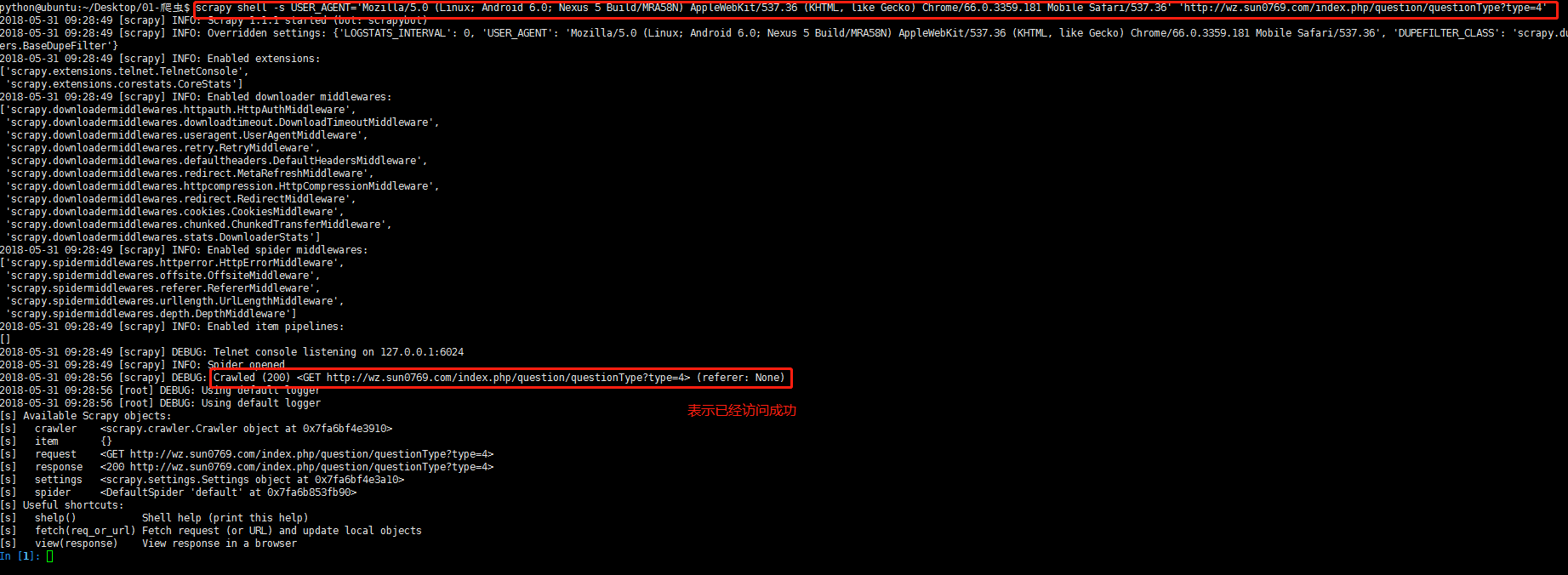
当用scrapy shell访问如上图的链接时,报出如下错误:
DEBUG: Crawled (504) <GET http://wz.sun0769.com/index.php/question/questionType?type=4> (referer: None) ['partial']
最终发现问题的根源是user-agent:我们在使用scrapy shell进行爬虫调试的时候,user-agent的配置在默认的全局设置中
全局默认值位于scrapy.settings.default_settings 模块中,如下图:

解决方案1:将default_settings.py中的USER_AGENT修改为任意一个浏览器的user-agent
解决方案2:我们在终端输入scrapy shell --help有可以看到有一个选项为-s即为在启动爬虫的时候对默认的default_settings文件
中的设置项进行覆盖;
在终端键入:scrapy shell -s USER_AGENT='Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36' 'http://wz.sun0769.com/index.php/question/questionType?type=4',问题即看得到解决。
应该注意的是 USER_AGENT的等号不能有空格
Scrapy终端(Scrapy shell)的更多相关文章
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- 爬虫:Scrapy7 - Scrapy终端(Scrapy shell)
Scrapy 终端是一个交互终端,可以在未启动 spider 的情况下尝试及调试你的爬取代码.其本意是用来测试提取数据的代码,不过可以将其作为正常的 Python 终端,在上面测试任何 Python ...
- Scrapy之Scrapy shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- scrapy框架之shell
scrapy shell scrapy shell是一个交互式shell,您可以在其中快速调试 scrape 代码,而不必运行spider.它本来是用来测试数据提取代码的,但实际上您可以使用它来测试任 ...
- Scrapy 常用的shell执行命令
1.在任意系统下,可以使用 pip 安装 Scrapy pip install scrapy/ 确认安装成功 >>> import scrapy >>> scrap ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- <scrapy爬虫>scrapy命令行操作
1.mysql数据库 2.mongoDB数据库 3.redis数据库 1.创建项目 scrapy startproject myproject cd myproject 2.创建爬虫 scrapy g ...
- Linux终端执行shell脚本,提示权限不够的解决办法
原文:http://blog.csdn.net/this_capslock/article/details/17415409 今天在Linux尝试搭建dynamips的工作环境,在执行shell脚本时 ...
- scrapy - 给scrapy 的spider 传值
scrapy - 给scrapy 的spider 传值 方法一: 在命令行用crawl控制spider爬取的时候,加上-a选项,例如: scrapy crawl myspider -a categor ...
随机推荐
- 执行python程序 出现三部曲
1.执行一个python程序 ,会产生一个进程 ,然后会在内存生成一份内存空间 先把python解释器代码加载到内存里, python解释器代码就是C语言代码 2. 然后再把 自己写的python文件 ...
- Mybatis 1.原理流程图
仅用来做个人笔记记录. 总流程: 根据配置文件(全局配置文件和sql映射文件)初始化configuration对象. 创建一个defaultSqlSession对象,包含Configuration及E ...
- [LeetCode] 228. 汇总区间
题目链接: https://leetcode-cn.com/problems/summary-ranges 难度:中等 通过率:48.9% 题目描述: 给定一个无重复元素的有序整数数组,返回数组区间范 ...
- 工作中常用到的JS验证
Common.js // JavaScript Document // _ooOoo_ // o8888888o // 88" . "88 // (| -_- |) // O\ = ...
- JavaScript应懂的概念
目录 垃圾回收 函数作用域, 块级作用域和词法作用域 调用堆栈 原始类型 值类型和引用类型 隐式, 显式, 名义和鸭子类型 == 与 ===, typeof 与 instanceof this, ca ...
- MySQL on duplicate key update 批量插入并更新已存在数据
业务上经常存在一种现象,需要批量往表中插入多条数据,但在执行过程中,很可能因为唯一键冲突,而导致批量插入失败.因此需要事先判断哪些数据是重复的,哪些是新增的.比较常用的处理方法就是找出已存在的数据,并 ...
- decodeURI decodeURIComponent
操作 url 常用到编码与解码,一一对应就好 给力文章
- php strip_tags() 函数去除 HTML、XML 以及 PHP 的标签。
strip_tags() 函数剥去 HTML.XML 以及 PHP 的标签.strip_tags(string,allow)参数 描述string 必需.规定要检查的字符串.allow ...
- Django学习系列5:为视图编写单元测试
打开lists/tests.py编写 """向浏览器返回真正的HTML响应,添加一个新的测试方法""" from django.test i ...
- vue项目中利用popstate处理页面返回操作
需求背景:项目中需要做一个返回确认,避免用户误触返回键而退出当前页面. 原理:利用history和浏览器刷新popstate状态 实现: 1.在mounted() 阶段判断并添加popstate事件监 ...