Python爬虫数据保存到MongoDB中
MongoDB是一款由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储方式类似于JSON对象,它的字段值可以是其它文档或数组,但其数据类型只能是String文本型。
在使用之前我们要确保已经安装好了MongoDB并启动了该服务。此处主要用于Python数据的保存,我们要安装Python的PyMongo库,运行 ‘pip install pymongo’ 命令完成pymongo的安装。进入python工作模式,可以通过pymongo.version 查看pymongo的版本信息。
第一步,连接MongoDB
我们通过PyMongo库里的MongoClient。其中第一个参数 host 是mongodb的地址,第二个参数是端口 port (不传参数的话默认是27017)
client = pymongo.MongoClient(host='127.0.0.1',port=27017)
另一种方法是直接传递MongoDB的连接字符串,以 mongodb 开头。
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
第二步,选择数据库或集合
在MongoDB中可以建立多个数据库,其中每个数据库又包含许多集合,类似于关系数据库中的表。选择数据库有两种方法,这两种方法作用相同。
db = client.test # test数据库
db = client['test']
选择好数据库后我们需要指定要操作的集合,与数据库的选择类似。
p = db.persons # persons集合
p = db['persons']
第三步,添加数据
person = {
'id':'',
'name':'Abc',
'age':19
}
result = p.insert(person)
# 在PyMongo 3.x版本后,官方推荐使用insert_one(),该方法返回的不再是单纯的_id值,我们需要执行result.inserted_id查看 _id 值
print(result)
此处通过对象的 insert() 方法添加了一条数据,添加成功后返回的是数据插入过程中自动添加的 _id 属性值,这个值是唯一的。另外我们还可以添加多条数据,它以列表的形式进行传递。
person = {
'id':'',
'name':'Abc',
'age':19
}
person1 = {
'id':'',
'name':'Dfg',
'age':20
}
result = p.insert([person,person1])
# 推荐使用 insert_many() 方法,之后使用 result.inserted_ids 查看插入数据的 _id 列表
print(result)
第四步,查询数据
查询数据我们可以使用 find_one() 或 find() 方法,其中 find_one() 得到的是单个数据结果,find() 返回的是一个生成器对象。
res = p.find_one({'name':'Abc'}) # 查询 name 为 Abc 的人的信息,返回字典型的数据
print(res)
find() 则用来查询多条数据,返回 cursor 类型的生存器,我们要遍历取得所有的数据结果。
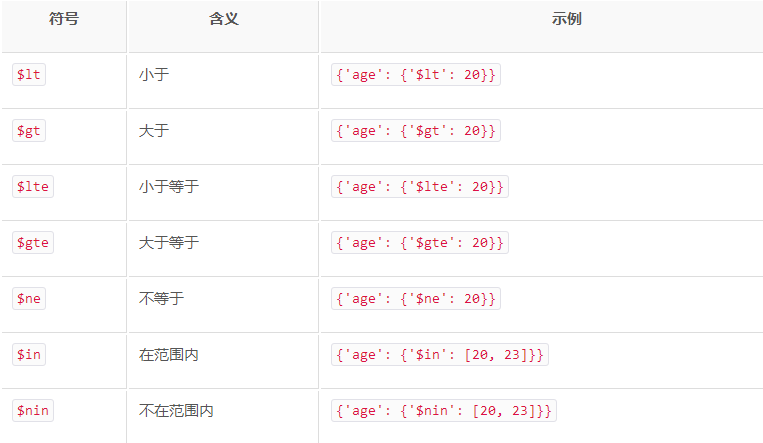
res = p.find({'age':20}) # 查询集合中age是20的数据
# res = p.find({'age':{'$gt':20}}) # 查询集合中age大于20的数据
print(res)
for r in res:
print(r)
另外,我们还可以通过正则匹配进行查询。
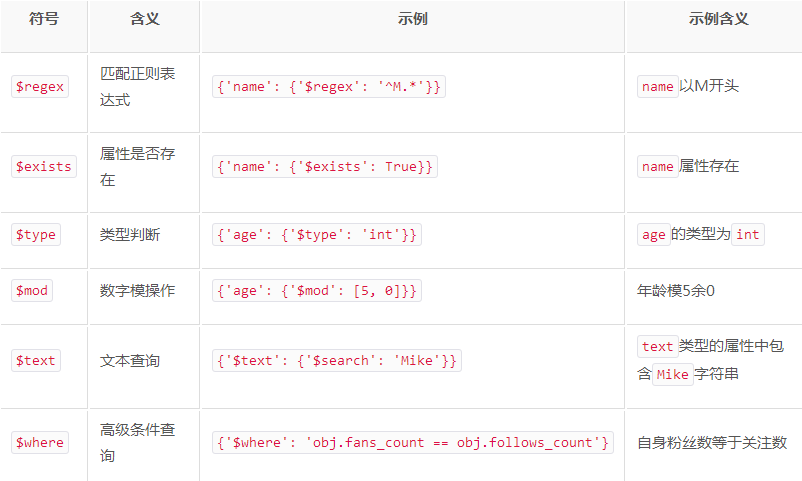
res = p.find({'name':{'$regex':'^A.*'}}) # 查询集合中name以A开头的数据
要统计查询的结果一共有多少条数据,需要使用 count() 方法
count = p.find().count() # 统计集合中所有数据条数
排序则直接调用 sort() 方法,根据需求传入升序降序标志即可
res = p.find().sort('age',pymongo.ASCENDING) # 将集合中的数据根据age进行排序,pymongo.ASCENDING表示升序,pymongo.DESCENDING表示降序
当我们只需要取得几个元素时,我们可以使用 skip() 方法偏移几个位置,得到去掉偏移个数之后剩下的元素数据
res = p.find({'name':{'$regex':'^A.*'}}).skip(2)
print([ r['name'] for r in res ]) # 打印name以A开头的数据的名称name,从第三个显示
第五步,更新数据
更新数据我们使用 update() 方法实现,并指定更新的条件和需要更新的数据即可。
where = {'name':'Abc'}
res = p.find_one(where)
res['age'] = 25
result = p.update(where, res) # 推荐使用 update_one() 或 update_many()
print(result)
返回的是一个字典形式的数据,{'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True},其中 ok 表示执行成功,nModified 表示影响的数据条数。
另外我们还可以使用 $set 操作符对数据进行更新。使用$set则只更新字典内存在的字段,其它字段则不更新,也不删除。如果不用则会更新所有的数据,而其它存在的字段则会被删除。
where = {'age':{'$gt':20}}
result = p.update_many(where,{'$inc':{'age':1}}) # 将集合中年龄大于20的第一条的数据年龄加1
print(result)
print(result.matched_count,result.modified_count) # 获取匹配的数据条数,影响的数据条数
第六步,删除数据
删除数据可以调用 remove() 方法,需要指定删除条件。
result = p.remove({'name':'Abc'}) # 删除名称为Abc的数据,推荐使用 delete_one() 和 delete_many(),执行后调用 result.delete_count,获得删除的数据条数
返回的是一条字典型数据,{'ok':1,'n':1}
另外,我们还可以对索引进行操作,比如 create_index() 创建单个索引,create_indexes()创建多个索引,drop_index()删除索引等方法。
参考:静觅博客 https://cuiqingcai.com/5584.html
Python爬虫数据保存到MongoDB中的更多相关文章
- 在scrapy中将数据保存到mongodb中
利用item pipeline可以实现将数据存入数据库的操作,可以创建一个关于数据库的item pipeline 需要在类属性中定义两个常量 DB_URL:数据库的URL地址 DB_NAME:数据库的 ...
- Python将数据保存到CSV中
#coding:utf-8import csv headers = ['ID','UserName','Password','Age','Country'] rows = [(1001,'qiye', ...
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- Excel文件数据保存到SQL中
1.获取DataTable /// <summary> /// 查询Excel文件中的数据 /// </summary> /// <param name="st ...
- 将爬取的数据保存到mysql中
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了 安装数据库 1.pip install pymysql(根据版本来装) 2.创建数据 打开终端 键入mysql -u root -p ...
- c# 抓取和解析网页,并将table数据保存到datatable中(其他格式也可以,自己去修改)
使用HtmlAgilityPack 基础请参考这篇博客:https://www.cnblogs.com/fishyues/p/10232822.html 下面是根据抓取的页面string 来解析并保存 ...
- Redis使用场景一,查询出的数据保存到Redis中,下次查询的时候直接从Redis中拿到数据。不用和数据库进行交互。
maven使用: <!--redis jar包--> <dependency> <groupId>redis.clients</groupId> < ...
随机推荐
- webapi接口统一返回请求时间
webapi接口统一返回请求时间: public class BaseController : ControllerBase { protected ReturnResult<T> Res ...
- 2019 CSP-S初赛游记
2019-10-19 ——这个注定要被载入史册的日子 作为一名初中生,和lpy大佬一同参加提高组的比赛,而今年普及组和提高组的时间竟然不一样,于是——凌晨六点半,来到了pdyz和高中生一起坐车去. 高 ...
- Python 入门之 Python三大器 之 生成器
Python 入门之 Python三大器 之 生成器 1.生成器 (1)什么是生成器? 核心:生成器的本质就是一个迭代器 迭代器是Python自带的 生成器程序员自己写的一种迭代器 def func( ...
- django的模板的继承与导入
1.模板继承 母版中需要继承的地方: {% block content %} {% endblock %} 对应的子版中文件最开头写: {% extends 'head_demo.html' %} 然 ...
- ubuntu系统更新命令
一.图形界面更新升级 1.点击”系统设置“,打开“软件和更新”,切到“更新”栏目进行更新设置. 2.可以通过软件更新器进行更新升级自己想要更新的 二.命令方式更新升级 1.先解锁 ps -e|grep ...
- scala学习笔记(4)映射和元组
1.构造映射 //构造这样的一个映射 val sources=Map(,,) //构造了一个不可变的Map[String,Int],值不能改变, //可变映射 val scores = new sca ...
- Pygame播放背景音乐与音效
1.播放背景音乐 pygame.mixer.music.load() 加载MP3格式 加入pygame.mixer.init()即可 第十一行第一个参数:播放次数(n>0),n=0时播放1次,- ...
- Java第三阶段复习
Java第三阶段复习: 1. Spring 1. IOC: 定义:Inverse Of Controller:反转控制,将bean对象的创建和对象之间的关联关系的维护由原来我们自己创建.自己维护反转给 ...
- R语言 绘图——条形图可以将堆积条形图与百分比堆积条形图配合使用
在使用堆积条形图时候,新增一个百分比堆积条形图,可以加深读者印象. 封装一个function函数后只需要在调用的数据上改一下pos=‘fill’的代码即可.比较方便. 案例: # 封装函数 fun1& ...
- oracle比较两个查询结果的差异
可以使用minus select * from A minus select * from B; select * from B minus select * from A;