分布式ID生成器的解决方案总结
在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID、退款ID等。那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要的。下面我们一一来列举一下,不一定全部适合,这些解决方案仅供你参考,或许对你有用。
一个ID一般来说有下面几种要素:
- 唯一性:确保生成的ID是全网唯一的。
- 有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
- 高可用性:确保任何时候都能正确的生成ID。
- 带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
系统时间毫秒数
我们可以使用当前系统时间精确到毫秒数+业务属性+用户属性+随机数+…等参数组合形式来确保ID的唯一性,缺点是ID的有序性难以保证,要保证有序性就要依赖数据库或者其他中间存储媒介。
UUID
Java自带的生成UUID的方式就能生成一串唯一随机32位长度数据,而且够我们用N亿年,保证唯一性肯定是不用说的了,但缺点是它不包含时间、业务数据可读性太差了,而且也不能ID的有序递增。
这是一种简单的生成方式,简单,高效,但在一般业务系统中我还没见过有这种生成方式。
数据库自增ID
我们都知道为数据库主键设置自增序号,以一定的趋势自增,以保证主键ID的唯一性。
这个方案很简单,但最主要的问题在于依赖数据库本身,这就无形增加了对数据库的访问压力和依赖,一旦对单库进行分库分表或者数据迁移就尴尬了。
所以,这也不是合适的ID生成方法。
批量生成ID
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。这样就避免了每次生成ID都要访问数据库并带来压力。
这种方案服务就是单点了,如果服务重启势必会造成ID丢失不连续的情况,而且这种方式也不利于水平扩展。
中间件
Redis的所有命令操作都是单线程的,本身提供像incr这样的自增命令,所以能保证生成的ID肯定是唯一有序的。
这种方式不依赖关系数据库,而且速度快。但系统要引入Redis这一中间件,增加维护成本,而且编码和配置工作量比较大。即使已经有了Redis组件,但生成ID的高频率访问对单线程的Redis性能势必也会造成影响。
还可以利用像Zookeeper中的znode数据版本来生成序列号,及MongoDB的ObjectId等,这种利用中间件的做法不是很推荐。
snowflake算法
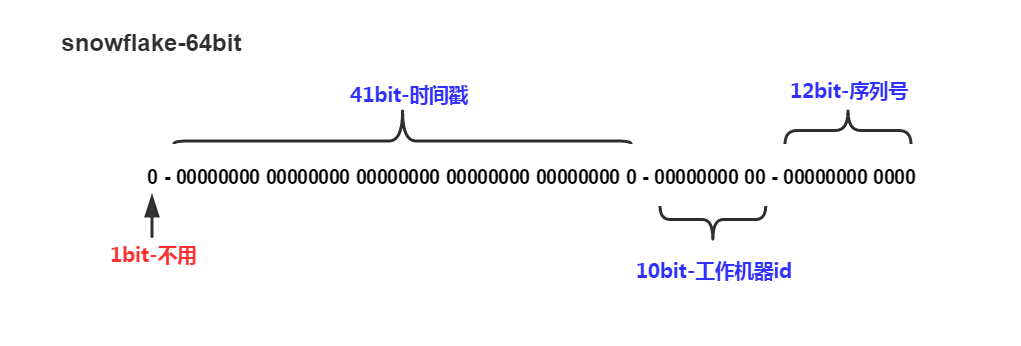
如上图的所示,Twitter的snowflake算法下面几部分组成:
- 41位的时间序列,精确到毫秒,可以使用69年
- 10位的机器标识,最多支持部署1024个节点
- 12位的序列号,支持每个节点每毫秒产生4096个ID序号,最高位是符号位始终为0。
这种方案性能好,在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
而且这个项目在2010就停止维护了,但这个设计思路还是应用于其他各个ID生成器及变种。
UidGenerator
UidGenerator是百度开源的分布式ID生成器,基于于snowflake算法的实现,看起来感觉还行。不过,国内开源的项目维护性真是担忧。
大家可以参考具体使用:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明:
好了,就这么多了,不同的方案应用的场景和系统也是不同的。大家有更好的方案也可以在下面留言,一起讨论下大家都是怎么做的。
推荐阅读
分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。
分布式ID生成器的解决方案总结的更多相关文章
- 常用的分布式ID生成器
为何需要分布式ID生成器 **本人博客网站 **IT小神 www.itxiaoshen.com **拿我们系统常用Mysql数据库来说,在之前的单体架构基本是单库结构,每个业务表的ID一般从1增,通过 ...
- c#分布式ID生成器
c#分布式ID生成器 简介 这个是根据twitter的snowflake来写的.这里有中文的介绍. 如上图所示,一个64位ID,除了最左边的符号位不用(固定为0,以保证生成的ID都是正数),还剩余 ...
- 基于redis的分布式ID生成器
基于redis的分布式ID生成器
- 分布式ID生成器PHP+Swoole实现(上) - 实现原理
1.发号器介绍 什么是发号器? 全局唯一ID生成器,主要用于分库分表唯一ID,分布式系统数据的唯一标识. 是否需要发号器? 1)是否需要全局唯一. 分布式系统应该不受单点递增ID限制,中心式的会涉及到 ...
- go语言实现分布式id生成器
本文:https://chai2010.cn/advanced-go-programming-book/ch6-cloud/ch6-01-dist-id.html 分布式id生成器 有时我们需要能够生 ...
- 来吧,自己动手撸一个分布式ID生成器组件
在经过了众多轮的面试之后,小林终于进入到了一家互联网公司的基础架构组,小林目前在公司有使用到架构组研究到分布式id生成器,前一阵子大概看了下其内部的实现,发现还是存在一些架构设计不合理之处.但是又由于 ...
- CosId 通用、灵活、高性能的分布式 ID 生成器
CosId 通用.灵活.高性能的分布式 ID 生成器 介绍 CosId 旨在提供通用.灵活.高性能的分布式系统 ID 生成器. 目前提供了俩大类 ID 生成器:SnowflakeId (单机 TPS ...
- CosId 1.0.0 发布,通用、灵活、高性能的分布式 ID 生成器
CosId 通用.灵活.高性能的分布式 ID 生成器 介绍 CosId 旨在提供通用.灵活.高性能的分布式系统 ID 生成器. 目前提供了俩大类 ID 生成器:SnowflakeId (单机 TPS ...
- CosId 1.0.3 发布,通用、灵活、高性能的分布式 ID 生成器
CosId 通用.灵活.高性能的分布式 ID 生成器 介绍 CosId 旨在提供通用.灵活.高性能的分布式系统 ID 生成器. 目前提供了俩大类 ID 生成器:SnowflakeId (单机 TPS ...
随机推荐
- java反射(三)--反射与操作类
一.反射与操作类 在反射机制的处理过程之中不仅仅只是一个实例化对象的处理操作,更多的情况下还有类的组成的操作,任何一个类的基本组成结构:父类(父接口),包,属性,方法(构造方法,普通方法)--获取类的 ...
- 04-初始mysql语句
本节课先对mysql的基本语法初体验. 操作文件夹(库) 增 create database db1 charset utf8; 查 # 查看当前创建的数据库 show create database ...
- 详解 CSS 绝对定位
基本定义和用法 在 CSS 中,position 属性指定一个元素(静态的,相对的,绝对或固定,以及粘性定位)的定位方法的类型. 当设置 position 属性的值为 absolute 时,生成绝对定 ...
- 62.Longest Valid Parentheses(最长的有效括号)
Level: Medium 题目描述: Given a string containing just the characters '(' and ')', find the length of ...
- C#设计模式:模板方法模式(Template Method)
一,我们为什么需要模板设计模式? 在程序设计中,可能每个对象都有共同的地方,而此时如果每个对象定义一次,如下例子,每个对象都写Stay()方法,这样在每个类中都有很多相同的代码,此时,我们需要用到模板 ...
- C# goto学习
如下代码: ; goto b;//goto语句用来控制程序跳转到某个标签的位置 a++; b: Console.WriteLine(a); Console.ReadKey(); 输出结果为:5,执行g ...
- ogeek babyrop
拖入ida 先用strncmp使一个随机数与输入比对,这里可以用\x00跳过strncmp 然后read()中的a1是我们输入\x00后的值 写exp from pwn import * sh=rem ...
- 使用 lombok 简化代码
使用前的准备 1.Lombok 是一种 Java™ 实用工具,可用来帮助开发人员消除 Java 的冗长,尤其是对于简单的 Java 对象(POJO).它通过注解实现这一目的. <1>添加 ...
- java 多线程间通信(一)
synchronized同步 package com.test7; public class Run { public class MyObject { private int a; public M ...
- 转载:Spring中各个JAR包的作用
(1) spring-core.jar 这个jar文件包含Spring框架基本的核心工具类,Spring其它组件要都要使用到这个包里的类,是其它组件的基本核心,当然你也可以在自己的应用系统中使用这些工 ...