Python爬虫数据保存到MongoDB中
MongoDB是一款由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储方式类似于JSON对象,它的字段值可以是其它文档或数组,但其数据类型只能是String文本型。
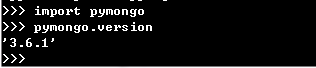
在使用之前我们要确保已经安装好了MongoDB并启动了该服务。此处主要用于Python数据的保存,我们要安装Python的PyMongo库,运行 ‘pip install pymongo’ 命令完成pymongo的安装。进入python工作模式,可以通过pymongo.version 查看pymongo的版本信息。
第一步,连接MongoDB
我们通过PyMongo库里的MongoClient。其中第一个参数 host 是mongodb的地址,第二个参数是端口 port (不传参数的话默认是27017)
client = pymongo.MongoClient(host='127.0.0.1',port=27017)
另一种方法是直接传递MongoDB的连接字符串,以 mongodb 开头。
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
第二步,选择数据库或集合
在MongoDB中可以建立多个数据库,其中每个数据库又包含许多集合,类似于关系数据库中的表。选择数据库有两种方法,这两种方法作用相同。
db = client.test # test数据库
db = client['test']
选择好数据库后我们需要指定要操作的集合,与数据库的选择类似。
p = db.persons # persons集合
p = db['persons']
第三步,添加数据
person = {
'id':'',
'name':'Abc',
'age':19
}
result = p.insert(person)
# 在PyMongo 3.x版本后,官方推荐使用insert_one(),该方法返回的不再是单纯的_id值,我们需要执行result.inserted_id查看 _id 值
print(result)
此处通过对象的 insert() 方法添加了一条数据,添加成功后返回的是数据插入过程中自动添加的 _id 属性值,这个值是唯一的。另外我们还可以添加多条数据,它以列表的形式进行传递。
person = {
'id':'',
'name':'Abc',
'age':19
}
person1 = {
'id':'',
'name':'Dfg',
'age':20
}
result = p.insert([person,person1])
# 推荐使用 insert_many() 方法,之后使用 result.inserted_ids 查看插入数据的 _id 列表
print(result)
第四步,查询数据
查询数据我们可以使用 find_one() 或 find() 方法,其中 find_one() 得到的是单个数据结果,find() 返回的是一个生成器对象。
res = p.find_one({'name':'Abc'}) # 查询 name 为 Abc 的人的信息,返回字典型的数据
print(res)
find() 则用来查询多条数据,返回 cursor 类型的生存器,我们要遍历取得所有的数据结果。
res = p.find({'age':20}) # 查询集合中age是20的数据
# res = p.find({'age':{'$gt':20}}) # 查询集合中age大于20的数据
print(res)
for r in res:
print(r)
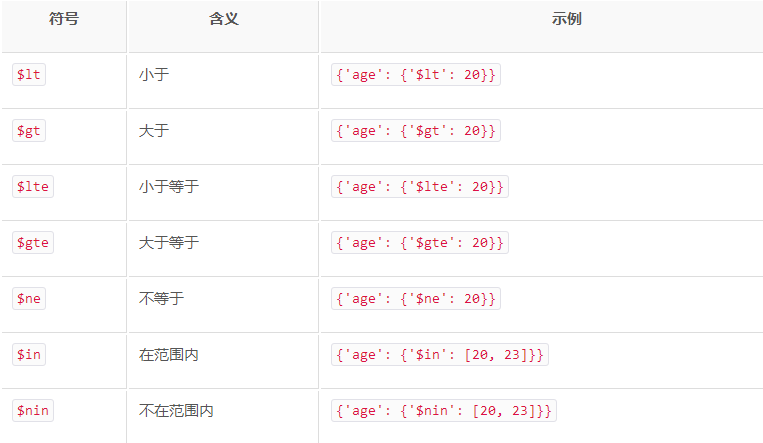
另外,我们还可以通过正则匹配进行查询。
res = p.find({'name':{'$regex':'^A.*'}}) # 查询集合中name以A开头的数据
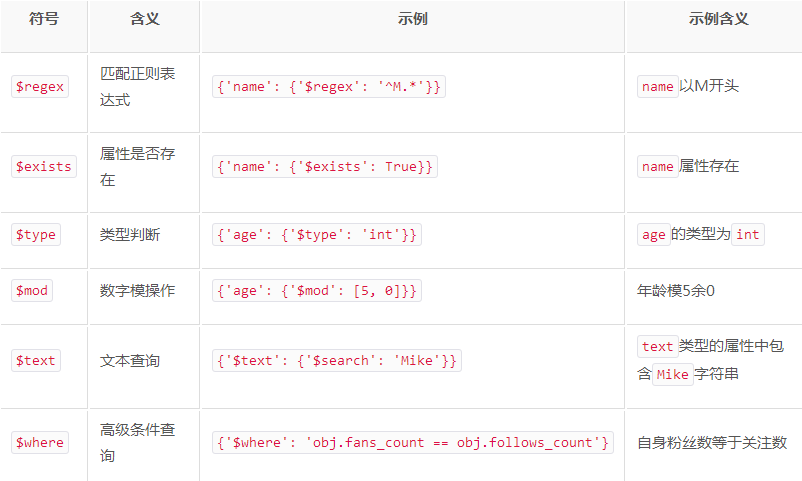
要统计查询的结果一共有多少条数据,需要使用 count() 方法
count = p.find().count() # 统计集合中所有数据条数
排序则直接调用 sort() 方法,根据需求传入升序降序标志即可
res = p.find().sort('age',pymongo.ASCENDING) # 将集合中的数据根据age进行排序,pymongo.ASCENDING表示升序,pymongo.DESCENDING表示降序
当我们只需要取得几个元素时,我们可以使用 skip() 方法偏移几个位置,得到去掉偏移个数之后剩下的元素数据
res = p.find({'name':{'$regex':'^A.*'}}).skip(2)
print([ r['name'] for r in res ]) # 打印name以A开头的数据的名称name,从第三个显示
第五步,更新数据
更新数据我们使用 update() 方法实现,并指定更新的条件和需要更新的数据即可。
where = {'name':'Abc'}
res = p.find_one(where)
res['age'] = 25
result = p.update(where, res) # 推荐使用 update_one() 或 update_many()
print(result)
返回的是一个字典形式的数据,{'ok': 1, 'nModified': 1, 'n': 1, 'updatedExisting': True},其中 ok 表示执行成功,nModified 表示影响的数据条数。
另外我们还可以使用 $set 操作符对数据进行更新。使用$set则只更新字典内存在的字段,其它字段则不更新,也不删除。如果不用则会更新所有的数据,而其它存在的字段则会被删除。
where = {'age':{'$gt':20}}
result = p.update_many(where,{'$inc':{'age':1}}) # 将集合中年龄大于20的第一条的数据年龄加1
print(result)
print(result.matched_count,result.modified_count) # 获取匹配的数据条数,影响的数据条数
第六步,删除数据
删除数据可以调用 remove() 方法,需要指定删除条件。
result = p.remove({'name':'Abc'}) # 删除名称为Abc的数据,推荐使用 delete_one() 和 delete_many(),执行后调用 result.delete_count,获得删除的数据条数
返回的是一条字典型数据,{'ok':1,'n':1}
另外,我们还可以对索引进行操作,比如 create_index() 创建单个索引,create_indexes()创建多个索引,drop_index()删除索引等方法。
参考:静觅博客 https://cuiqingcai.com/5584.html
Python爬虫数据保存到MongoDB中的更多相关文章
- 在scrapy中将数据保存到mongodb中
利用item pipeline可以实现将数据存入数据库的操作,可以创建一个关于数据库的item pipeline 需要在类属性中定义两个常量 DB_URL:数据库的URL地址 DB_NAME:数据库的 ...
- Python将数据保存到CSV中
#coding:utf-8import csv headers = ['ID','UserName','Password','Age','Country'] rows = [(1001,'qiye', ...
- 吴裕雄--天生自然python数据清洗与数据可视化:MYSQL、MongoDB数据库连接与查询、爬取天猫连衣裙数据保存到MongoDB
本博文使用的数据库是MySQL和MongoDB数据库.安装MySQL可以参照我的这篇博文:https://www.cnblogs.com/tszr/p/12112777.html 其中操作Mysql使 ...
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- Excel文件数据保存到SQL中
1.获取DataTable /// <summary> /// 查询Excel文件中的数据 /// </summary> /// <param name="st ...
- 将爬取的数据保存到mysql中
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了 安装数据库 1.pip install pymysql(根据版本来装) 2.创建数据 打开终端 键入mysql -u root -p ...
- c# 抓取和解析网页,并将table数据保存到datatable中(其他格式也可以,自己去修改)
使用HtmlAgilityPack 基础请参考这篇博客:https://www.cnblogs.com/fishyues/p/10232822.html 下面是根据抓取的页面string 来解析并保存 ...
- Redis使用场景一,查询出的数据保存到Redis中,下次查询的时候直接从Redis中拿到数据。不用和数据库进行交互。
maven使用: <!--redis jar包--> <dependency> <groupId>redis.clients</groupId> < ...
随机推荐
- 【LGR-065】洛谷11月月赛 III Div.2
临近$CSP$...... 下午打了一发月赛,感觉很爽. 非常菜的我只做了前两题......然而听说前两题人均过...... 写法不优秀被卡到$#1067$...... T1:基础字符串练习题: 前缀 ...
- laravel框架之增刪改查
<?php namespace App\Http\Controllers\admin; use Illuminate\Http\Request as request; use App\Http\ ...
- 面向对象super 练习
看代码写结果[如果有错误,则标注错误即可,并且假设程序报错可以继续执行] class Foo(object): a1 = 1 def __init__(self,num): self.num = nu ...
- 思维体操: HDU1049Climbing Worm
Climbing Worm Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) To ...
- Springboot+Jedis+Ehcache整合
项目结构概览: 1. 导包 <parent> <groupId>org.springframework.boot</groupId> <artifactId& ...
- CSS样式 换行
强制不换行 div{ white-space:nowrap; } 自动换行 div{ word-wrap: break-word; word-break: normal; } 强制英文单词断行 div ...
- js验证小数或者整数
利用正则表达式校验是否为小数或者整数,废话不多说直接上demo(此正则表达式无法校验负数和数字为00开头的数字). PS:(如果有不对之处,请批评指教) <!DOCTYPE html> & ...
- 详解 nginx.conf 配置文件
Nginx 配置文件主要分为 4 部分: Main 全局设置:影响其他所有设置 Server 主机设置:配置指定的主机和端口 Upstream 负载均衡服务器设置 :设置一系列的后置服务器 Locat ...
- MFC学习笔记1---准备工作
什么是MFC MFC,全称Microsoft Foundation Classes,微软基础类库,顾名思义,是微软的攻城狮们将一些常用的基础的Windows API 函数用C++的形式封装成类,简化程 ...
- Netty学习第三章 Linux网络编程使用的I/O模型
一.同步阻塞IO:blocking IO(BIO) 1.过程分析: 当进程进行系统调用时,内核就会去准备数据,当数据准备好后就复制数据到内核缓冲器,复制完成后将数据拷贝到用户进程内存,整个过程都是阻塞 ...