2019-03-22 Python Scrapy 入门教程 笔记
Python Scrapy 入门教程
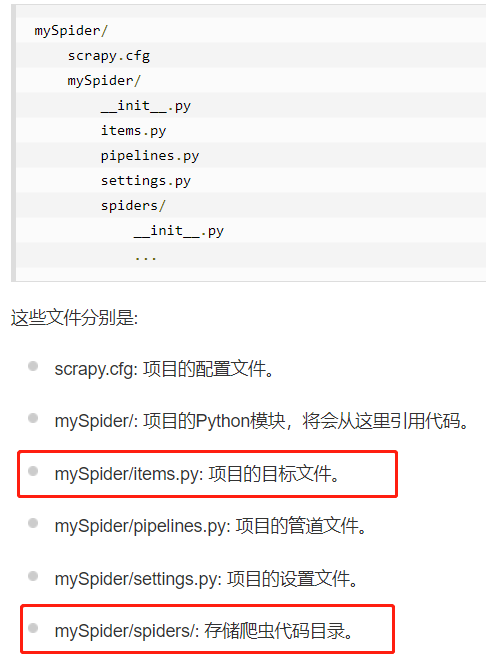
入门教程笔记:
# 创建mySpider
scrapy startproject mySpider # 创建itcast.py
cd C:\Users\theDataDiggers\mySpider\mySpider\spiders
scrapy genspider itcast "itcast.cn" # itcast(itcast.py name)---ItcastSpider(类名)
#该类有3个强制的属性,和一个解析的方法(属性为name allowed_domains start_urls) # 执行itcast.py
scrapy crawl itcast
scrapy crawl itcast -o teachers.csv #在没有学习scrapy时,我们是先请求数据,然后返回数据的
response=request.get(url)
soup=BeautifulSoup(response.text,'lxml')
soup.select() #学习了Scrapy后,发现
def parse(self,response):
#自带response,你可以进行以下操作
response.body()
response.xpath() #顺便还复习了一下类的继承
class ItcastSpider(scrapy.Spider):
class ItcastItem(scrapy.Item):
class MyspiderPipeline(object): #还有引用其它Python文件的类
from mySpider.items import ItcastItem
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
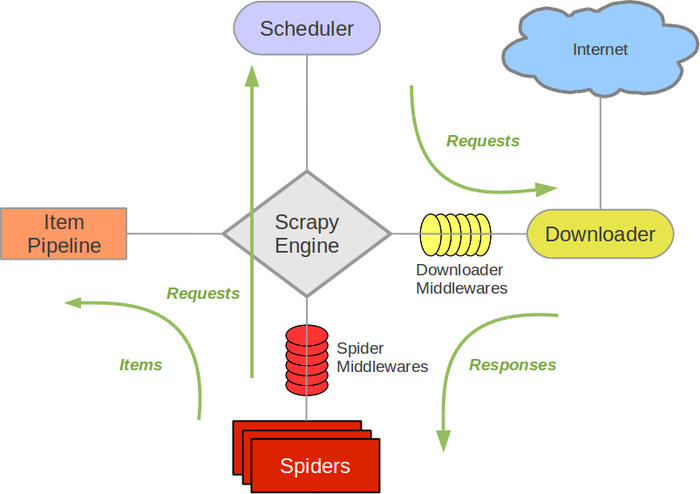
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2019-03-22 Python Scrapy 入门教程 笔记的更多相关文章
- [转]Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider 作者:http://www.cnblogs.com/txw1958/ 出处:http://www.cnblogs.com/txw1958/archi ...
- Scrapy入门教程
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Scrapy入门教程(转)
关键字:scrapy 入门教程 爬虫 Spider作者:http://www.cnblogs.com/txw1958/出处:http://www.cnblogs.com/txw1958/archive ...
- Python基础入门教程
Python基础入门教程 Python基础教程 Python 简介 Python环境搭建 Python 基础语法 Python 变量类型 Python 运算符 Python 条件语句 Python 循 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- 无废话MVC入门教程笔记
自学mvc,看了园子里李林峰写的李林峰写的无废话MVC入门教程笔记,现在有的平时忽略的或是不太清楚的点记下来 1,Html.DropDownList //服务端写法 @{ //下拉列表的值 List& ...
- python之scrapy入门教程
看这篇文章的人,我假设你们都已经学会了python(派森),然后下面的知识都是python的扩展(框架). 在这篇入门教程中,我们假定你已经安装了Scrapy.如果你还没有安装,那么请参考安装指南. ...
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
随机推荐
- Netty、NIO、多线程
一:Netty.NIO.多线程? 时隔很久终于又更新了!之前一直迟迟未动也是因为积累不够,后面比较难下手.过年期间@李林锋hw发布了一个Netty5.0架构剖析和源码解读,看完也是收获不少.前面的文章 ...
- web.xml 中context-param元素
context-param元素含有一对参数名和参数值,用作应用的ServletContext上下文初始化参数.参数名在整个Web应用中必须是惟一的 param-name 子元素包含有参数名,而para ...
- spring boot不同环境读取不同配置
具体做法: 不同环境的配置设置一个配置文件,例如:dev环境下的配置配置在application-dev.properties中:prod环境下的配置配置在application-prod.prope ...
- HDU 4355
只能说感觉是三分吧,因为两端值肯定是最大的,而中间肯定存在一点使之最小,呃,,,,猜 的... #include <iostream> #include <cstdio> #i ...
- HBase读取代码
HBase读取代码 需要的jar包: activation-1.1.jar aopalliance-1.0.jar apacheds-i18n-2.0.0-M15.jar apacheds-kerbe ...
- 在IntelliJ IDEA中创建Maven多模块项目
在IntelliJ IDEA中创建Maven多模块项目 1,创建多模块项目选择File>New>Project 出现New Project窗口左侧导航选择Maven,勾选右侧的Create ...
- [Angular] ngx-formly (AKA angular-formly for Angular latest version)
In our dynamic forms lessons we obviously didn’t account for all the various edge cases you might co ...
- UVA 10196 Morning Walk(欧拉回路)
Problem H Morning Walk Time Limit 3 Seconds Kamalis a Motashotaguy. He has got a new job in Chittago ...
- c10---多文件开发
a.h // // lisi.h // 注意: .h是专门用来被拷贝的, 不会参与编译 #ifndef day05_lisi_h #define day05_lisi_h int sum(int v1 ...
- DB-MySQL:MySQL 序列使用
ylbtech-DB-MySQL:MySQL 序列使用 1.返回顶部 1. MySQL 序列使用 MySQL 序列是一组整数:1, 2, 3, ...,由于一张数据表只能有一个字段自增主键, 如果你想 ...